
Тематическое моделирование с использованием LDA
Тематическое моделирование при обработке естественного языка - это метод, который назначает тему данному корпусу на основе присутствующих слов. Тематическое моделирование важно, потому что в этом мире, полном данных, категоризация документов становится все более важной. Например, компания получает сотни отзывов, тогда компании важно знать, какие категории отзывов важнее, и наоборот.
В этой статье мы увидим следующее:
- LDA
- Гиперпараметры в LDA
- LDA в Python
- Недостатки LDA
- Альтернатива
Темы можно рассматривать как ключевые слова, которые могут описывать документ, например, для темы, спортивной, слова, которые приходят нам в голову: волейбол, баскетбол, теннис, крикет и т. Д. модель темы - это модель, которая может автоматически определять темы на основе слов, встречающихся в документе.
Важно отметить, что тематическое моделирование отличается от тематической классификации. Классификация тем - это обучение с учителем, а моделирование тем - это алгоритм обучения без учителя.
Некоторые из хорошо известных методов тематического моделирования:
- Скрытый семантический анализ (LSA)
- Вероятностный скрытый семантический анализ (PLSA)
- Скрытое распределение Дирихле (LDA)
- Коррелированная тематическая модель (CTM)
В этой статье речь пойдет о LDA.

Скрытое размещение Дирихле
LDA, сокращение от Latent Dirichlet Allocation, - это техника, используемая для тематического моделирования. Во-первых, давайте разберемся с этим словом и поймем, что означает LDA. Скрытое означает скрытое, то, что еще предстоит найти. Дирихле указывает, что модель предполагает, что темы в документах и слова в этих темах соответствуют распределению Дирихле. Распределение означает давать что-то, в данном случае это темы.

LDA предполагает, что документы создаются с использованием процесса статистической генерации, так что каждый документ представляет собой смесь тем, а каждая тема представляет собой смесь слов.
На следующем рисунке документ состоит из 10 слов, которые можно сгруппировать в 3 разные темы, и у этих трех тем есть свои собственные описательные слова.
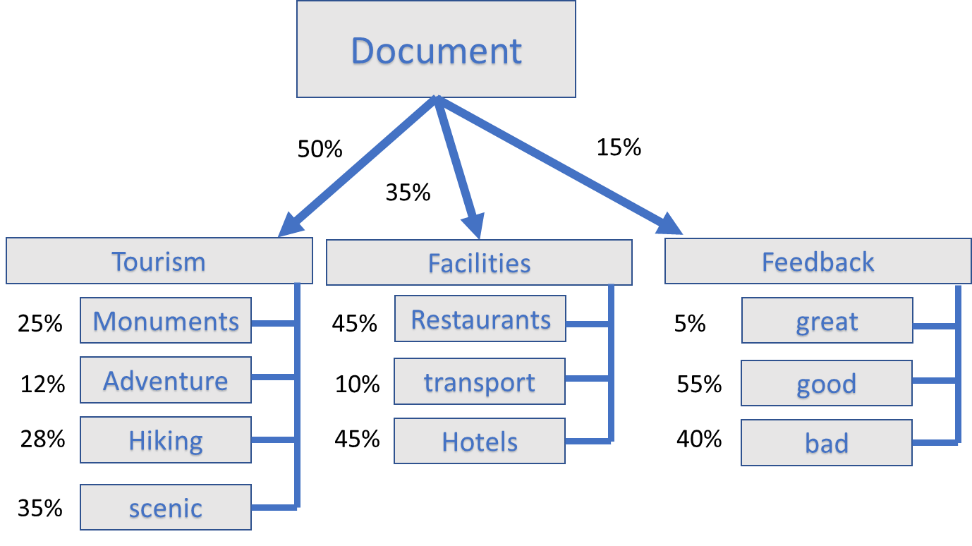
Общие шаги в LDA следующие
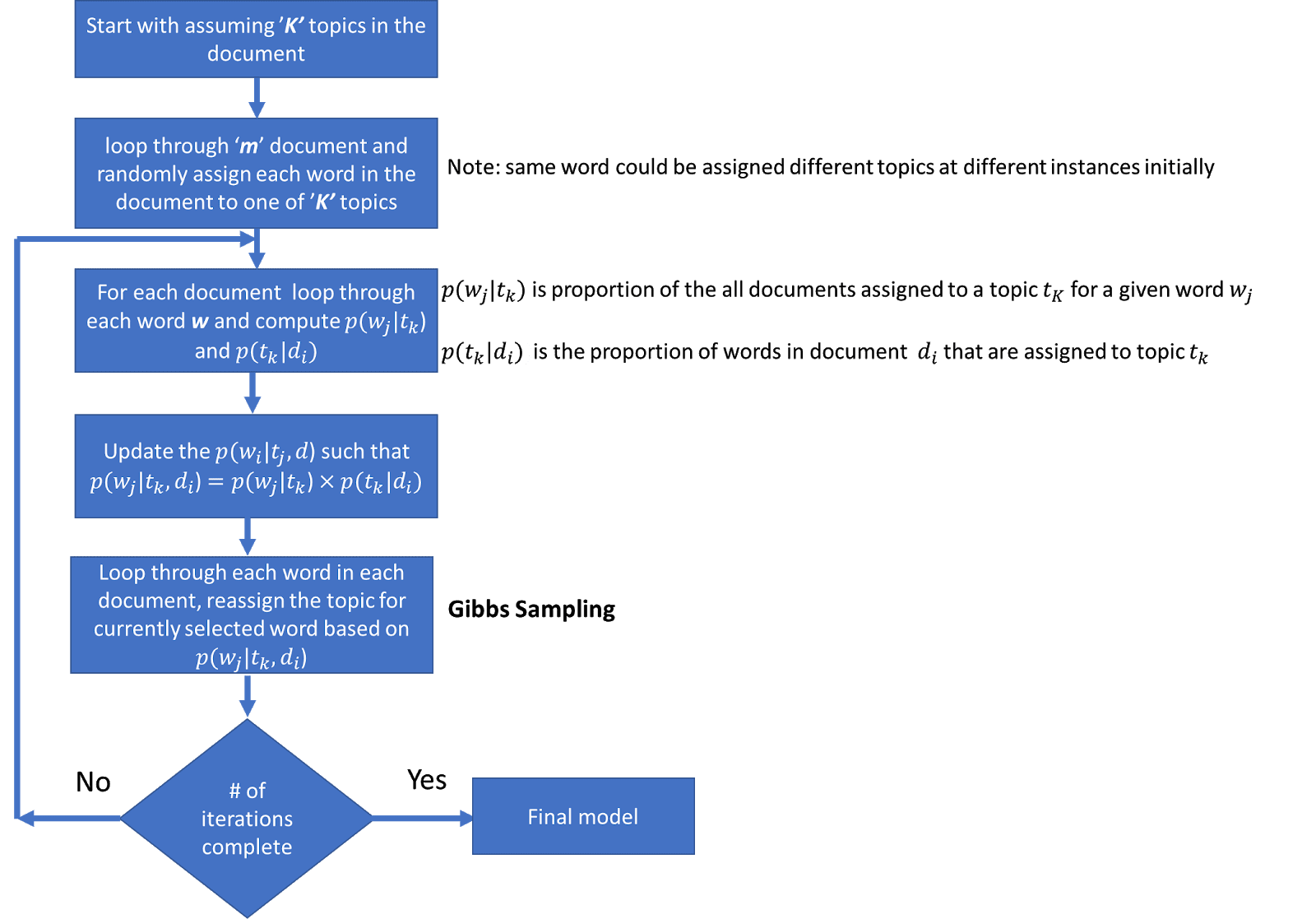
Гиперпараметры в LDA
В LDA есть три гиперпараметра
- α → коэффициент плотности документа
- β → коэффициент плотности тематического слова
- K → количество выбранных тем
Гиперпараметр α определяет количество ожидаемых тем в документе. Гиперпараметр β контролирует распределение слов по темам в документе, а K определяет, сколько тем нам нужно извлечь.
LDA в Python
Давайте посмотрим на реализацию LDA. Постараемся извлечь темы из набора обзоров.
Набор данных, над которым мы будем работать, набор обзоров, который выглядит следующим образом:

Извлечение функций:
Этот шаг не имеет отношения к LDA, пожалуйста, пропустите векторизацию.
Во-первых, мы сделаем извлечение признаков, чтобы получить значимое представление о данных.
Мы извлекли следующие особенности
- Количество слов в документе
- Количество знаков в документе
- Средняя длина документа в слове
- Количество присутствующих стоп-слов
- Количество цифровых символов
- Количество символов верхнего счета
- Чувство полярности
Очистка и предварительная обработка данных:
При очистке и предварительной обработке данных мы сделали следующее
- Все символы переведены в нижний регистр
- Расширены короткие формы, например Я → Я
- Убраны спецсимволы
- Удалены лишние и конечные пробелы
- Удалены символы с диакритическими знаками и заменены их альтернативными
- Лемматизировал слова
- Удалены стоп-слова
Векторизация:
Поскольку LDA имеет встроенный векторизатор TF-IDF, нам придется использовать векторизатор Count.
Скрытое размещение Дирихле:
В этом примере нам задано количество тем, поэтому нам не нужно настраивать гиперпараметр k, но в случаях, когда мы не знаем, сколько тем есть, мы можем использовать поиск по сетке.
Это можно сделать следующим образом
Поиск по сетке выглядит следующим образом
Мотивация для нашей модели следующая:
- Поскольку нам известно количество тем, мы будем использовать скрытое распределение Дирихле с количеством тем 12.
- Нам также не нужно будет сравнивать разные модели, чтобы получить наилучшее количество тем.
- Мы будем использовать random_state, чтобы результаты можно было воспроизвести
- Мы подгоним модель к векторизованным данным и трансформируем ее на том же самом
- После подбора модели мы напечатаем 10 самых популярных слов по каждой теме.
- После получения тем мы создадим новый столбец и назначим тему
Назначения по темам:
Чтобы назначить темы, мы можем сделать следующее:
- Смотрите облака слов по каждой теме
- Посмотреть 10 самых популярных слов
- Ищите KERA → Извлечение ключевых слов для отчетов и статей
Чтобы создать облака слов, мы можем просто импортировать библиотеку WordCloud.
Чтобы узнать больше о KERA, по этой ссылке можно сослаться на статью Исследовательский анализ сильно разнородных коллекций документов Майи и др., Находящуюся на arXiv.
Аннотация выглядит следующим образом
Мы представляем эффективную многогранную систему для исследовательского анализа сильно разнородных коллекций документов. Наша система основана на интеллектуальной пометке отдельных документов в полностью автоматизированном режиме и использовании этих тегов в мощной многогранной структуре просмотра. Используемые стратегии тегирования включают как неконтролируемые, так и контролируемые подходы, основанные на машинном обучении и обработке естественного языка. В качестве одной из наших ключевых стратегий тегирования мы представляем алгоритм KERA (извлечение ключевых слов для отчетов и статей). KERA извлекает тематические репрезентативные термины из отдельных документов совершенно неконтролируемым образом и оказывается значительно более эффективным, чем современные методы. Наконец, мы оцениваем нашу систему с точки зрения ее способности помогать пользователям находить документы, относящиеся к критически важным военным технологиям, похороненным глубоко в большом разнородном море информации.
Проблемы в модели:
- Нам пришлось назначить темы с предоставленными темами вручную, что могло вызвать ошибки.
- Не удалось проверить правильность назначенных тем
- Назначается только одна тема, хотя в идеале она должна зависеть от того, что лучше всего подходит.
- В некоторых документах все темы имеют одинаковую вероятность, что вызовет проблемы, поскольку мы выбираем только макс.
- Некоторые слова не имеют отношения к теме, например скидка, изменение даты
Недостатки LDA:
- LDA плохо работает с мелкими текстами; большая часть наших данных была короткой.
- Поскольку обзоры неоднозначны, LDA становится все труднее
определять темы - Поскольку обзоры в основном основаны на контексте, модели, основанные на
совпадении слов, не работают.
Альтернатива:
Мы можем использовать BERT, чтобы лучше моделировать темы, которые будут рассмотрены в будущем :)
Ресурсы:
- Выбор правильного количества тем для моделирования тем в scikit-learn | Наука о данных для журналистики (vestigate.ai)
- Выявление контекстной темы. Выявление значимых тем для… | Стив Шао | Insight (insightdatascience.com)
- Sklearn.decomposition.LatentDirichletAllocation - документация scikit-learn 0.24.2
- Https://www.youtube.com/watch?v=T05t-SqKArY
- Обработка естественного языка с помощью Python и NLTK стр.1 Токенизация слов и предложений - YouTube
- NLP Tutorial 13 - Полная обработка текста | Конец до конца Учебное пособие по НЛП | НЛП для всех | KGP Talkie - YouTube
- «Организация проектов машинного обучения: руководство по управлению проектами | Гидеон Мендельс | Comet.ml | Середина"
- и многочисленные вопросы о переполнении стека.
Спасибо за чтение :)
