СТАТЬЯ
Предвосхищение вашего оппонента с помощью Minimax Search
Из книги Макса Пумперлы и Кевина Фергюсона Глубокое обучение и игра в го
___________________________________________________________________
Скидка 37 % на Глубокое обучение и игра в го. Просто введите fccpumperla в поле кода скидки при оформлении заказа на manning.com.
________________________________________________________________________________
В этой статье показано, как использовать минимаксный алгоритм, чтобы помочь вашему игровому боту решить, что делать дальше.
Как мы можем запрограммировать компьютер, чтобы решить, какой ход сделать следующим в игре? Для начала мы можем подумать о том, как люди приняли бы такое же решение. Начнем с простейшей детерминированной игры с идеальной информацией: крестики-нолики. Техническое название стратегии, которую мы опишем, — минимаксирование. «Минимаксирование» — это сокращение от «минимизации и максимизации»: вы пытаетесь максимизировать свой счет, в то время как ваш противник пытается минимизировать ваш счет. Алгоритм можно описать одним предложением: предположим, что ваш оппонент так же умен, как и вы. Давайте посмотрим, как минимаксирование работает на практике.

Взгляните на рисунок 1. Какой следующий ход должен сделать X? Здесь нет никакой хитрости; взяв нижний правый угол, вы выигрываете игру. Мы можем превратить это в общее правило: делайте любой ход, который немедленно выиграет игру. Этот план не может пойти не так. Мы могли бы реализовать это правило в коде примерно так:
def find_winning_move(game_state, next_player):
for candidate_move in game_state.legal_moves(next_player): ❶
next_state = game_state.apply_move(candidate_move) ❷
if next_state.is_over() and next_state.winner == next_player:
return candidate_move ❸
return None ❹
❶ Перебрать все допустимые ходы
❷ Рассчитывает, как будет выглядеть доска, если мы выберем этот ход.
❸ Это выигрышный ход! Нет необходимости продолжать поиск
❹ Не могу выиграть на этом ходу
Рисунок 2 иллюстрирует гипотетические позиции на доске, которые будет исследовать эта функция. Эта структура, в которой позиция на доске указывает на возможные последующие действия, называется игровым деревом.

Давайте немного отступим. Как мы оказались в этом положении? Возможно, предыдущая позиция выглядела как цифра 3. Игрок O наивно надеялся сделать три подряд через дно. Но это предполагает, что X будет сотрудничать с планом. Это вытекает из нашего предыдущего правила: не выбирайте ход, который дает противнику выигрышный ход.

def eliminate_losing_moves(game_state, next_player):
opponent = next_player.other()
possible_moves = [] ❶
for candidate_move in game_state.legal_moves(next_player): ❷
next_state = game_state.apply_move(candidate_move) ❸
opponent_winning_move = find_winning_move(next_state, opponent)❹
if opponent_winning_move is None: ❹
possible_moves.append(candidate_move) ❹
return possible_moves
❶ возможных_ходов станет списком всех ходов, заслуживающих внимания
❷ Зацикливается на всех допустимых ходах.
❸ Рассчитывает, как будет выглядеть доска, если мы сыграем этот ход
❹ Дает ли это нашему противнику выигрышный ход? Если нет, то этот ход правдоподобен

Теперь мы знаем, что должны помешать нашему противнику занять выигрышную позицию. Поэтому мы должны предположить, что наш противник собирается сделать то же самое с нами. Имея это в виду, как мы можем играть, чтобы победить? Взгляните на доску на рисунке 4. Если мы играем в центре, у нас есть два способа завершить три в ряд: вверху посередине или внизу справа. Противник не может заблокировать их обоих. Мы можем описать этот общий принцип так: ищите ход, в котором наш противник не может заблокировать создание выигрышного хода. Звучит сложно, но на самом деле легко построить эту логику поверх функций, которые мы уже написали:
def find_two_step_win(game_state, next_player):
opponent = next_player.other()
for candidate_move in game_state.legal_moves(next_player): ❶
next_state = game_state.apply_move(candidate_move) ❷
good_responses = eliminate_losing_moves(next_state, opponent) ❸
if not good_responses: ❸
return candidate_move ❸
return None ❹
❶ Перебрать все допустимые ходы
❷ Рассчитывает, как будет выглядеть доска, если мы сыграем этот ход.
❸ У нашего соперника хорошая защита? Если нет, выберите этот ход
❹ Независимо от того, какой ход мы выберем, наш противник может помешать победе
Конечно, наш противник будет предвидеть, что мы попытаемся это сделать, а также попытается заблокировать такую игру. Мы можем начать видеть формирование общей стратегии:
- Во-первых, посмотрим, сможем ли мы выиграть на следующем ходу. Если да, сыграйте этот ход.
- Если нет, посмотрим, сможет ли наш противник выиграть на следующем ходу. Если это так, заблокируйте это.
- Если нет, посмотрим, сможем ли мы добиться победы в два хода. Если это так, сыграйте, чтобы установить это.
- Если нет, то посмотрим, сможет ли наш противник обеспечить выигрыш в два хода следующим своим ходом…
Обратите внимание, что все три наши функции имеют схожую структуру. Каждая функция перебирает все допустимые ходы и проверяет гипотетическую позицию на доске, которую мы получим после того, как сыграем этот ход. Кроме того, каждая функция основывается на предыдущей функции, чтобы имитировать действия нашего оппонента в ответ. Если мы обобщим эту концепцию, мы получим алгоритм, который всегда может определить наилучший возможный ход.
Решение крестиков-ноликов: минимаксный пример
В предыдущем разделе мы рассмотрели, как предвидеть игру вашего противника на один или два хода вперед. Здесь мы покажем, как обобщить эту стратегию, чтобы выбрать идеальные ходы в крестиках-ноликах. Основная идея точно такая же, но нам нужна гибкость, чтобы смотреть в будущее на произвольное количество ходов.
Сначала давайте определим перечисление, представляющее три возможных исхода игры: выигрыш, поражение или ничья. Эти возможности определены относительно конкретного игрока: проигрыш одного игрока — это выигрыш другого.
Листинг 1. Перечисление для представления результата игры.
class GameResult(enum.Enum):
loss = 1
draw = 2
win = 3
Представьте, что у нас есть функция best_result, которая принимает состояние игры и сообщает нам наилучший результат, которого игрок может достичь в этом состоянии. Если бы этот игрок мог гарантировать выигрыш — в любой последовательности, какой бы сложной она ни была, — функция best_result вернула бы GameResult.win. Если бы этот игрок мог добиться ничьей, он вернул бы GameResult.draw. В противном случае он вернет GameResult.loss. Если предположить, что функция уже существует, то легко написать функцию для выбора хода: мы перебираем все возможные ходы, вызываем best_result и выбираем ход, который приводит к наилучшему для нас результату. Конечно, может быть несколько ходов, которые приведут к одинаковым результатам; в этом случае мы можем просто выбрать из них случайным образом. В листинге 2 показано, как это реализовать.
Листинг 2. Игровой агент, реализующий минимаксный поиск.
class MinimaxAgent(Agent):
def select_move(self, game_state):
winning_moves = []
draw_moves = []
losing_moves = []
for possible_move in game_state.legal_moves(): ❶
next_state = game_state.apply_move(possible_move) ❷
opponent_best_outcome = best_result(next_state) ❸
our_best_outcome = reverse_game_result(opponent_best_outcome) ❸
if our_best_outcome == GameResult.win: ❹
winning_moves.append(possible_move) ❹
elif our_best_outcome == GameResult.draw: ❹
draw_moves.append(possible_move) ❹
else: ❹
losing_moves.append(possible_move) ❹
if winning_moves: ❺
return random.choice(winning_moves) ❺
if draw_moves: ❺
return random.choice(draw_moves) ❺
return random.choice(losing_moves) ❺
❶ Повторяет все допустимые ходы
❷ Вычисляет состояние игры, если мы выбираем этот ход
❸ Поскольку наш противник играет следующим, определите его наилучший возможный исход оттуда. Наш результат противоположен этому
❹ Классифицирует этот ход в соответствии с его результатом
❺ Выбирает ход, ведущий к лучшему результату
Теперь вопрос, как реализовать best_result. Как и в предыдущем разделе, мы можем начать с конца игры и двигаться в обратном направлении. В листинге 3 показан простой случай: если игра уже окончена, возможен только один результат. Просто возвращаем.
Листинг 3. Первый шаг алгоритма минимаксного поиска. Если игра уже окончена, мы уже знаем результат.
def best_result(game_state):
"""Find the best result that next_player can get from this game
state.
Returns:
GameResult.win if next_player can guarantee a win
GameResult.draw if next_player can guarantee a draw
GameResult.loss if, no matter what next_player chooses, the
opponent can still force a win
"""
if game_state.is_over():
if game_state.winner() == game_state.next_player:
return GameResult.win
elif game_state.winner() is None:
return GameResult.draw
else:
return GameResult.loss
Если мы находимся где-то в середине игры, нам нужно искать дальше. К этому моменту узор должен быть вам знаком. Мы начинаем с перебора всех возможных ходов и вычисления следующего состояния игры. Тогда мы должны предположить, что наш противник сделает все возможное, чтобы противостоять нашему гипотетическому ходу. Для этого мы можем просто вызвать best_result из этой новой позиции. Это говорит нам о том, какой результат наш оппонент может получить из новой позиции; мы инвертируем его, чтобы узнать наш результат. Из всех рассматриваемых нами ходов мы выбираем тот, который приводит к наилучшему для нас результату. В листинге 4 показано, как реализовать эту логику, которая составляет вторую половину best_result. На рис. 5 показаны положения доски, которые эта функция будет учитывать для конкретной доски для игры в крестики-нолики.
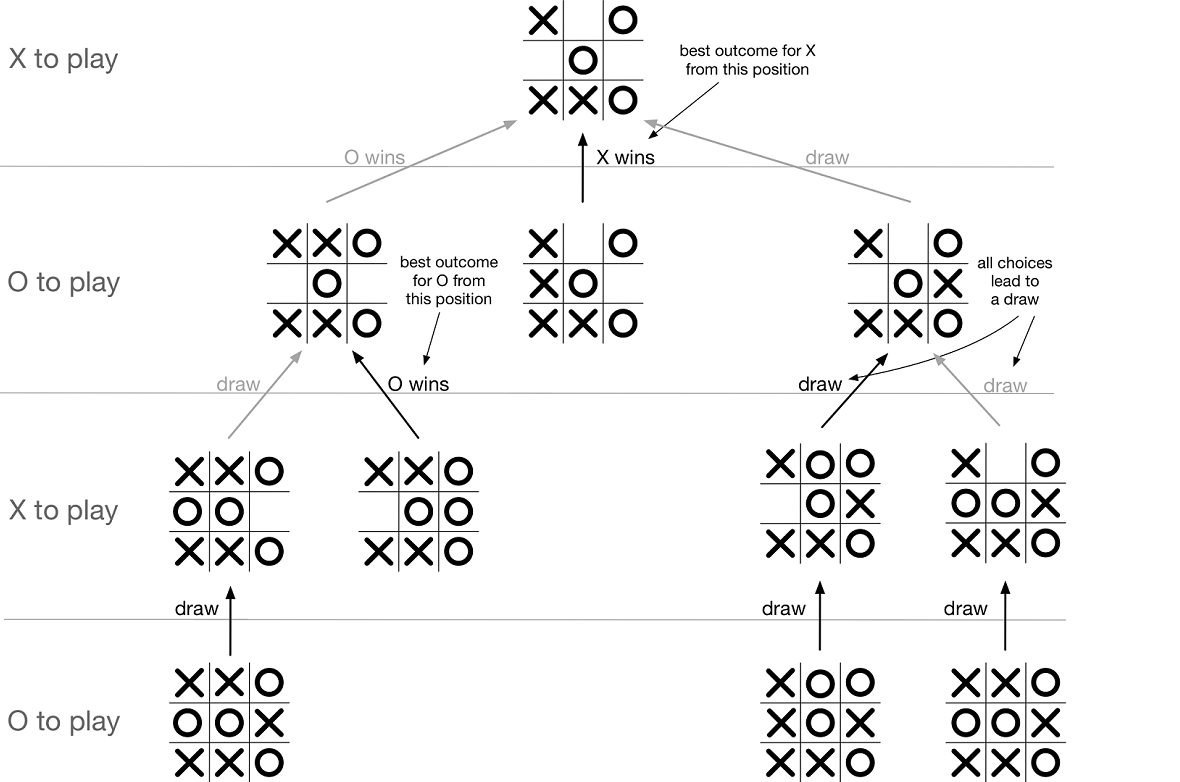
Листинг 4.4. Реализация минимаксного поиска.
best_result_so_far = GameResult.loss
opponent = game_state.next_player.other
for candidate_move in game_state.legal_moves(): ❶
next_state = game_state.apply_move(candidate_move) ❷
opponent_best_result = best_result(next_state) ❸
our_result = reverse_game_result(opponent_best_result) ❹
if our_result.value > best_result_so_far.value:
best_result_so_far = our_result
return best_result_so_far
❶ Посмотрите, как будет выглядеть доска, если мы сыграем этот ход.
❷ Узнайте лучший ход нашего противника.
❸ Чего бы ни хотел наш противник, мы хотим противоположного.
❹ Посмотрите, лучше ли этот результат, чем лучший, который мы видели до сих пор.
Если мы применим этот алгоритм к простой игре, такой как крестики-нолики, мы получим непобедимого противника. Вы можете поиграть против него и убедиться сами: попробуйте play_ttt.py пример на GitHub (https://github.com/maxpumperla/deep_learning_and_the_game_of_go). Теоретически этот алгоритм также будет работать в шахматах, го или любой другой детерминированной игре с идеальной информацией. На самом деле, это слишком медленно для любой из этих игр.
Это все на данный момент. Если вы хотите узнать больше о книге, загляните на liveBook здесь и посмотрите эту презентацию.
Об авторах:
Макс Пумперла и Кевин Фергюсон — опытные специалисты по глубокому обучению, имеющие опыт работы с распределенными системами и наукой о данных. Вместе Макс и Кевин создали бота с открытым исходным кодом BetaGo.
Первоначально опубликовано на freecontent.manning.com.