
Как использовать селекторы CSS при парсинге веб-страниц в Python
Учебник по парсингу веб-страниц с помощью селекторов CSS с использованием Python.
- "Вступление"
- Предпосылки
- Что такое CSS-селекторы
- СелекторГаджет
- Выбор CSS-селекторов вручную
- Типы CSS-селекторов
- Тестирование CSS-селекторов
- Плюсы CSS-селектора
- Минусы селектора CSS
- Примеры кода
- Ссылки
вступление
Этот пост в блоге продолжается с несколько регулярными обновлениями. Речь идет о понимании селекторов CSS при просмотре веб-страниц и о том, какие инструменты могут быть удобны для использования.
В SerpApi мы столкнулись с разными типами селекторов, некоторые из них довольно сложные, которые включают в себя сложную логику, например, логика может включать в себя такие селекторы, как :has(), :not() среди других селекторов, и мы хотим поделиться своими знаниями. полученный во время нашего путешествия при создании наших API.
Мы хотим отметить, что этот пост в блоге не является полным справочником по селекторам CSS, а представляет собой мини-экскурсию по часто используемым и более продвинутым типам селекторов и тому, как с ними работать во время просмотра веб-страниц с примерами кода.
Предпосылки
Базовое знакомство с библиотекой bs4 или любым другим пакетом/фреймворком синтаксического анализа HTML, который вы используете, поскольку использование селекторов CSS на разных языках, платформах, пакетах не сильно отличается.
Установить библиотеки:
pip install requests lxml beautifulsoup4Что такое селекторы CSS
Селекторы CSS — это шаблоны, используемые для выбора элементов, которые вы хотите извлечь из HTML-страницы.
SelectorGadget
Начнем с простого — расширения SelectorGadget для Chrome. Это расширение позволяет быстро получить селектор(ы) CSS, щелкнув нужный элемент в браузере, и возвращает селектор(ы) CSS.
SelectorGadget – это инструмент с открытым исходным кодом, который упрощает создание и обнаружение селекторов CSS на сложных сайтах.
Случаи использования:
- для очистки веб-страниц с помощью таких инструментов, как
NokogiriиBeautifulSoup. - для создания
jQueryселекторов для динамических сайтов. - как инструмент для изучения структур DOM, сгенерированных JavaScript.
- как инструмент, который поможет вам стилизовать только определенные элементы на странице с помощью ваших таблиц стилей.
- для
seleniumилиphantomjsтестирования.
При использовании SelectorGadget он выделяет элементы в:
- желтый, что означает, что он угадывает, что ищет пользователь, и нуждается в возможности дополнительных разъяснениях.

- красный исключает из подбора совпадений.

- зеленый включает, чтобы соответствовать выбору.

Выбор селекторов CSS вручную
Поскольку SelectorGadget не является волшебным универсальным инструментом, иногда он не может получить нужный элемент. Это происходит, когда HTML-дерево веб-сайта плохо структурировано или если сайт отображается с помощью JavaScript.
Когда это происходит, мы используем вкладку «Элементы» через Инструменты разработчика (F12 на клавиатуре или CTRL+SHIFT+C), чтобы найти и захватить селектор(ы) CSS или элементы HTML по их:
- селектор типа:
<input> - селектор класса:
.class - селектор идентификатора:
#id - селектор атрибутов:
[attribute]
Типы селекторов CSS
Селекторы типов
✍Синтаксис: element_name
Селекторы типа сопоставляют элементы по имени узла. Другими словами, он выбирает все элементы данного типа в HTML-документе.
soup.select('a') # returns all <a> elements
soup.select('span') # returns all <span> elements
soup.select('input') # returns all <input> elements
soup.select('script') # returns all <script> elementsСелекторы классов
✍Синтаксис: .class_name
Селекторы класса сопоставляют элементы на основе содержимого их атрибута класса. Это похоже на вызов метода класса PressF().when_playing_cod().
soup.select('.mt-5') # returns all elements with current .selector
soup.select('.crayons-avatar__image') # returns all elements with current .selector
soup.select('.w3-btn') # returns all elements with current .selectorСелекторы идентификаторов
✍Синтаксис: #id_value
Селекторы ID соответствуют элементу на основе значения атрибута elements id. Чтобы элемент был выбран, его атрибут id должен точно соответствовать значению, указанному в селекторе.
soup.select('#eob_16') # returns all elements with current #selector
soup.select('#notifications-link') # returns all elements with current #selector
soup.select('#value_hover') # returns all elements with current #selectorСелекторы атрибутов
✍Синтаксис: [attribute=attribute_value] или [attribute], больше примеров.
Селекторы атрибутов сопоставляют элементы на основе наличия или значения данного атрибута.
Единственное отличие состоит в том, что эти селекторы используют фигурные скобки [] вместо точки (.) в качестве класса или решетку (или октоторп) (#) в качестве идентификатора.
soup.select('[jscontroller="K6HGfd"]') # returns all elements with current [selector] soup.select('[data-ved="2ascASqwfaspoi_SA8"]') # returns all elements with current [selector]# elements with an attribute name of data-id soup.select('[data-id]') # returns all elements with current [selector]
Список выбора
✍Синтаксис: element, element, element, ...
В списке выбора выбираются все соответствующие узлы (элементы). С точки зрения просмотра веб-страниц эти селекторы CSS отлично подходят (по моему мнению) для обработки различных макетов HTML, потому что, если присутствует один из селекторов, он захватит все элементы из существующего селектора.
В качестве примера из поиска Google (результаты карусели) макет HTML будет отличаться в зависимости от страны, из которой исходит поиск.
Если страна поиска не США:
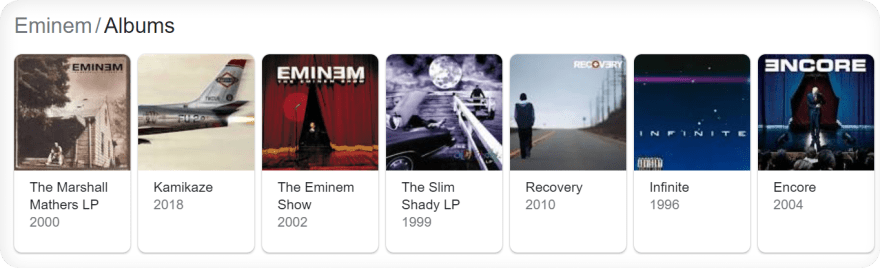
Если для страны поиска установлено США:

Следующие примеры переводятся в этот фрагмент кода (обрабатывает оба макета HTML):
# will return all elements either by one of these selectors
soup.select('#kp-wp-tab-Albums .PZPZlf, .keP9hb')Комбинатор потомков
✍Синтаксис: selector1 selector2
Комбинатор потомков, представленный одним символом пробела (), выбирает два селектора таким образом, что элементы, соответствующие второму селектору, выбираются, если у них есть элемент-предок (родительский, родительский родительский, родительский и т. д.), соответствующий элементу первый селектор.
soup.select('.NQyKp .REySof') # dives inside .NQyKp -> dives again to .REySof and grabs data from it
soup.select('div cite.iUh30') # dives inside div -> dives inside cite.iUh30 and grabs data from it
soup.select('span#21Xy a.XZx2') # dives inside span#id -> dives inside a.XZx2 and grabs data from itСелектор :nth-child()
✍Синтаксис: selector|element:nth-child()
Псевдокласс :nth-child() сопоставляет элементы на основе их положения среди группы братьев и сестер.
soup.select('p.SacA1:nth-child(1)') # selects every second p.SacA1 elementСелектор :has()
✍Синтаксис: selector|element:has(selector|element)
:has() — это псевдокласс, который проверяет, содержит ли родительский элемент (элементы) определенные дочерние элементы.
soup.select('p:has(.sA1Sg)') # checks if p element that has .sA1Sg selector as a childФункция содержит()
✍Синтаксис: selector|element:contains(selector|element|text)
contains() не полностью связан с селекторами CSS, а скорее с XPath. Он возвращает true или false, если в подстроке искомой (первой) строки есть значение. Немного запутанно, давайте покажем пример.
from parsel import Selectordummy_string_1 = 'I saw a cat that had $3000 in the pocket' dummy_string_2 = 'I saw a cat that was dancing with pigeon'selector_1 = Selector(text=dummy_string_1) selector_2 = Selector(text=dummy_string_2)# $ has to be espaced with \ symbol # otherwise SelectorSyntaxError will be raised text_1 = selector_1.css(':contains(\$)::text').get() 👈👈👈 text_2 = selector_2.css(':contains(\$)::text').get()print(text_1) print(text_2)
Выходы:
I saw a cat that had $3000 in the pocket 👈👈👈
NoneСелектор :not()
✍Синтаксис: selector|element:not(selector|element|text)
Псевдокласс :not() используется для предотвращения выбора определенных элементов.
Псевдокласс :not можно использовать (связать) с методом contains() для создания логического выражения, что очень удобно.
Продолжая предыдущий пример, мы можем выбрать элемент, который не содержит символа $ в тексте :not(:contains(\$))::text:
from parsel import Selectordummy_string_1 = 'I saw a cat that had $3000 in the pocket' dummy_string_2 = 'I saw a cat that was dancing with pigeon'selector_1 = Selector(text=dummy_string_1) selector_2 = Selector(text=dummy_string_2)# $ has to be espaced with \ symbol # otherwise SelectorSyntaxError will be raised text_1 = selector_1.css(':contains(\$)::text').get() text_2 = selector_2.css(':not(:contains(\$))::text').get() 👈👈👈print(text_1) print(text_2)
Выходы:
I saw a cat that had $3000 in the pocket
I saw a cat that was dancing with pigeon 👈👈👈Вот более практичное использование, когда нам нужно выбрать все (только категорию), которые не содержат $ в текстовой строке:
Без :not(:contains(\$))С :not(:contains(\$))
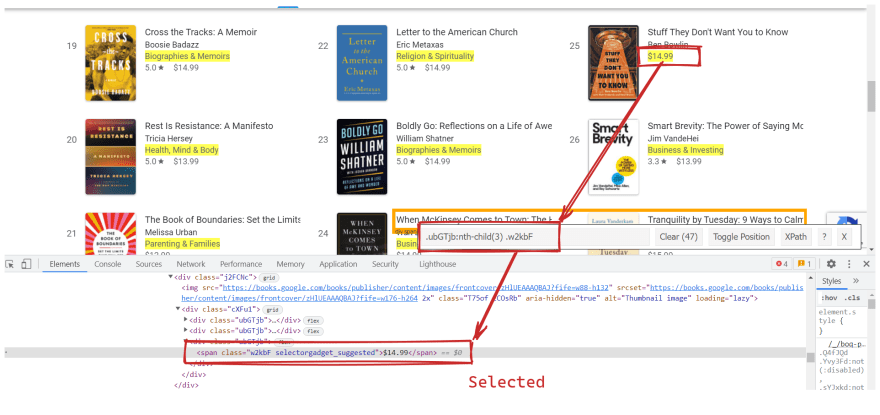

Другие полезные селекторы CSS:
:nth-of-type()Выбирает каждый элементn, который является вторым элементомnсвоего родителя.- Функция
:is()pseudo-class принимает в качестве аргумента список селекторов и выбирает любой элемент, который может быть выбран одним из селекторов в этом списке.
Дополнительные полезные селекторы CSS можно найти в разделах Селекторы W3C уровня 4, Справочник по селекторам CSS W3Schools и Документация по селекторам CSS MDN.
Тестирование селекторов CSS
Чтобы проверить, извлекает ли селектор правильные данные, вы можете:
Поместите эти селекторы CSS в окно SelectorGadget и посмотрите, какие элементы выбираются:

Используйте вкладку Dev Tools Console с помощью метода $$(".selector") (создает array (list()) элементов):
$$(".DKV0Md")Что эквивалентно методу document.querySelectorAll(".selector") (согласно сайту разработчиков Chrome:
document.querySelectorAll(".DKV0Md")Вывод из консоли DevTools для обоих методов одинаков:

Плюсы селектора CSS
- легко подобрать.
- легко привыкнуть (особенно если у вас есть фон HTML).
- имеет инструменты, чтобы помочь выбрать (выбрать) их.
- может быть понятен внутри кода, если понятен сам селектор, а не что-то вроде
.wtf228YoLo.
Минусы селектора CSS
Делать ставки только на классы может быть не очень хорошей идеей, поскольку они, вероятно, могут измениться.
Немного более надежным способом было бы использование селекторов селекторов атрибутов (упомянутых выше), они, вероятно, будут меняться реже.
Примеры селекторов атрибутов: (HTML из обычных результатов Google):

Многие современные веб-сайты используют автоматически сгенерированные селекторы CSS для каждого изменения, вносимого в определенные компоненты стиля, а это означает, что полагаться исключительно на них — не очень хорошая идея. Но опять же, это будет зависеть от того, как часто они действительно меняются.
Самая большая проблема, которая может возникнуть, заключается в том, что когда код будет выполняться, он выдаст ошибку, и сопровождающий кода должен вручную изменить селектор(ы) CSS, чтобы код работал правильно.
Кажется, это не имеет большого значения, и это правда, но может раздражать, если селекторы часто меняются.
Примеры кода
В этом разделе будет показано несколько реальных примеров с разных веб-сайтов, чтобы вы могли лучше ознакомиться.
Извлечение заголовка, фрагмента, ссылки, отображаемой ссылки из результатов поиска Google.
Протестируйте селектор контейнеров CSS:

Код:
import requests, lxml from bs4 import BeautifulSoupheaders = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36" }html = requests.get("https://www.google.com/search?q=minecraft", headers=headers) soup = BeautifulSoup(html.text, "lxml")for result in soup.select(".tF2Cxc"): title = result.select_one(".DKV0Md").text link = result.select_one(".yuRUbf a")["href"] displayed_link = result.select_one(".lEBKkf span").text snippet = result.select_one(".lEBKkf span").textprint(f"{title}\n{link}\n{displayed_link}\n{snippet}\n")# part of the output ''' Log in | Minecraft https://minecraft.net/login https://minecraft.net › login Still have a Mojang account? Log in here: Email. Password. Forgot your password? Login. Mojang © 2009-2021. "Minecraft" is a trademark of Mojang AB.What is Minecraft? | Minecraft https://www.minecraft.net/en-us/about-minecraft https://www.minecraft.net › en-us › about-minecraft Prepare for an adventure of limitless possibilities as you build, mine, battle mobs, and explore the ever-changing Minecraft landscape. '''
Извлечение заголовков из блога SerpApi

Тестирование селектора CSS .post-card-title в консоли Devtools:
$$(".post-card-title")(7) [h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title] 0: h2.post-card-title 1: h2.post-card-title 2: h2.post-card-title 3: h2.post-card-title 4: h2.post-card-title 5: h2.post-card-title 6: h2.post-card-title length: 7 [[Prototype]]: Array(0)
Код:
import requests, lxml from bs4 import BeautifulSouphtml = requests.get("https://serpapi.com/blog/") soup = BeautifulSoup(html.text, "lxml")for title in soup.select(".post-card-title"): print(title.text)''' Scrape Google Carousel Results with Python SerpApi’s YouTube Search API DuckDuckGo Search API for SerpApi Extract all search engines ad results at once using Python Scrape Multiple Google Answer Box Layouts with Python SerpApi’s Baidu Search API How to reduce the chance of being blocked while web scraping search engines '''
Извлечь заголовок, ссылку из фида dev.to
Протестируйте селектор CSS с помощью SelectorGadget или консоли DevTools:

Код:
import requests, lxml from bs4 import BeautifulSoupheaders = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36" }html = requests.get("https://dev.to/", headers=headers) soup = BeautifulSoup(html.text, "lxml")for result in soup.select(".crayons-story__title"): title = result.text.strip() link = f'https://dev.to{result.a["href"].strip()}'print(title, link, sep="\n")# part of the output: ''' How to Create and Publish a React Component Library https://dev.to/alexeagleson/how-to-create-and-publish-a-react-component-library-2oe A One Piece of CSS Art! https://dev.to/afif/a-one-piece-of-css-art-225l Windster - Tailwind CSS admin dashboard interface [MIT License] https://dev.to/themesberg/windster-tailwind-css-admin-dashboard-interface-mit-license-3lb6 '''
Ссылки
- Селекторы
CSSуровня 4 W3C - MDN
CSSСелекторы - Справочник по селекторам W3Schools
CSS - СелекторГаджет
CSSУжин- Спецификации W3C
CSS BeautifulSoupCSSселекторы документы
Присоединяйтесь к нам в Твиттере | "YouTube"
Первоначально опубликовано на https://serpapi.com 22 ноября 2021 г.
Больше контента на plainenglish.io. Подпишитесь на нашу бесплатную еженедельную рассылку здесь.