Обновление (2 марта 2017 г.): теперь есть рабочий код для идей в этом посте с дополнительными оптимизациями.
В последнее время я глубоко погрузился в литературу по совместному редактированию текста. По сути, существует два противостоящих лагеря: операционная трансформация, которая восходит к системе Grove 1989 года и является основой большинства совместных редакторов сегодня, и гораздо более новый подход бесконфликтных реплицированных типов данных (CRDT). Однако я пришел к выводу, что существует общая теория, объединяющая по крайней мере подкласс ОТ и CRDT. Я считаю, что этим двум лагерям есть чему поучиться друг у друга.
Так называемое свойство транзакции 2 (TP2) - это что-то вроде неисправности, проходящей через литературу по ОТ. Знаменательная статья 1996 года, опубликованная Ressel et al, представила это свойство, доказала, что это необходимо и достаточно для правильности их системы, а затем приступила к предложению набора операций для редактирования строк, которые, задним числом, не удовлетворяли TP2. Ой. Примерно десять лет TP2 был чем-то вроде философского камня, причем несколько алхимиков из ОТ утверждали, что они нашли набор преобразований, удовлетворяющих TP2, только для того, чтобы контрпримеры всплыли позже. Только с публикацией в 2006 году Функции преобразования надгробных камней действительно удалось найти золото, но за это пришлось заплатить; вместо того, чтобы выполнять операции вставки и удаления непосредственно в строке, как в исходном видении OT, состояние документа дополняется надгробными плитами, которые записывают места, где может произойти удаление. Отдельная функция чтения требуется для стирания надгробий и получения видимой для пользователя строки.
Между прочим, авторы надгробной памятки в то же время работали над WOOT (Без оперативной трансформации), которая сейчас рассматривается как ранний экземпляр CRDT. Подход CRDT использует простую функцию слияния, в основном обобщение объединения множеств (более формально, монотонные операции над полурешеткой, которая имеет коммутативный, ассоциативный и идемпотентный оператор соединения) и даже более сложная функция чтения для восстановления строки из состояния документа. Тем не менее, это привлекательно, потому что простая функция слияния означает, что очень легко рассуждать о сходимости.
Практически во всех практических реализациях OT отсутствует TP2, и проблема решается путем ограничения параллелизма тем или иным способом, обычно требуя, чтобы центральный сервер принял решение о каноническом порядке операций (но все еще использовал преобразования, чтобы позволить клиентам применять операции вне очереди просто немного). Фактически, практическое ОТ сегодня прочно основано на системе Юпитер 1995 года, при этом примерно 21 год академической работы практически не имеет никакого влияния. Я должен упомянуть здесь Google Wave, который еще больше ограничивает параллелизм (разрешая только одну операцию от каждого клиента в полете). Этот подход упрощает создание серверов, но по-прежнему имеет в основном ту же модель параллелизма и работы, что и Jupiter. Jupiter и Wave основаны на строгой модели параллелизма сериализации, в то время как CRDT и OT с TP2 в конечном итоге согласованы. Хороший документ - Спецификация и сложность совместного редактирования текста, который также характеризует первый как удовлетворяющий спецификации слабого списка, а последний удовлетворяет сильному аналог.
Внедрение TP2 устраняет необходимость в центральном сервере, позволяет создавать одноранговые конфигурации и может уменьшить задержку (включая устранение необходимости в «пакетировании» операций в стиле Wave). Реализовать ОТ с TP2 можно достаточно просто и эффективно, но этот факт, похоже, не особо ценится в устной традиции людей, фактически создающих системы ОТ. Я хотел бы попытаться это немного изменить.
Система OT, удовлетворяющая TP2, имеет свойства, очень похожие на редактирование текста на основе CRDT. Я утверждаю, что это не совпадение, что в основе обоих лежит единая теория.
Я попытаюсь объяснить идеализированную систему ОТ, основанную на GOTO (оптимизированная общая операционная трансформация) и SOCT2 (Сериализация параллельных операций с транспонированием). Это обязательно будет обзор высокого уровня, и для полного понимания читатели будут направлены к этим статьям (с большим сочувствием с моей стороны, литература ОТ в целом сложна).
Эта система OT представляет состояние документа в виде журнала, который представляет собой последовательность операций. Ключ к OT состоит в том, что каждая операция имеет контекст, в основном набор операций, предшествующих ей в журнале, и эти контексты всегда совпадают. При слиянии операции из состояния документа другого узла контекст в целом не будет совпадать, поэтому операцию необходимо преобразовать. Стандартное обозначение для этого - IT (Oa, Ob), где Oa и Ob имеют тот же контекст, что дает преобразованный O'a. Эта преобразованная операция дополнительно содержит Ob в своем контексте, но делает то же самое, что и исходная Oa. В этом обозначении ИТ означает «Преобразование включения». Ранние системы OT использовали только ИТ, но этот подход требует сохранения исходных преобразований, некоторого явного представления контекста и большого количества манипуляций.
Преобразование операций изменяет их контекст, но также имеет смысл отслеживать их исходный контекст (т. Е. Не затронутый преобразованием). Когда одна операция появляется в исходном контексте второй, мы говорим, что вторая причинно зависит от первой. Когда ни один из них не появляется в другом, мы говорим, что они параллельны.
SOCT2 и GOTO используют второе преобразование, часто обозначаемое как ET (Exclusion Transform. Это, по сути, обратное IT), и удаляет одну операцию из контекста операции. Я предпочитаю транспонировать (Oa, Ob), где контекст of Ob - это Oa плюс Oa, что дает O'b и O'a, в которых контекстное отношение меняется на противоположное. Контекст O'a - это контекст O'b плюс O'b. Вы можете написать транспонирование в терминах ET: транспонировать (Oa, Ob) = [ET (Ob, Oa), IT (Oa, ET (Ob, Oa))].
Идея этих двух алгоритмов заключается в том, что выполнение транспонирования не влияет на семантику журнала истории в целом. Кроме того, вам не нужны исходные операции, поэтому их можно выполнять проще и эффективнее. Правильность этих алгоритмов зависит от того факта, что вы выполняете транспонирование только для параллельных операций, то есть все перестановки соблюдают частичный порядок исходного контекста. Конечно, доказать это непросто. Честно говоря, я не совсем понимал доказательства в этих статьях и не верил, что это правда, пока не провел автоматизированное рандомизированное тестирование своей собственной реализации.
Также важно отметить, что для работы всего этого требуется свойство TP2. В противном случае вы обнаружите, что хотя транспонирование не влияет на документ, оно влияет на то, как операция преобразуется посредством последовательности других операций. TP2 дает вам именно ту гарантию, в которой вы нуждаетесь: до тех пор, пока две операции выполняются одновременно по отношению к их исходному контексту, транспонирование в основном ничего не меняет; нет возможности заметить разницу.
Я расскажу немного подробнее. Рассмотрим одноранговую модель, в которой каждый узел имеет свою собственную копию состояния документа. Каждый одноранговый узел постоянно отправляет обновления всем своим соседям (топология может быть любой, от звезды до связующего дерева и до полного графа). Предполагается, что связь в порядке, но, конечно, возможны непредсказуемые задержки (по сути, та же модель связи TCP / IP и WebSockets). Для упрощения считается, что обновление добавляет одну операцию к модели документа узла.
Когда узел получает обновление от другого узла, он уже получил все предыдущие обновления (благодаря упорядоченному характеру канала связи) и объединил их в свое собственное состояние документа. Его состояние документа содержит все операции состояния документа другого узла, а также дополнительные операции, которые другой узел (еще) не видел на момент отправки обновления. Если по счастливому совпадению эти операции сгруппированы так, что все операции во втором наборе идут после операций в первом, выполнить преобразования легко, просто выполните ИТ-преобразование новой операции через каждую из этих операций по порядку. На этом рисунке это показано графически:
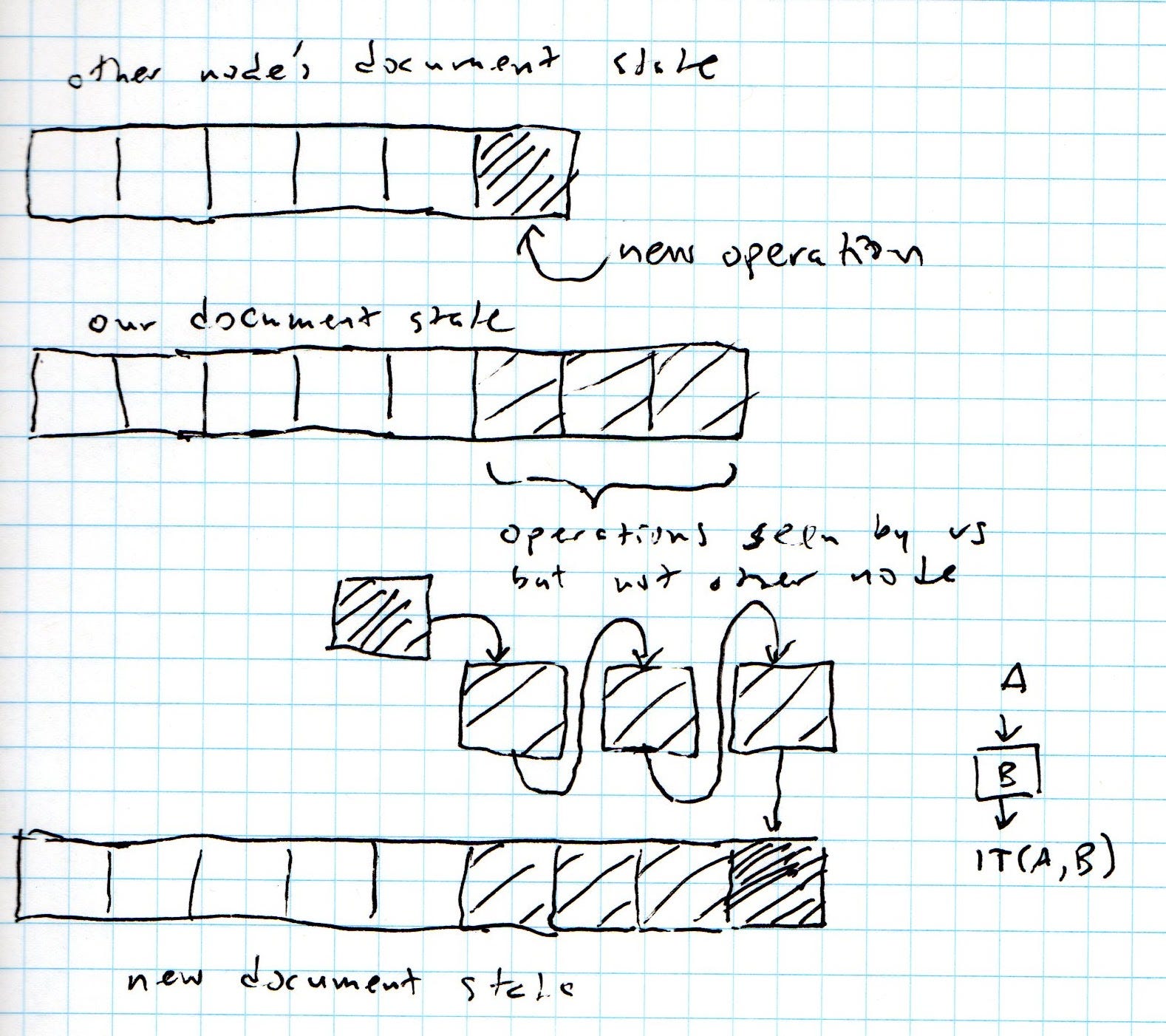
Здесь белые квадраты представляют собой операции, общие для обоих состояний документа. Три светлых квадрата - это дополнительные операции, которые другой узел не заметил. Темный заштрихованный квадрат - это новая операция удаленного узла, которую мы хотим интегрировать. Как указано выше, мы просто запускаем эту новую операцию посредством ИТ-преобразования трех имеющихся у нас операций, чего не делает другой узел. Если вы следуете статье GOTO, последовательное применение ИТ-преобразований - это функция LIT, а изображение выше соответствует случаю 2 в их алгоритме 2.
Вышеупомянутый случай представляет собой случай, когда эти операции, закрашенные светом, сгруппированы вместе. Обратите внимание, что это может быть применено, когда одновременно работают только два пользователя (в основном это тот случай, когда исходная система Grove работала правильно). Ситуация усложняется, когда их трое или больше. Основная идея GOTO и SOCT2 состоит в том, чтобы переставить журнал истории, используя операции транспонирования, как определено выше, для создания кластеризации. Без подробного описания алгоритма (см. Документы) следующий рисунок должен дать хорошее представление о том, что происходит.
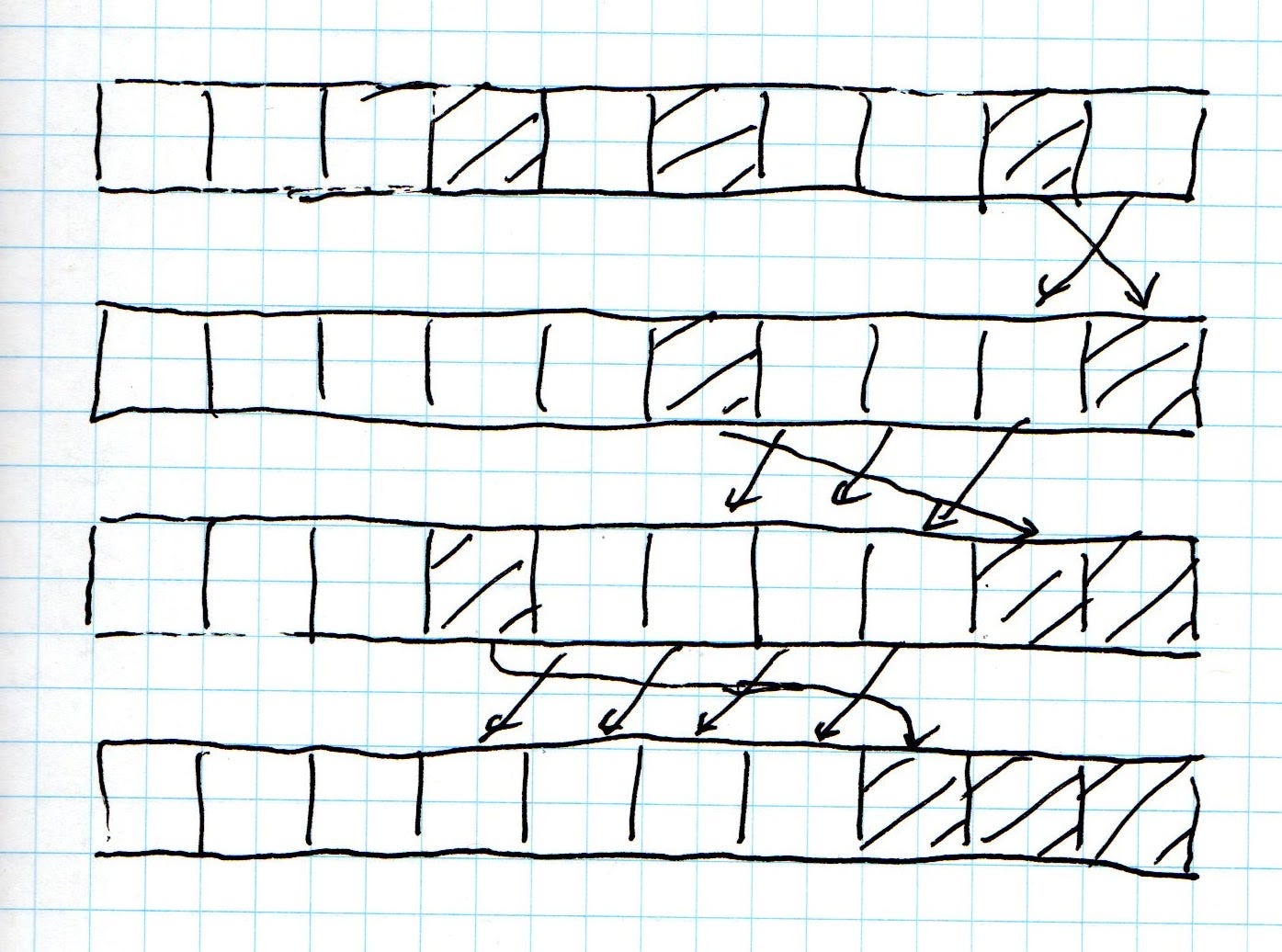
Здесь каждая точка пересечения двух стрелок - это операция транспонирования. Если вы следуете вместе с статьей GOTO, каждая строка на приведенном выше рисунке соответствует одному вызову их функции LTranspose, а изображение выше соответствует случаю 3a в их алгоритме 2.
Я думаю, что концепция транспонирования и перестановки является ключом к анализу этих алгоритмов ОТ в рамках CRDT. Определите отношение эквивалентности: два состояния документа эквивалентны, если одно является перестановкой другого и все операции обмена, составляющие перестановку, соблюдают частичный порядок, индуцированный исходным контекстом. При этом отношении эквивалентности операция слияния двух состояний документа удовлетворяет свойству полурешетки, требуемому CRDT; слияние коммутативно, ассоциативно и идемпотентно. Доказательство этого формально является упражнением для читателя, но в основном оно следует из доказательств правильности GOTO и SOCT2 (опять же, читатель испытывает мои глубочайшие соболезнования).
Здесь есть одна маленькая ловкость рук. Вышеупомянутое отношение эквивалентности определено для математических объектов, в которых каждая операция содержит свой исходный контекст. Допустим, у вас есть два состояния документа, в которых один пользователь ввел «а», а другой - «б». Если эти операции выполняются одновременно, то в документе говорится, что [Oa, O’b] и [Ob, O’a] считаются эквивалентными. Однако, если второй пользователь ждет первой операции, то это не так. Алгоритмы GOTO и SOCT2 не переносят эти дополнительные метаданные в состояние документа. Хотя это означает, что им не хватает информации, необходимой для оценки отношения эквивалентности, с практической точки зрения я считаю, что это хорошо. Фактически, я бы сказал, что одна из самых сильных критических замечаний в отношении CRDT заключается в том, что обычно требуется много метаданных для построения структуры дерева или графа, чтобы упростить слияние, которые затем стираются в функции чтения. Для сохранения этого требуется больше оперативной памяти и большая пропускная способность по сравнению с подходами, ориентированными на OT.
Вы можете помахать рукой и сказать, что теоретическая модель GOTO / SOCT2, которая включает в себя метаданные контекста, - это CRDT, и что стирание этих данных - просто деталь реализации, но меня это не устраивает. Если определение отношения эквивалентности включает исходный контекст, то состояние документа алгоритма GOTO / SOCT2 не является CRDT в соответствии с этим определением.
Есть альтернатива, которая лично мне кажется более привлекательной. Вместо того чтобы говорить, что две операции можно транспонировать только в том случае, если они фактически выполнялись одновременно, ослабьте определение. Обычно, если история может быть объяснена двумя параллельными операциями, разрешите обмен. В приведенном выше примере предположим, что правила разрешения конфликтов помещают правки пользователя A перед редактированием пользователя B при одновременной вставке. Таким образом, одновременно введенные «a» и «b» приводят к «ab». Разрешить замену «ab» независимо от того, были ли операции на самом деле параллельными или нет, поскольку нет никакой разницы в наблюдаемом состоянии. Не существует двух одновременных операций, которые могут дать «ba», так что эта пара все равно не будет заменяться.
Более формально, считайте последовательность [Oa, Ob] транспонируемой тогда и только тогда, когда IT (Oa, O'b) = O'a и IT (O'b, O'a) = Ob, где [O'a, O ' b] = транспонировать (Oa, Ob). В приведенном выше примере «ba» это не удастся, так как Oa и O'b будут одновременно вставлять «a» и «b» в одно и то же место, а правило разрыва связи в ИТ разрешит их в «ab». , а не совпадение.
Поскольку это новое отношение эквивалентности полностью определяется информацией, фактически содержащейся в состоянии документа, операцию слияния GOTO / SOCT2 можно по праву считать CRDT (конечно, при условии отсутствия ошибок правильности).
Кроме того, я бы сказал, что более слабое отношение эквивалентности действительно полезно, а не просто математический трюк. Например, вы можете изменить состояние документа, чтобы он лучше сжимался. Если два пользователя одновременно вводят удаленные части одного и того же документа, то исходный контекст вызывает почти полный порядок (на самом деле полный порядок, если задержка достаточно высокая), но на самом деле правки одного пользователя могут быть перенесены с правками другой без вреда. Более слабое отношение эквивалентности позволяет это сделать.
А как насчет операционной трансформации, не связанной с TP2? Я подумал о способах втиснуть это в структуру CRDT. В частности, вы можете прикрепить метку времени к каждой операции, а затем использовать функцию чтения для воспроизведения операций в порядке меток времени. На практике, хотя в некотором техническом смысле это может быть CRDT, это действительно плохой вариант. Если вы интегрируете операцию с более ранней меткой времени относительно остальной части вашего буфера, тогда она может принудительно воспроизвести множество операций, что будет медленным и может привести к странным изменениям в документе. В частности, такие ситуации, как головоломки TP2 (см. Рис. 3 надгробной бумаги для подробного объяснения), могут вызвать переупорядочение больших фрагментов текста, что обычно было бы ужасным опытом. Если это ваши функции преобразования, лучше положиться на центральный сервер, который фактически ограничит параллелизм, чтобы этого не произошло.
Таким образом, я утверждаю, что подкласс ОТ, соответствующий TP2, можно рассматривать как образец CRDT, и поэтому лагеря ОТ и CRDT не так далеки друг от друга, как могло показаться на первый взгляд. Лагерь ОТ предлагает эффективные методы реализации, в частности, обучение тому, что сохранение метаданных графовой структуры не является абсолютно необходимым. В свою очередь, лагерь CRDT предлагает более прочную основу для математических рассуждений (послужной список литературы по ОТ, безусловно, демонстрирует, что очень трудно рассуждать о правильности преобразований ОТ) и потенциально богатый набор методов для составления и комбинирования CRDT.
Я надеюсь, что это сообщение в блоге предлагает способы совместной работы сообществ OT и CRDT. Я также рекомендую разработчикам систем совместного редактирования (и академическим исследователям), надеющимся на преимущества CRDT (в частности, одноранговую работу, а не необходимость централизованного сервера), еще раз взглянуть на OT. Тот факт, что в литературе есть так много ошибочных предложений, не является хорошей причиной для списания всего поля в пользу, казалось бы, более зеленых пастбищ CRDT.