В этом блоге мы будем выполнять прогнозирование налога на дом с использованием алгоритма случайного леса. Для решения этой задачи мы будем использовать очень известные данные о жилье в Бостоне. Так что без лишних слов.
Полную статью с исходным кодом читайте здесь —https://machinelearningprojects.net/house-tax-prediction/
Давай сделаем это…
Шаг 1 — Импорт необходимых пакетов.
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.metrics import r2_score %matplotlib inline
Шаг 2 — Чтение наших данных.
data = pd.read_csv(‘HousingData.csv’) data.head()

Шаг 3 — Опишите наши данные.
data.describe()

Шаг 4 — Проверьте информацию о наших данных.
data.info()
- Как мы видим ниже, есть 4 5 столбцов, которые не имеют значений 506, что означает, что в них есть нулевые значения.
- Вот почему нам нужно заполнить эти нулевые значения, чтобы все столбцы были одинакового размера.

Шаг 5 — Заполнение нулевых значений.
col = ['CRIM','ZN','INDUS','CHAS','AGE','LSTAT']
for c in col:
data[c].fillna(data[c].mean(),inplace=True)
- Здесь мы просто заполняем нулевые поля средним значением этого столбца.
- Мы передали inplace=True, потому что хотим внести это изменение в исходный набор данных.
Шаг 6 — Теперь снова проверяем информацию о наших данных.
data.info()
- Ниже мы видим, что теперь все столбцы имеют 506 ненулевых значений.
- Это очень важный шаг в предварительной обработке данных. Мы должны либо удалить записи с нулевыми значениями, либо заполнить их некоторым значением по умолчанию, либо мы также можем заполнить их средним значением, как мы сделали в этом случае.

Шаг 7 — Проверьте корреляцию нашего целевого поля «НАЛОГ» с другими функциями.
data.corr()[‘TAX’].sort_values(ascending=False)
- Здесь мы просто проверяем корреляцию нашего целевого столбца «НАЛОГ» с другими столбцами.
- Мы видим, что он имеет самую высокую корреляцию со столбцом «RAD». Это означает, что значение TAX прямо пропорционально значению RAD.

Шаг 8 — Предварительная обработка наших данных.
from sklearn.preprocessing import StandardScaler
X = data.drop('TAX',axis=1)
y = data['TAX']
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- Мы создаем X, который является нашими функциями/всеми столбцами, кроме столбца ярлыков/НАЛОГА.
- Мы создаем y, который является просто столбцом TAX.
- Мы масштабируем данные X, используя Standard Scaler, чтобы привести все к одному и тому же масштабу [0–1].
- Затем мы просто разбиваем наши данные в пропорциях 70–30 для данных обучения и тестирования соответственно, используя train-test-split.
Шаг 9 — Обучение нашей модели прогнозирования налога на дом.
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
rfc = RandomForestRegressor()
params = {'n_estimators':[100,200,300,400,500,600,700,800,900,1000]}
grid_model = GridSearchCV(rfc, params,verbose=2)
grid_model.fit(X_train,y_train)
pred = grid_model.predict(X_test)
print('Random Forest accuracy is --> ',r2_score(y_test,pred)*100)
- Мы выбрали Random Forest Regressor для этой конкретной постановки задачи.
- Я также пробовал линейную регрессию, регрессию лассо и регрессию гребня, но все они дали меньший показатель r2, чем случайный лес.
- Здесь мы используем Grid Search CV, чтобы найти наилучшее значение параметра n_estimator случайного леса.

Шаг 10. Проверка лучших параметров модели прогнозирования налога на недвижимость.
grid_model.best_params_
- Используя Grid Search CV, мы узнали, что лучшим значением для n_estimator будет 700.

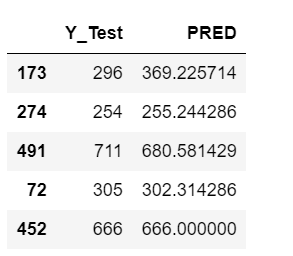
Шаг 11 — Просто наблюдайте за результатами.
res = pd.DataFrame() res['Y_Test'] = y_test res['PRED'] = pred res.head()
- Простой шаг, на котором мы видим, каков наш прогноз и каким он должен быть.
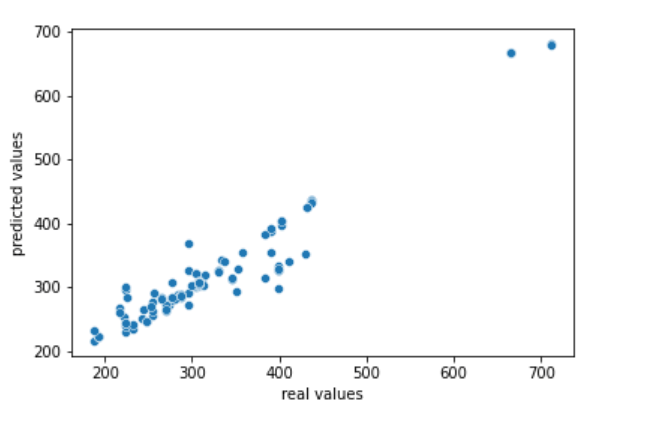
Шаг 12 — Составление результатов прогнозирования налога на жилье.
sns.scatterplot(y_test,pred) plt.xlabel(‘real values’) plt.ylabel(‘predicted values’)
Дайте мне знать, если у вас есть какие-либо вопросы относительно прогнозирования налога на дом, связавшись со мной по электронной почте или в LinkedIn.
Чтобы узнать больше о машинном обучении, глубоком обучении, компьютерном зрении, НЛП и проектах Flask, посетите мой блог.
Для дальнейшего объяснения кода и исходного кода посетите здесь —
Итак, это все для этого блога, ребята, спасибо за то, что прочитали его, и я надеюсь, что вы возьмете что-то с собой после прочтения этого и до следующего раза 👋…