
Изображение 1.
Концепция динамических таблиц
Концепция динамических таблиц аналогична материализованному представлению в базе данных. Подобно статическим пакетным таблицам, динамические таблицы позволяют выполнять запросы на языке структурированных запросов (SQL) и формируют новую динамическую таблицу с взаимными преобразованиями без потерь (двойными) между потоками. Ключ к улучшению существующего интерфейса прикладных программ (API) заключается в изменении содержимого таблиц с течением времени. Текущая таблица потоковой передачи может считаться динамической таблицей в режиме добавления динамической таблицы.
Преобразование из потока в динамическую таблицу
Когда поток преобразуется в таблицу, режим преобразования определяет, определен ли в схеме таблицы первичный ключ или нет. Рассмотрим некоторые из этих режимов.
Режим добавления
Если схема таблицы не включает определение ключа, используйте для преобразования режим добавления. Каждая новая запись в потоке добавляется в таблицу как новая строка. Данные не могут быть обновлены или удалены из таблицы после ее добавления (в текущей таблице преобразование в новую таблицу здесь не рассматривается).

Изображение 2.
Заменить режим
Если схема таблицы включает определение ключа, записи с уникальными ключами создают новые записи в таблице. Записи с существующими ключами могут только обновлять записи в таблице, как показано на рисунке ниже.

Изображение 3.
Преобразование из динамической таблицы в поток
Операция таблица-в-поток относится к отправке всех изменений вниз по течению в виде потоков журнала изменений. Для этого шага существует два режима: режим отзыва и режим обновления.
Режим отвода
В режиме отзыва запросы на вставку и удаление в динамическую таблицу генерируют события вставки и исключения соответственно. Если это изменение обновления, впоследствии генерируются два типа событий изменения. Запись удаленного события появляется с тем же ключом, который был отправлен ранее, и для текущей записи генерируется событие вставки, как показано на рисунке ниже.
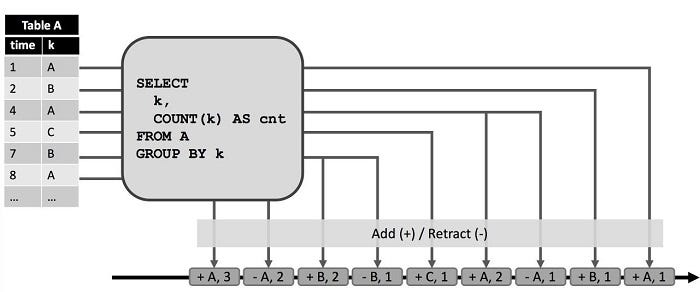
Изображение 4.
Режим обновления
В режиме обновления обновленная схема зависит от динамической таблицы, определяющей ключ. Каждое событие изменения представляет собой пару ключ-значение. Ключ соответствует значению ключа таблицы в текущей записи. Значения вставки и изменения соответствуют новой записи. Если значение удаления пустое, это указывает на удаление ключа, как показано на рисунке ниже.
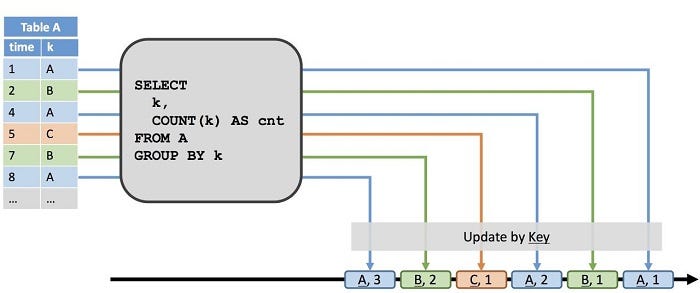
Изображение 5.
Запрос динамических таблиц
Подобно содержимому динамической таблицы, результаты запроса также изменяются со временем. Чтобы лучше понять концепцию динамических таблиц, давайте рассмотрим пример.
Таблица A является динамической таблицей, и ее снимок во время t обозначается как A[t]. Функция q запрашивает снимок в момент времени t и обозначается как q(A[t]).
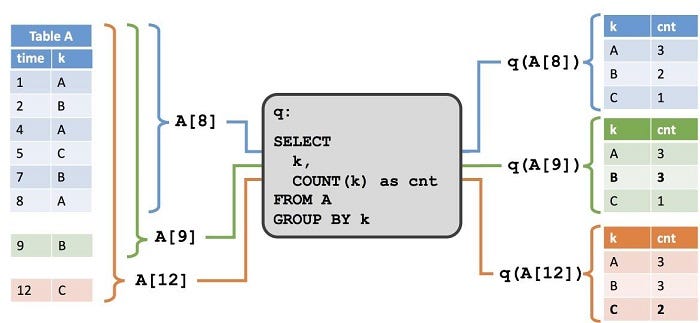
Изображение 6.
Ограничения запросов
Поскольку поток бесконечен, динамическая таблица не ограничена. При запросе к бесконечной таблице необходимо убедиться, что запрос своевременный и осмысленный.
1. На практике Flink преобразует запрос в непрерывное потоковое приложение, а выполняемый запрос применяется только к текущему логическому времени. Поэтому запрос для любого момента времени (A [t]) не поддерживается.
2. Самый интуитивный принцип заключается в том, что возможное состояние запроса и вычислений должно быть ограничено, чтобы Flink поддерживал запросы для добавочных вычислений. Чтобы убедиться в этом, выполните следующие действия:
- Постоянно обновлять запросы текущих результатов: запрос может генерировать вставку, обновление и удаление изменений.
Запрос выражается как Q(t+1) = q'(Q(t), c(T, t, t+1)), где Q(t) обозначает предыдущий результат запроса q, c(T, t, t+1) представляет собой изменение таблицы T с t+1 на t, а q' — это инкрементная версия q. - Создайте таблицу только для добавления и вычислите новые данные непосредственно из конца входной таблицы.
Запрос выражается как Q(t+1) = q''(c(T, tx, t+1)) ∪ Q(t), где q'' – инкрементная версия запроса q из q результата. . Когда время t не требуется, c(T, t-x, t+1) представляет последние x+1 записей данных таблицы T, где x зависит от синтаксиса. Например, для агрегации окон за последний час в качестве состояния требуются как минимум все данные за последний час.
Другие поддерживаемые типы запросов включают в себя:
- SELECT WHERE, который выполняется отдельно для каждой строки
- Предложения GROUP BY для времени строки (например, агрегат окна на основе времени)
- OVER окна (окна-строки) ORDER BY rowtime
- ORDER BY rowtime.
3. Когда входная таблица достаточно мала, можно получить доступ к каждой записи данных в таблице. Например, вы можете соединить две потоковые таблицы фиксированного размера (т. е. с фиксированным количеством ключей).
Ограниченное промежуточное состояние
Как упоминалось выше, некоторые добавочные запросы должны сохранять определенные данные (часть входных данных или промежуточные результаты) в качестве состояния. Чтобы предотвратить сбой запроса, важно убедиться, что пространство, необходимое для запроса, ограничено и не растет бесконечно со временем. Есть две основные причины роста государства:
- Прогресс промежуточного вычислительного состояния за пределами ограничения предиката времени (например, расширение совокупного ключа)
- Время ограничено, но необходимы исторические данные (например, агрегация окон)
Хотя параметр «Смещение последнего результата», упомянутый ниже, может решить второй случай, в первом случае требуется обнаружение оптимизатора. Вы должны отклонять запросы роста промежуточного состояния, которые не имеют временных ограничений. Оптимизатор должен предоставить информацию о том, как исправить запрос и потребовать соответствующий предикат времени. Возьмем, к примеру, следующий запрос:
SELECT user, page, COUNT(page) AS pCnt
FROM pageviews
GROUP BY user, pageС увеличением количества пользователей и количества страниц данные промежуточного состояния со временем увеличиваются. Добавление предиката времени ограничивает требования к объему памяти:
SELECT user, page, COUNT(page) AS pCnt
FROM pageviews
WHERE rowtime BETWEEN now() - INTERVAL '1' HOUR AND now() // only last hour
GROUP BY user, pageПоскольку не все атрибуты продолжают увеличиваться, вы можете сообщить оптимизатору размер домена, чтобы сделать вывод о том, что промежуточное состояние не будет увеличиваться с течением времени, и тогда можно будет принимать запросы без предикатов времени.
val sensorT: Table = sensors .toTable('id, 'loc, 'stime, 'temp) .attributeDomain('loc, Domain.constant) // domain of 'loc is not growing env.registerTable("sensors", sensorT)SELECT loc, AVG(temp) AS avgTemp FROM sensors GROUP BY loc
Расчет результатов и уточнение временной последовательности
Некоторые реляционные операторы должны ждать генерации данных для вычисления результата. Например, если окно закрывается в 10:30, реляционным операторам нужно подождать по крайней мере до 10:30, чтобы вычислить результат. Логические часы Flink (которые определяют время как 10:30) зависят от использования времени события или времени обработки. В случае времени обработки логическим временем являются настенные часы каждой машины. В случае времени события водяной знак, предоставленный источником, определяет логические часы. Из-за беспорядочных данных и задержек данных в режиме времени события Flink необходимо подождать некоторое время, чтобы уменьшить несовершенство результатов расчета. С другой стороны, в определенных случаях вы можете захотеть получить более ранние результаты. Поэтому существуют разные требования к расчету, расширению и доработке результатов.
На следующем рисунке показано, как различные конфигурации параметров используются для управления предварительными результатами и уточнения результатов.
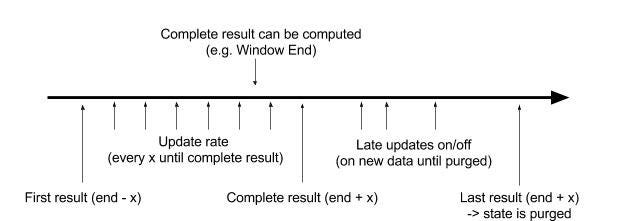
Изображение 7
- «Смещение первого результата» относится к времени расчета первого раннего результата. Время указано относительно времени полного расчета результата (например, относительно времени окончания окна в 10:30). Если задано значение -10 минут, для окна с временем окончания в 10:30 первый отправленный результат вычисляется в логическое время 10:20. Значение по умолчанию для этого параметра равно 0, что означает, что результат вычисляется в конце окна.
- «Полное смещение результата» указывает время, когда завершается расчет полного результата. Время соответствует времени, затраченному на первый полный расчет. Если установлено значение +5 минут, для окна с временем окончания в 10:30 время формирования полного результата равно 10:35. Этот параметр может смягчить влияние задержки данных. Значение по умолчанию равно 0, то есть результат, рассчитанный в конце окна, является полным результатом.
- «Частота обновления» означает временной интервал (который может быть значением времени или количеством раз) для обновления результата перед полным вычислением результата. Рассмотрим случай, когда настройка равна 5 минутам. Для 30-минутного акробатического окна со временем начала 10:30, «Смещение первого результата» -15 минут и «Смещение полного результата» 2 минуты, результат обновляется в 10:20, 10:25 и 10:30. . Результат генерируется в 10:15, а полный результат — в 10:32.
- «Переключатель последних обновлений» означает, вычисляется ли отложенное обновление для задержанных данных после отправки полного результата до очистки состояния расчета.
- «Смещение последнего результата» указывает время последнего вычисления результата. Это время, когда внутреннее состояние очищается и удаляются данные, поступающие после этого времени. Смещение последнего результата означает, что результат расчета является приблизительным значением и его точность не гарантируется.
Вывод:
В этой статье рассматривается тема динамических таблиц. В нем обсуждаются способы преобразования динамических таблиц в поток и важность режимов, используемых при таком преобразовании. В этой статье также рассматриваются шаги, связанные с вычислением результатов для временной последовательности, а также способы оптимизации результатов.