Примечание.
Эта статья также доступна здесь. (на японском языке)
https://cloud.flect.co.jp/entry/2021/05/19/125034
Введение
В моем предыдущем блоге я рассказал, как запускать модели ИИ для виртуальных фонов Google Meet с помощью Tensorflow Lite (TFLite) в браузере. Итак, в этой статье я хотел бы представить одно из приложений этой технологии, которое представляет собой легкий, высокоскоростной сканер штрих-кода.
Вот как это работает. Несколько штрих-кодов, обращенных в разные стороны, можно считывать с высокой скоростью.

Облегченная модель семантической сегментации
Модель ИИ, используемая в виртуальном фоне, называется моделью семантической сегментации. Эта модель классифицирует, что находится в каждом пикселе изображения. Например, как показано на рисунке ниже, если вы введете изображение милой кошки слева, модель выведет изображение кошки и фона, как показано в середине. Это можно использовать для человека, чтобы идентифицировать область человека и фона, а затем заменить область фона другим изображением, чтобы реализовать виртуальный фон.

Хотя точность моделей ИИ часто подчеркивается, их легкость также важна, когда их необходимо обрабатывать в режиме реального времени, например, в виртуальном фоне, или когда они выполняются на устройствах с ограниченными вычислительными ресурсами. Многие исследователи все еще работают над повышением точности и уменьшением веса моделей ИИ, а также разрабатывают новые архитектуры моделей ИИ.
Архитектура моделей семантической сегментации часто состоит из двух компонентов (кодера и декодера). Согласно блогу Google AI, Google Meet использует облегченную модель под названием MobileNetV3-small для кодировщика, как показано на рисунке ниже. Декодер симметричен MobileNetV3-small, но никаких подробностей не приводится.

Поэтому я изучил документ MobileNetV3, который используется в качестве кодировщика, и обнаружил, что в нем также упоминается семантическая сегментация. Там же есть описание декодера, и там сказано, что он использует модуль под названием Lite R-ASPP для ускорения процесса.
Примечание. В документе кодировщик называется магистралью, а декодер — головкой сегментации.

Это может помочь вам создать упрощенную модель семантической сегментации.
Самодельная облегченная модель семантической сегментации для виртуальных фонов.
Итак, мы спроектировали архитектуру на основе приведенной выше информации и обучили ее.
Точность сегментации показана на рисунке ниже. (1) является результатом созданной нами упрощенной модели семантической сегментации. (2) и (3) — модели виртуального фона Google Meet. (4) — модель сегментации селфи, опубликованная Google. Модели в (4), (2) и (3) имеют почти одинаковую архитектуру. В скобках указано разрешение входного изображения для модели.

Мы видим, что точность (1) немного хуже, чем у других, так как части тела размыты. Вообще говоря, точность модели ИИ сильно зависит от качества и количества данных учителя, используемых для обучения. В этом случае мы сделали все возможное, чтобы собрать изображения людей для аннотации (и дополнения), но даже в этом случае, я думаю, количество аннотаций намного меньше, чем может предоставить Google. Я считаю, что это основная причина плохой точности. Кроме того, в архитектуре может быть определенное количество секретных трюков Google. И есть вероятность, что в созданной нами модели есть ошибка.
Время обработки каждого кадра показано ниже. Время обработки включает не только вывод модели, но и процесс рисования. Время в скобках — это время обработки при включенном simd. Учитывая разрешение, я думаю, что время обработки почти такое же, как у модели Google Meet. (Я понятия не имею, почему (1) быстрее, чем (2) с simd)

Я думаю, что вышеизложенное можно кратко резюмировать следующим образом.
- Точность на несколько ступеней уступает модели Google Meet.
(Это грубое ощущение, которое не было оценено количественно.) - Скорость обработки почти такая же, как в режиме Google Meet.
Основное назначение виртуального фона — защита конфиденциальности пользователя. В свете этого я думаю, что точность модели семантической сегментации должна быть на определенном высоком уровне. Если вы не рассчитываете собрать большое количество качественных данных об учителях, лучше использовать модель сегментации селфи, описанную выше как (3), которая распространяется под лицензией Apache-2.0 (карточка модели ).
Примечание. Лицензия модели сегментации Google Meet была изменена с Apache-2.0. Мы не знаем, как долго будет доступна лицензия Apache-2.0, поэтому будьте осторожны при ее использовании!
Эта демонстрация доступна по следующему URL-адресу.
Применение самодельной облегченной модели семантической сегментации к сканеру штрих-кода
Мы обнаружили, что использование нашей собственной облегченной модели семантической сегментации в качестве виртуального фона было плохой идеей, поскольку существуют другие альтернативы с более высокой точностью. С другой стороны, мы обнаружили, что это было довольно быстро. Поэтому в случае использования, когда достаточно некоторой точности, эту модель все же можно использовать.
Одним из примеров является приложение для сканеров штрих-кода.
Насколько я могу судить из исходного кода различных сканеров штрих-кода, доступных на Github, сканеры штрих-кода начинают с верхнего левого угла изображения и последовательно обнаруживают края, а оттуда декодируют штрих-код. Поэтому время обработки увеличится при попытке считать штрих-код с большого изображения. Если необходимо отсканировать один штрих-код, досрочный возврат может быть сделан после того, как штрих-код был отсканирован, но если необходимо отсканировать несколько штрих-кодов, изображение должно быть отсканировано полностью до конца, поэтому ожидается, что произойдет этот эффект. легко (рисунок ниже).
Примечание: ZBar, например, начинается с верхнего левого угла изображения и последовательно обнаруживает края с помощью производного фильтра и декодирует штрих-код при обнаружении края (сканирование изображения (src1) ⇛ вызов обнаружения и декодирования фронта (src2)). Этот процесс выполняется как в книжной, так и в альбомной ориентации. (Это было немного сложно понять, поэтому прошу прощения, если я ошибаюсь.)
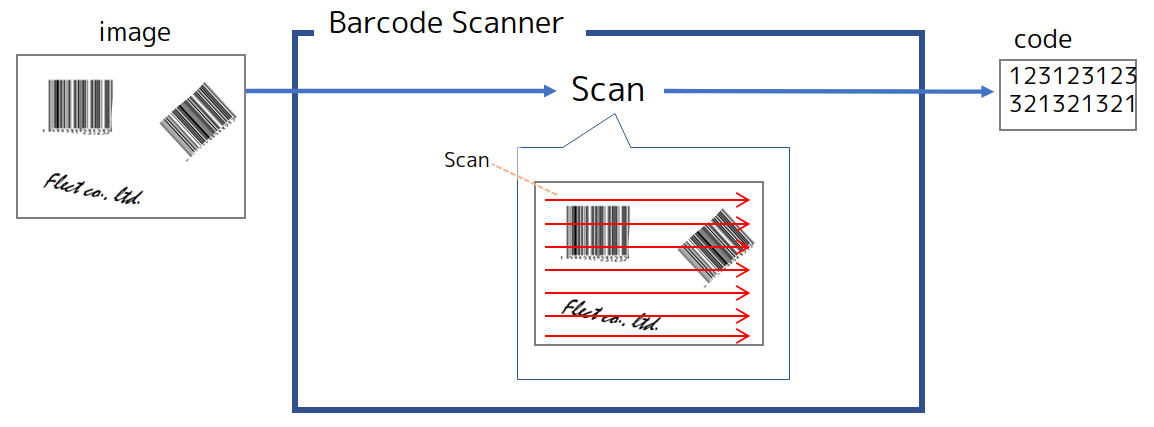
Идея на этот раз состоит в том, чтобы устранить процесс обнаружения штрих-кода в областях, где штрих-коды не существуют, путем вырезания областей, где штрих-коды могут существовать, с использованием облегченной модели семантической сегментации, которую я создал в качестве предварительной обработки (см. рисунок ниже). С немного другой точки зрения, это похоже на замену части последовательного процесса обнаружения краев процессом, который определяет область штрих-кода, вычисляя ее всю сразу с использованием оптимизированных матричных операций Tensorflow Lite (+ XNNPACK). Поскольку этот проект предназначен для запуска в браузере, ожидается, что включение simd, которое позволяет выполнять несколько вычислений одновременно, будет особенно эффективным.
С точки зрения точности, даже если мы вырезаем детали без штрих-кодов, мы можем определить наличие штрих-кодов на основе того, может ли их считывать сканер штрих-кодов. Предполагается, что все будет в порядке, даже если точность будет в некоторой степени низкой.

Оценка
Я создал сканер штрих-кода (веб-версия), используя мою собственную легкую семантическую сегментацию в качестве препроцессора. Сканер штрих-кода — это wasm-версия OSS ZBar. Чтобы облегчить считывание сканером штрих-кода, я добавил шаг предварительной обработки для исправления наклона области, обнаруженной семантической сегментацией.
Вот как он ведет себя при работе с изображением FullHD. Слева (1) версия с семантической сегментацией в качестве предварительной обработки, посередине (2) версия с включенной SIMD семантической сегментацией в качестве предварительной обработки, а справа (3) версия без предварительной обработки (ZBar просто был изменен) . «Время обработки» под анимацией — это время обработки (мс) каждого кадра. В качестве устройства используется Pixel4. Обратите внимание, что обработка наложения не выполняется, потому что ZBar сам по себе не может обнаружить область штрих-кода.
(1) и (2) намного точнее и работают быстрее. Поскольку для сканирования штрих-кода используется одно и то же программное обеспечение (ZBar), причина более высокой точности (1) и (2) заключается в корректировке наклона области штрих-кода.

(Также можно посмотреть в ютубе, https://youtu.be/Lv5dr2KD0H8 )
Вот как это выглядит в HD. Скорость обработки выше, но точность обнаружения чуть ниже. Это потому, что разрешение ниже. В общем, есть необходимый размер (разрешение) для сканирования штрих-кодов (см. ссылку), и чем ближе к этому размеру, тем сложнее сканировать. Вероятно, поэтому точность HD ниже.

(Вы также можете увидеть в youtube, https://youtu.be/2aYugJze0UE)
Время обработки каждого кадра показано ниже. Как для FullHD, так и для HD (1) и (2) быстрее, чем (3). И (2) с включенным simd работает быстрее, чем (1). Обратите внимание, что (1) и (2) быстрее, чем (3), даже несмотря на то, что они включают дополнительный процесс для исправления наклона штрих-кода. Что касается (3), то время обработки для FullHD и HD, как и ожидалось, почти пропорционально общему количеству пикселей. С другой стороны, для (1) и (2) время обработки не так сильно увеличивается при переходе от HD к FullHD. Необходимо проверить, можно ли это экстраполировать, но вполне вероятно, что преимущество (1) и (2) увеличивается при обработке изображений с более высоким разрешением.

Из вышеизложенного можно сказать, что предварительная обработка с облегченной семантической сегментацией позволила нам создать сканер штрих-кода, который работает быстрее и точнее, чем обычный сканер штрих-кода (версия WASM). Другими словами, в зависимости от варианта использования модель, использующая облегченную архитектуру семантической сегментации, может работать хорошо, даже если точность в некоторой степени низкая.
Эта демонстрация доступна по следующему URL-адресу.
Обсуждение
На этот раз, используя упрощенную семантическую сегментацию в качестве метода предварительной обработки для сканера штрих-кода, чтобы вырезать области, где штрих-коды могут быть обнаружены, мы смогли исключить часть последующего процесса обнаружения штрих-кода для сканера штрих-кода, тем самым ускорив весь процесс. процесс. Мы считаем, что это результат замены последовательного процесса обнаружения границ процессом обнаружения штрих-кода, основанным на оптимизированных матричных операциях. Если это так, мы можем модифицировать сканер штрих-кода для обнаружения штрих-кодов путем вычисления матрицы без использования ИИ (DNN) в предварительной обработке. На мой взгляд, если это возможно, то это правильно. Однако переписывание внутренней обработки программного обеспечения, которое уже существует как устоявшаяся технология, например, сканера штрих-кода, является довольно дорогостоящим и сопряжено с высоким риском деградации. Итак, я думаю, что более практично и менее затратно предварительно обрабатывать облегченный процесс с использованием Tensorflow Lite (+XNNPACK), который обеспечивает оптимизированную матричную арифметическую обработку в качестве основы.
Также есть вопрос, ускорит ли процесс симирование ZBar. На самом деле я пытался собрать его с опцией simd, но это почти не дало никакого эффекта, поэтому я решил пропустить его в этот раз. Есть некоторые разговоры о том, чтобы не использовать SIMD самостоятельно (по-японски), насколько это возможно, но я думаю, что это потому, что вам нужно писать код с учетом этого в некоторой степени, чтобы действительно получить эффект от simd.
Вывод
Я заметил, что Google щедро предоставил инструкции о том, как создать облегченную модель семантической сегментации, поэтому я попытался создать свою собственную. В результате я обнаружил, что могу создать довольно быструю модель, хотя точность невелика. Я подумал, что эта модель будет более подходящей для случаев использования, где достаточно определенного уровня точности, например, для предварительной обработки сканеров штрих-кода, а не для случаев использования, требующих высокоточной модели, таких как виртуальные фоны, поэтому я реализовал ее. экспериментально. В результате мы смогли реализовать сканер штрих-кода, который работает быстрее и точнее, чем обычные сканеры штрих-кода. Приложение к сканерам штрих-кода — это лишь один пример того, где можно применить нашу собственную упрощенную семантическую сегментацию. Я считаю, что есть и другие места, где можно использовать быструю семантическую сегментацию с некоторой точностью. Я буду продолжать экспериментировать с ним всякий раз, когда я придумаю что-то.

Репозиторий
Демонстрация вышеуказанного сканера штрих-кода хранится в следующем репозитории.
Благодарности
Я использовал изображения людей, видео людей и фоновые изображения с этого сайта.