По сценарию Минхуэй Чжана и Чжэ Вана
Проблема сжатия моделей глубокого обучения хорошо известна в машинном обучении. Ключевой момент, стоящий за этим вопросом, заключается в следующем: как мы можем уменьшить размер модели, сохранив при этом возможности модели? BERT, как важная модель в области НЛП, демонстрирует значительное улучшение во многих задачах НЛП. Использование этой большой модели в производственных средах — сложная задача, требующая большого объема вычислений, памяти и энергоресурсов. Таким образом, сжатие BERT действительно необходимо и горячо обсуждается в последние годы.

Большая работа была проделана для решения проблемы сжатия BERT. В этом посте мы сначала представим BERT, а затем обсудим три распространенных и репрезентативных метода сжатия: квантование, дистилляцию и уменьшение глубины.
BERT: предварительное обучение глубоких двунаправленных преобразователей для понимания языка
BERTобозначает Bоднонаправленный Eкодер Rпредставления от Tпреобразователей. Из его названия мы знаем, что, во-первых, он двунаправленный: BERT предварительно обучает данные как из левого, так и из правого контекста, что отличается от предыдущей модели ELMo или GPT, модели которых используют только левый или правый контекст.
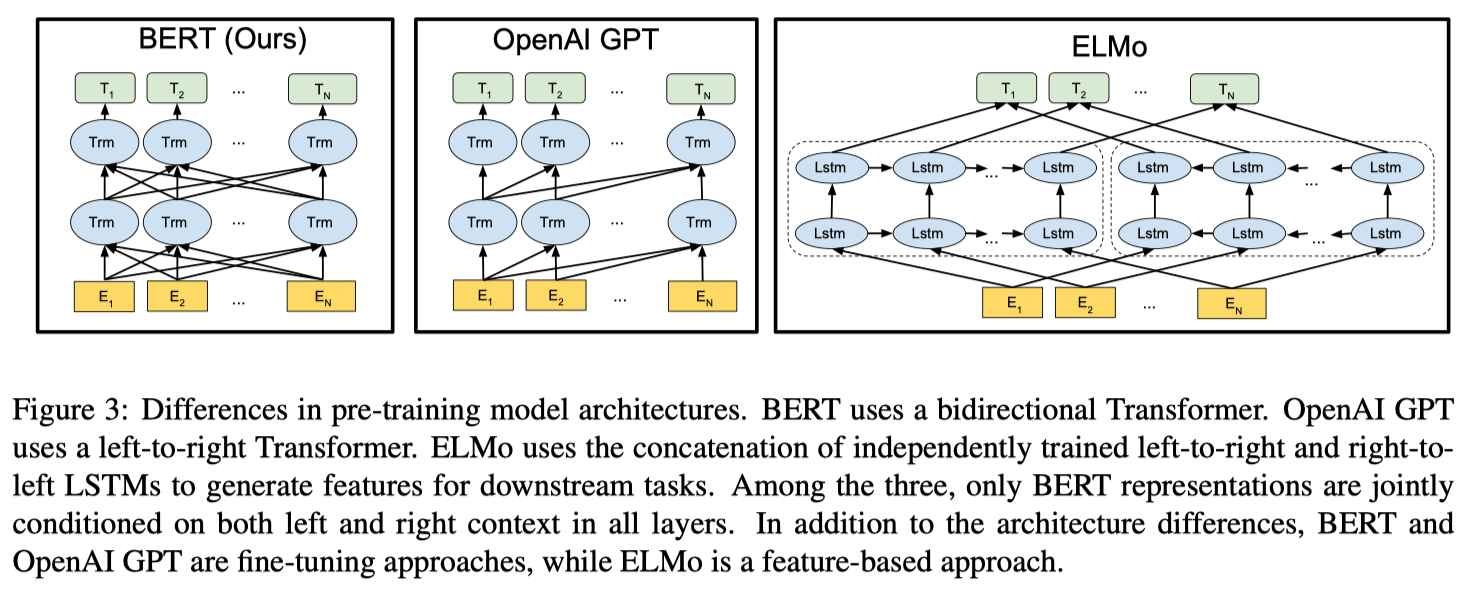
Во-вторых, BERT состоит из энкодеров: его модельная архитектура представляет собой многоуровневый энкодер Transformer. В статье представлены модели двух размеров: BERT BASE с 12 слоями и BERT LARGE с 24 слоями. Именно BERT LARGE добился самых современных результатов.
Что касается процедур,есть два этапа: предварительная подготовка и тонкая настройка. BERT может сначала выполнить предварительное обучение на неразмеченном тексте, а затем выполнить точную настройку с помощью всего лишь одного дополнительного выходного слоя для широкого круга задач, таких как ответы на вопросы и определение языка.
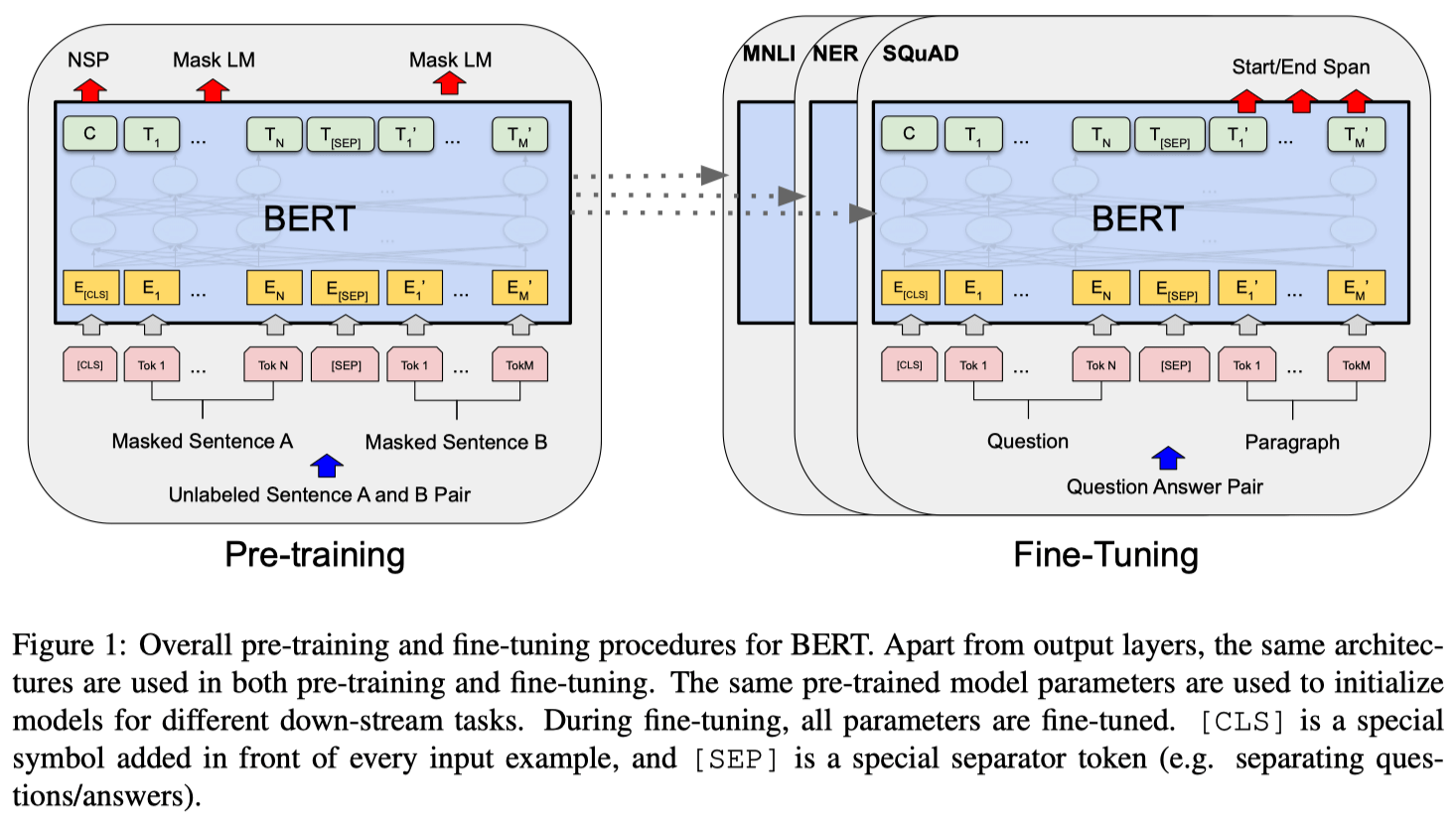
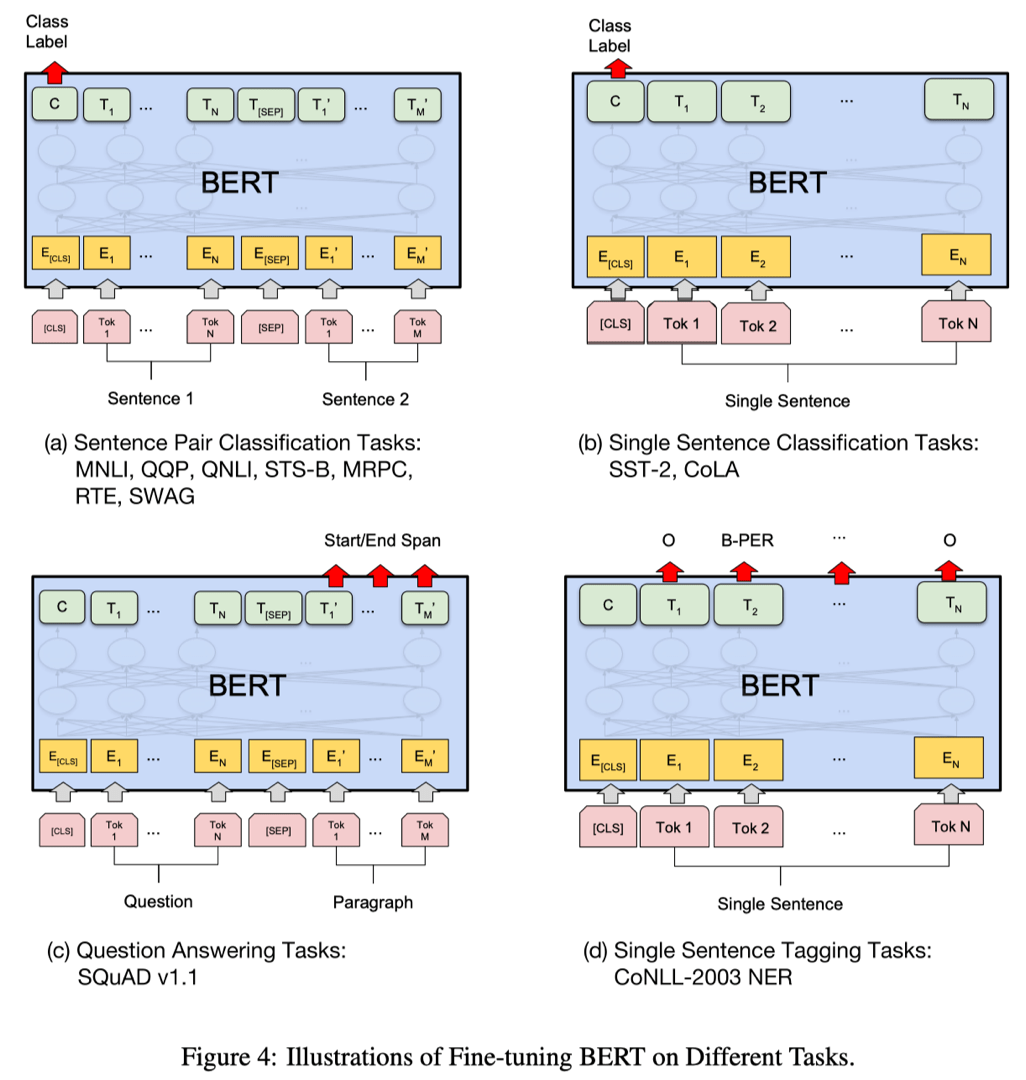
Через минуту мы представим, как реализуются эти два шага. Перед этим давайте посмотрим на ввод BERT.

Из рисунка мы можем узнать 3 вещи:
- Вход BERT = встраивание токена + встраивание сегмента + встраивание позиции
- [CLS] относится к токену классификации
- [SEP] разделяет разные предложения
Хорошо, вернемся к предварительной тренировке. BERT обучается на немаркированных данных с помощью различных задач предварительного обучения, таких как языковая модель в маске и прогнозирование следующего предложения.
Задание перед обучением № 1: Маскированная языковая модель. Маскированный LM означает, что мы случайным образом маскируем некоторые из входных токенов и позволяем модели предсказывать эти маскированные токены. Как сообщается в документе, BERT маскирует 15% всех токенов в каждой последовательности.

Маски позволяют BERT получить двунаправленную предварительно обученную модель. Однако это поднимает новую проблему. Подумайте об этом с другой стороны, подобные маски создадут несоответствие между предварительной подготовкой и тонкой настройкой, поскольку токен [MASK] не появится на более позднем этапе.
Чтобы устранить вышеуказанные проблемы, реальная реализация такова: BERT случайным образом выбирает 15% позиций токена. Если выбран токен, мы заменяем токен токеном [MASK] в 80% случаев:

случайный токен в 10% случаев:

и неизменный токен в 10% случаев.

Почему именно 15%, авторы объяснили в своей презентации «Слишком мало маскировки: слишком дорого обучать. Слишком много маскировки: недостаточно контекста». И 15% это остаток.
Предварительное задание 2. Предсказание следующего предложения. Для выполнения таких задач, как "Ответы на вопросы" (QA) и "Вывод естественного языка" (NLI), требуется модель, позволяющая понять взаимосвязь между двумя предложениями. Однако эта потребность не может быть удовлетворена языковым моделированием. Предсказание следующего предложения используется для изучения взаимосвязей между предложениями и для предсказания того, является ли предложение Б фактическим предложением, которое следует за предложением А, или это просто случайное предложение из ниоткуда.


Последний шаг – тонкая настройка. Мы просто подключаем определенные входы и выходы последующих задач к BERT и точно настраиваем все параметры от начала до конца.
Эксперименты и результаты:
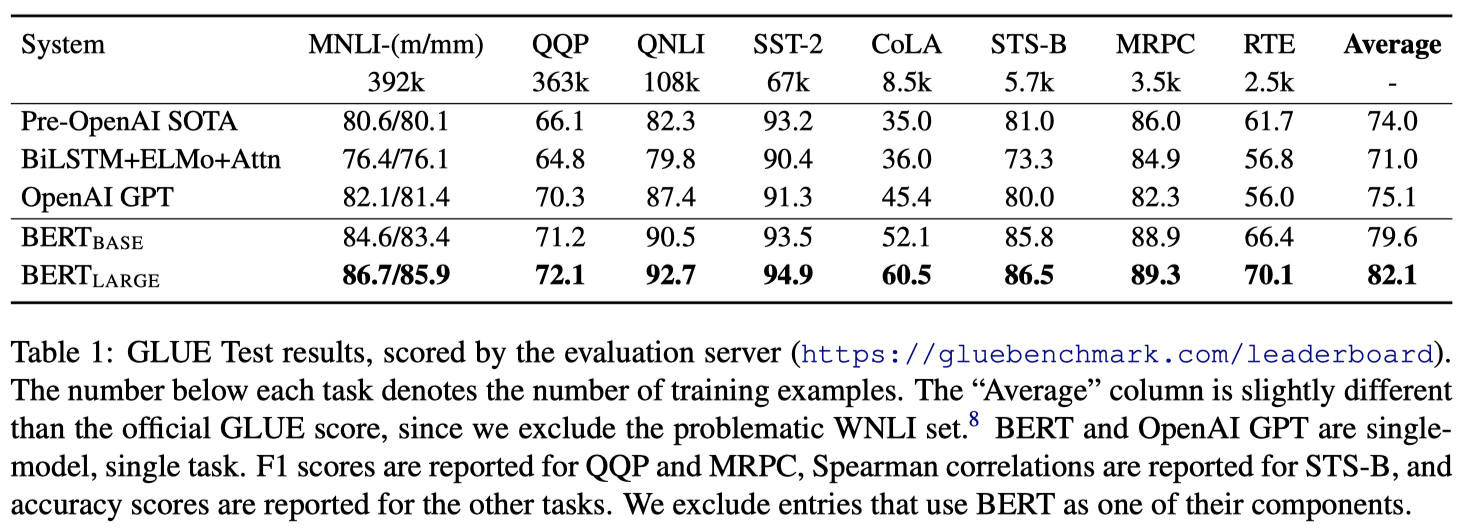
Сравнивая последний столбец, мы видим:
- BERT BASE обеспечивает среднюю точность 79,6%, в то время как предыдущая SOTA составляет 75,1%, BERT BASE повышает точность на 4,5%.
- BERT LARGE обеспечивает среднюю точность 82,1 % и повышает точность на 7,0 %.
Сравнивая последние две строки, мы видим, что BERT LARGE значительно превосходит BERT BASE во всех задачах.
Разобравшись с BERT, мы, наконец, подошли к основному содержанию этого поста. Мы введем первый метод квантования сжатия.
Q8BERT: квантованный 8-битный BERT
Q8BERT предлагает метод квантования для сжатия BERT. Q8BERT имитирует 8-битный квантованный вывод, сохраняя при этом точность 99 % по сравнению с исходным BERT для восьми задач NLP и занимая в 4 раза меньше памяти, чем исходный BERT.
Q8BERT применяет два ключевых метода в процессе тонкой настройки BERT:
- Симметричное линейное квантование
- Обучение с учетом квантования
Далее мы представим два метода.
Метод №1: схема квантования. Q8Bert квантовал как веса, так и активации до 8-битных целых чисел, используя симметричное линейное квантование.
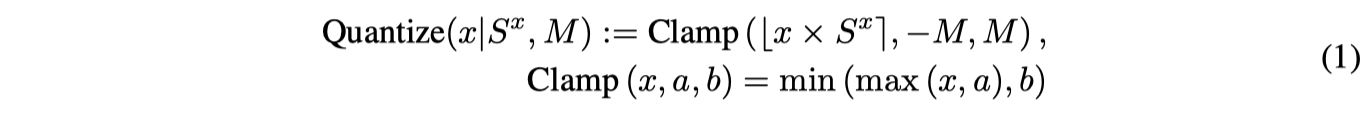
Чтобы понять эту формулу, Sx — это коэффициент масштабирования квантования для входных данных x, а M — максимальное квантованное значение. При квантовании до 8 бит M равно 127, потому что b равно 8.
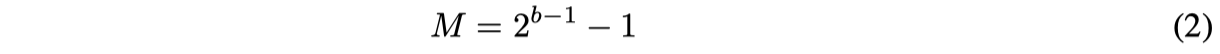
С помощью функции квантования мы можем квантовать все входные данные x в диапазоне от -M до M на основе Sx. Масштабный коэффициент весов рассчитывается по формуле:

а коэффициент масштабирования активаций рассчитывается на основе экспоненциальной скользящей средней (EMA) для плавного получения скользящей средней:

Метод № 2: Обучение с учетом квантования (QAT). Противоположностью QAT является другой метод квантования DQ. Давайте сначала разберем эти два метода.
- Обучение с учетом квантования (QAT): квантуется на этапе вывода.
- Динамическое квантование (DQ): квантование после обучения, обучение выполняется без какой-либо адаптации к процессу квантования.
Q8BERT использовал первый метод, сравнил экспериментальные результаты этих двух и объяснил, что QAT в конце концов дал лучшие результаты, чем DQ.
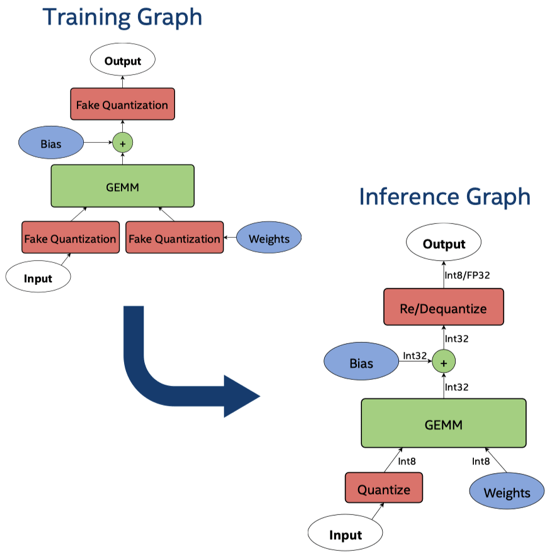
Прежде чем смотреть на рисунок выше, давайте проясним квантование и ложное квантование.
- Квантование: квантовать параметры FP32 в Int8.
- Поддельное квантование: имитирует эффект округления значений FP, квантует FP32 до Int8, а затем обратно до 32 бит.
Вернемся к предыдущему рисунку, он показывает, как Q8BERT работает на этапах тонкой настройки в BERT. Есть два графика, обучение и вывод.
- На обучающем графике: Q8BERT вводит фальшивое квантование, так что модель может коснуться ошибки квантования на этапе обучения и научиться преодолевать разрыв ошибки квантования.
- В графе вывода: введено реальное квантование.
Обратите внимание, что фальшивые операции квантования вставляются в места, где тензоры будут преобразованы в меньшее количество битов во время логического вывода.
Вам может быть интересно, как Q8BERT может оценить градиент фальшивого квантования, поскольку операция округления не является производной.
Q8BERT решил эту проблему, используя Straight-Through Estimator (STE).
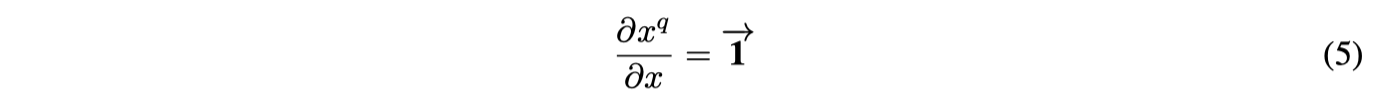
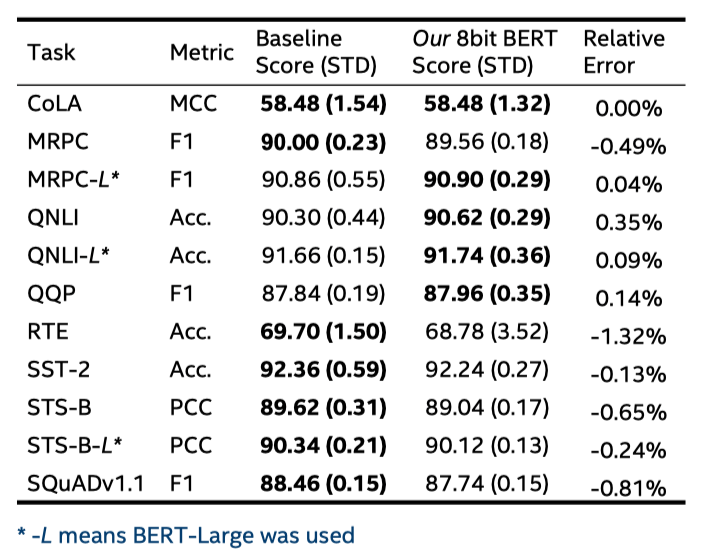
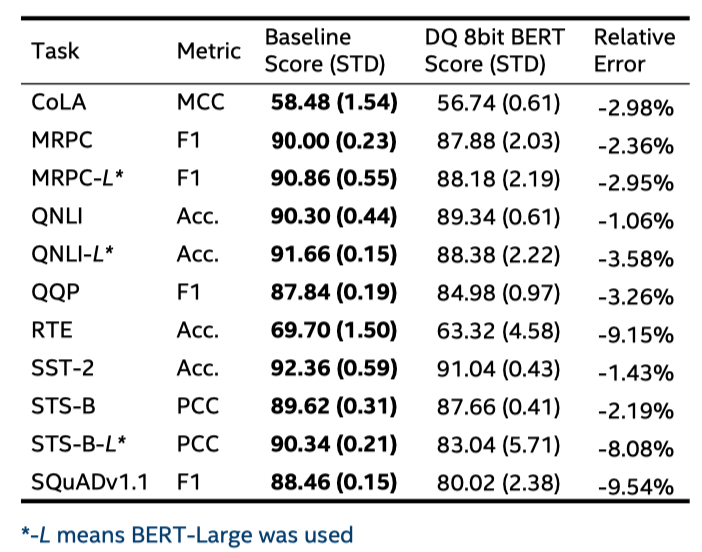
Эксперимент и результаты. Q8BERT экспериментирует с задачами GLUE и результатами SQuAD. Из двух таблиц мы видим:
- Из последнего столбца первой таблицы относительная ошибка QAT, вызванная квантованием, составляет менее 1%.
- По сравнению с последним столбцом двух таблиц Q8BERT дает значительно лучшие результаты по всем задачам, чем DQ.
Уменьшение глубины трансформатора по требованию благодаря структурированному дропауту
Хотя квантование уменьшает BERT, ограничивая точность его веса, оно не влияет на саму структуру сети. Именно здесь LayerDrop демонстрирует свой потенциал.
LayerDrop — это форма структурированного исключения. Идея довольно проста и состоит из двух шагов.
Во-первых, во время обучения модель случайным образом отбрасывает структуры. А под структурами, поскольку в статье в качестве предмета исследования используются Трансформеры, они имеют в виду Трансформаторный уровень кодировщиков или декодеров. Если мы углубимся в технические детали, этот метод исключения слоя реализован с матрицами масок, которые являются постоянными в пределах любого заданного слоя, в отличие от типичного исключения, которое не имеет этого ограничения в пределах слоя.
Во-вторых, во время вывода применяется обрезка слоев. Что касается стратегии обрезки, то автор предлагает три из них:
- Сбросьте все остальные слои. Эта стратегия лучше всего работает в экспериментах и приводит к более сбалансированной сети.
- Поиск по действительным. Эта стратегия пробует разные комбинации, чтобы увидеть, какая из них лучше всего подходит для проверочного набора. Однако у него есть несколько недостатков, поскольку он требует больших вычислительных ресурсов и может привести к возможному переобучению на проверочном наборе.
- Отсечение, управляемое данными. Эта стратегия параметризует скорость выпадения каждого слоя как нелинейную функцию, а затем в конце применяет функцию softmax.
Результаты эксперимента показывают, что при исключении слоя на этапе обучения производительность меньше снижается в сокращенных формах позже на этапе вывода. Другими словами, модель становится более устойчивой к последующей структурной обрезке после обучения с помощью LayerDrop.

DistilBERT, дистиллированная версия BERT
Наконец, давайте поговорим о подходе сжатия с совершенно другой идеологией: дистилляция знаний.

Как видно из рисунка выше, после того, как модель учителя обучает свои веса на основе данных, модель ученика учится у модели учителя. Под «обучением» мы подразумеваем, что модель ученика формирует свою функцию потерь с выходными данными обеих моделей, как указано ниже:

В этой формуле ti означает вероятность, оцененную учителем для метки i, а si означает вероятность, оцененную моделью ученика для метки i. Таким образом, модель ученика может использовать богатый обучающий сигнал, используя полное распределение модели учителя.
Чтобы взглянуть на этот процесс с более высокой точки зрения, модель ученика объединяет знания, полученные из данных, через более крупную модель учителя.
Результаты эксперимента показывают, что DistilBERT сохраняет 97% производительности BERT (как показано в таблице 1) и имеет меньшее количество параметров (66 миллионов) по сравнению с BERT-базой (110 миллионов). Меньше параметров означает более быстрое время вывода.

Заключение
В общем, логическая цепочка довольно проста: BERT хорош, но слишком велик — нужно его сжать. Но прежде чем мы начнем, мы хотели бы дать немного больше информации об этом.
Не знаю, заметили ли вы, но рассмотренные выше методы сжатия не являются эксклюзивными для BERT или других моделей, подобных Transformer, поэтому их можно широко применять. Кроме того, эти методы сжатия на самом деле являются ортогональными, что означает, что их можно использовать вместе для достижения еще более значительного сокращения времени отклика. Кроме того, все вышеперечисленные методы относятся к академическим кругам. Существует больше подходов к ускорению вывода модели с инженерной стороны, включая настройку потоков, кэширование и просто прямое расширение сервера.
Сжатие BERT — интересная и глубокая тема. Мы считаем, что больше достижений в этой области еще впереди.
Рекомендации
- Васвани, Ашиш и др. «Внимание — это все, что вам нужно». Достижения в области нейронных систем обработки информации. 2017.
- Девлин, Джейкоб и др. «Берт: предварительная подготовка глубоких двунаправленных преобразователей для понимания языка». препринт arXiv arXiv:1810.04805 (2018 г.).
- Санх, Виктор и др. «DistilBERT, дистиллированная версия BERT: меньше, быстрее, дешевле и легче». препринт arXiv arXiv:1910.01108 (2019 г.).
- Фан, Анджела, Эдуард Грейв и Арманд Жулен. «Уменьшение глубины трансформатора по требованию за счет структурированного отключения». препринт arXiv arXiv:1909.11556 (2019 г.).
- Зафрир, Офир и др. «Q8bert: квантованный 8-битный bert». препринт arXiv arXiv:1910.06188 (2019 г.).
- Представляем DistilBERT, дистиллированную версию BERT https://medium.com/huggingface/distilbert-8cf3380435b5
- DistilBERT — документация на трансформаторы 4.12.2 https://huggingface.co/transformers/model_doc/distilbert.html
- Учебное пособие: Тонкая настройка BERT для анализа настроений https://skimai.com/fine-tuning-bert-for-sentiment-analysis/
- Сжатие крупномасштабных моделей на основе трансформаторов: пример использования BERT »