Mckinsey & Company указывает на пять узких мест, которые стоят между вашей организацией и достижением победы с помощью ИИ:
- Маркировка данных
- Получение массивных наборов обучающих данных
- Проблема объяснимости
- Обобщаемость обучения
- Предвзятость в данных и алгоритмах
Мы бы добавили еще одно:
- Пробел в навыках ИИ
В Ziff мы считаем, что между вашей организацией и достижением успеха с помощью ИИ должно быть только одно узкое место: получение экспертного понимания.
Пример изображения:
У вас есть данные об изображениях, но вы не знаете их ценности. Чтобы даже узнать, есть ли у вас что-нибудь полезное, нужно подписаться на 6 рисков, связанных с предоставлением ценности ИИ. Вы должны собрать, а затем пометить свои данные чем-то интересным. Если в конце этого процесса вы обнаружите, что в ваших данных нет ничего полезного, вы вернетесь к исходной точке.
Ярлыки:

В этом примере мы берем набор данных людей с открытым исходным кодом 550 000 изображений, но это может быть ваш собственный набор данных любых изображений. Это могут быть изображения людей, документов, продуктов, производственных процессов и т. Д. Обычно большой набор данных без меток (метаданные или результаты, назначенные каждому изображению) бесполезен, и требуются усилия по маркировке.
Маркировка занимает много времени, дорого и часто не запускается, если вы имеете дело с большими объемами конфиденциальных данных. Если вы готовы к краудсорсингу, маркируя свои данные с помощью платформы, подобной Amazon Mechanical Turk, вы, вероятно, можете сократить сроки, но вам следует ожидать, что вы заплатите от 25 000 до 150 000 долларов в течение 1–6 месяцев. Если это ваша первая кураторская работа как организации, это займет больше времени, потому что вы, вероятно, повторите процесс несколько раз, прежде чем у вас все получится. Вы обнаружите, что повторение самого себя - обычная тема в искусственном интеллекте.

Пример рабочего процесса изображения AI
- Собрать все изображения (расчетное время: дни-недели)
- Обозначьте свои данные метаданными (расчетное время: дни-недели): если у вас уже есть метаданные о ваших изображениях, это сэкономит ваше время, но убедитесь вдвойне, что это ярлык, который вам действительно важен - задача искусственного интеллекта Идентифицировать хот-доги - это весело, но дает ли это вам новые возможности или помогает снизить затраты?
- Маркировка краудсорсингом или «Insource» (расчетное время: недели-месяцы): если у вас нет метаданных или информация, которую вы хотите извлечь из изображений, еще не записана, вам необходимо поручить людям маркировать ваши данные и сотрудники Mechanical Turk не являются экспертами в вашей области - это приведет к ошибкам с большим количеством меток.
- Анализ (расчетное время: месяцы): передайте свой набор данных изображений своему эксперту по глубокому обучению или в службу глубокого обучения и попросите их найти алгоритм, который работает с вашими данными.
- Развертывание локально (расчетное время: месяцы): если вы развертываете локальное развертывание, ваша команда DevOps должна будет использовать инструменты для вычислений на графическом процессоре.
- Развертывание в облаке (расчетное время: недели-месяцы): выберите и поставьте «модельный сервер», а также управляйте ресурсами графического процессора и автомасштабированием.
Даже после нескольких месяцев вложений времени и ресурсов вам, вероятно, все равно придется решать проблему более низкого, чем ожидалось, качества данных.
Решение:

В Ziff мы обнаружили, что это обычная проблема для наших клиентов и партнеров, поэтому мы хотели посмотреть, сможем ли мы автоматизировать весь этот процесс. Большинство систематизированных данных о клиентах содержат больше ошибок меток, чем они ожидали, и для клиентов с неструктурированными данными (например, изображения, аудио, видео) без меток эта проблема становится для них бесполезной. Наборы данных о людях могут быть особенно проблематичными из-за объема необходимой предварительной обработки (т. Е. Обнаружения / кадрирования лиц).
В Ziff мы использовали наши возможности глубокого обучения, чтобы автоматизировать процесс обнаружения и помочь человеку, который больше всего заботится о проблеме (вице-президент по продукту, руководитель и т. Д.), В ее решении. Если лица существуют в вашем наборе данных, они предварительно обрабатываются должным образом с использованием расширенных сетей обнаружения для автоматической обрезки.
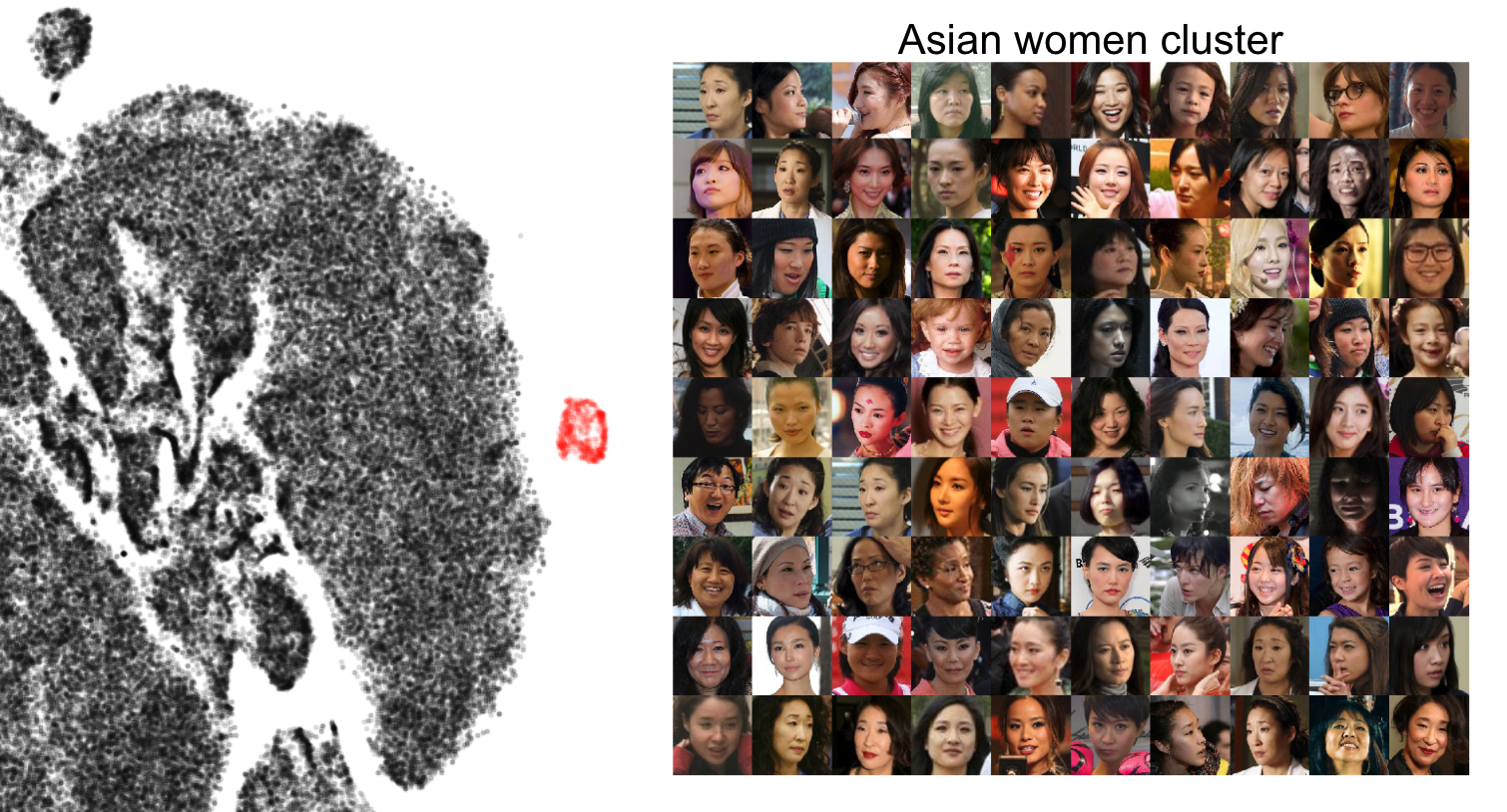
Без человеческого руководства или наставничества наш процесс искусственного интеллекта организует весь набор данных размером 550 тыс. За несколько минут в значимые кластеры для экспертной оценки.

Создаваемые естественные кластеры включают такие вещи, как: пол (мужчина / женщина), раса (азиаты / черные / белые), шляпы, бороды и возраст. Для этого конкретного случая использования возможность обучать модель пола и расы на исходном наборе данных очень полезна, поскольку во многих случаях внешние обучающие наборы отклоняются от набора данных пользователя.
Результаты:
- Индексирование и систематизация 550 000 изображений менее чем за час
- Природные кластеры, идентифицированные ИИ и проверенные опытным пользователем
- 98,9% гендерной классификации достигнуто с использованием автоматических меток AI
- Другие интересные ярлыки включали расу (азиаты / черные / белые), возраст (›40,‹ 40) и аксессуары для лица (борода, шляпы).
Вспомогательное оборудование:
Этот анализ был выполнен на PureStorage FlashBlade и NVIDIA v100s.