Функции Pandas, используемые для манипулирования данными, предварительной обработки и обработки
В этой статье я соберу все отдельные статьи из моей серии — «Функции Pandas, которые
должен знать каждый Data Scientist». Для тех, кто прочитал все статьи, ничего нового не будет. После окончания каждой серии я сделаю статью, в которой все подытожу! Без лишних слов давайте погрузимся в мир панд. 😊

Первое, что нам нужно сделать, это импортировать набор данных, который мы используем для следующих примеров.

1. df.info()
Функция dataframe.info() используется для получения общего обзора фрейма данных, что может быть очень полезно при проведении исследовательского анализа данных. Вы получаете информацию о количестве столбцов, а также о количестве строк, типах данных и ненулевых значениях.

2. df.head() и df.tail()
После того, как вы прочитали набор данных в кадре данных pandas, также может быть очень полезно отобразить первую или последнюю строки. Вы можете поместить в скобки количество строк, которые вы хотите отобразить. -> df.head(5) или df.tail(10)


3. df.dtypes
Нам нужно, чтобы наши значения хранились в соответствующих типах данных, чтобы предотвратить возникновение ошибок. Чем больше набор данных, тем важнее использование памяти. Поэтому вам нужно проверить, лучше ли применяются dtypes или нет.

4. df.shape и df.size
Функцию формы можно использовать в кадрах и сериях данных pandas, а также в массивах NumPy. Функция показывает размеры, а также размер в каждом измерении. Например, форма (20000, 15) означает 20000 строк и 15 столбцов.
Соотношение строк и столбцов очень важно при разработке и реализации моделей машинного обучения. В случае, если наблюдений недостаточно (строки = наблюдения) в отношении функций (функции = столбцы), нам может потребоваться применить некоторую предварительную обработку, такую как извлечение признаков или уменьшение размеров.
Вот примеры:

size() возвращает наблюдения, умноженные на функции, а shape() возвращает их отдельно.
5. df.describe()
Приступая к исследовательскому анализу данных, вы не должны пропустить одну функцию — df.describe(). Это дает вам статистическую сводку почти для каждого атрибута.

Вы также можете использовать оператор транспонирования для переключения со столбцов на строки и наоборот. На мой взгляд, лучшее представление ценностей.

6. образец ()
Метод sample() возвращает случайно выбранные значения из вашего фрейма данных или серии. При использовании head() или tail() вы всегда будете видеть только первую или последнюю строку набора данных. С помощью этого метода вы можете получить лучшее представление о своем наборе данных.

7. isnull() и isna()
Способность работать с отсутствующими значениями имеет решающее значение для Data Scientist для создания надежного процесса обработки данных. Вам следует обратить пристальное внимание на эту тему, так как пропущенные значения могут существенно повлиять на точность вашего анализа. Методы isnull() и isna() возвращают фрейм данных с логическими значениями, указывающими true для нулевого значения.


8. isnull().sum()
Вы можете получить сумму пропущенных значений для каждого атрибута, используя isnull().sum(). В нашем случае нам повезло, потому что их нет. Это, вероятно, не будет иметь место в реальных наборах данных.

9. нуник()
nunique() возвращает уникальные записи по всему атрибуту или по умолчанию по всем строкам. Это может пригодиться при работе с категориальными значениями. Если вы не знаете, сколько существует категориальных значений, вы определенно можете использовать nunique(), чтобы получить лучший обзор.

10. df.columns
df.columns возвращает все имена столбцов, что может быть очень полезно, если вы работаете с большим набором данных.

11. df.memory_usage()
Этот метод возвращает использование памяти для каждого столбца в байтах. Представьте набор данных с 2 миллионами строк, вам нужно будет оптимизировать набор данных, чтобы работать с ним. В этом случае вы можете получить обзор использования памяти, используя df.memory_usage().

12. df.nsmalest() и df.nlargest()
С помощью этих двух методов вы можете легко найти, например, самые большие значения n или самые низкие значения n столбца.
Давайте попробуем…
мы хотим найти 5 самых больших значений POPESTIMATE2011:

Хорошо, это сработало, поэтому давайте получим 5 самых низких значений POPESTIMATE2011:

13. df.loc()
df.loc() используется для выбора строк и столбцов по меткам. В случае столбцов метками будут заданные имена столбцов. Если вы не назначите определенные индексы самостоятельно, метки для строк будут индексами, созданными пандами, начиная с 0. В противном случае вы можете использовать индексы, которые вы создали для строк.
Получите первые 7 строк столбцов «СУМЛЕВ», «РЕГИОН», «ОТДЕЛ». Как видите, мы используем обычные индексы в качестве меток, поскольку вместо них мы не указали никаких меток.

14. df.iloc()
df.iloc(), с другой стороны, выбирает данные по положению. Поэтому, чтобы получить тот же результат, что и выше, нам нужно запустить следующую строку кода:

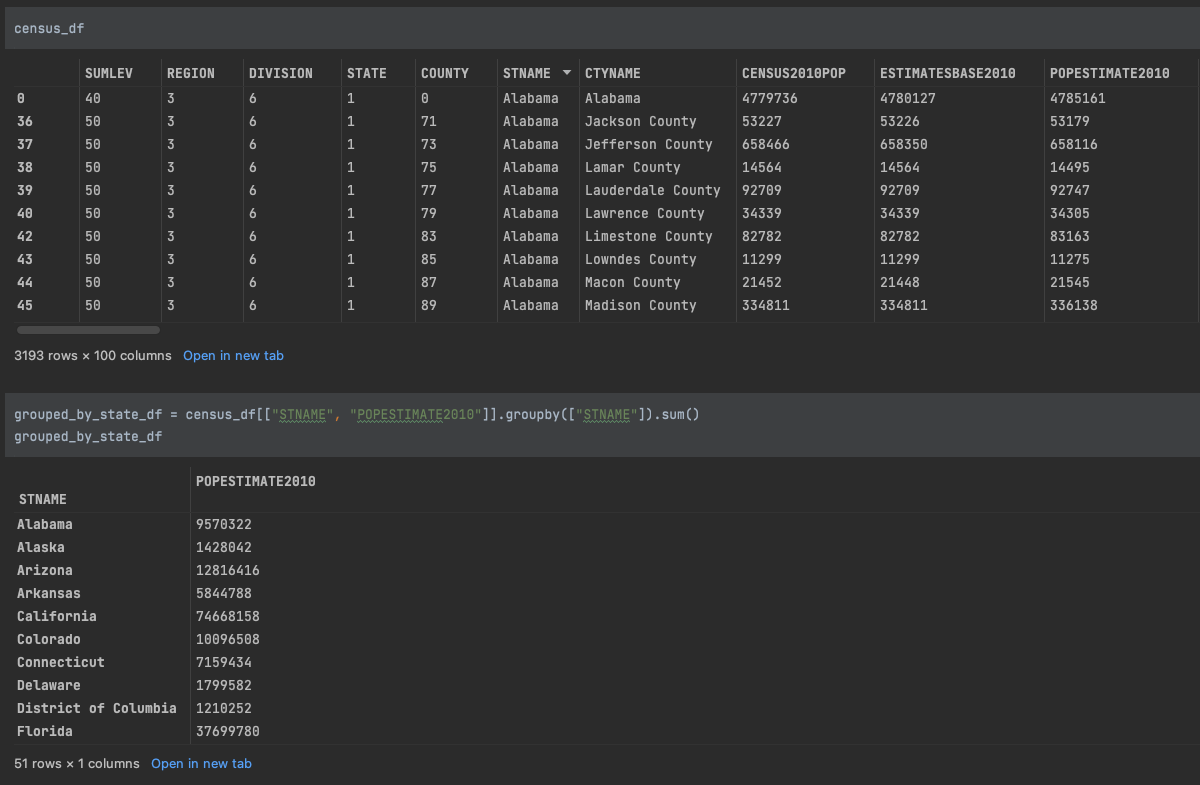
15. df.groupby()
С помощью метода groupby() вы можете группировать строки вместе. В нашем примере мы хотели вернуть сумму POPESTIMATE2010 по состоянию. Нам нужно было сгруппировать округа в соответствующий штат. Поэтому мы сгруппировали по состоянию и применили метод суммы. Вы также можете применить mean(), например, к сгруппированному объекту.
16. df.sort_values() и df.sort_index()
Вы можете отсортировать кадр данных, используя любой из вышеупомянутых методов. Существует также возможность сортировки по оси Y или X. Кроме того, вы можете решить, следует ли сортировать по убыванию или по возрастанию — по возрастанию = ИСТИНА (по умолчанию), если вы хотите сортировать по убыванию, вам нужно установить по возрастанию = ЛОЖЬ.

17. df.dropna()
Большую часть времени вам приходится иметь дело с грязными наборами данных. В этом случае dropna() может стать весьма полезным для очистки ваших наборов данных. Вы можете легко удалить столбцы или строки со значениями na. Обратите внимание, какие столбцы или строки вы отбрасываете. Возможно, вам придется найти другой способ борьбы с nas. Поскольку наш набор данных уже был без NAS, мы получаем то же количество строк, что и раньше.

18. тип ()
astype() используется для приведения объекта Python к определенному типу данных. Вам это понадобится, если, например. ваши данные не хранятся в правильном формате/типе данных. Вы можете просто изменить тип данных серии/столбца pandas, используя следующую функцию:
data_df[“Gender”] = data_df[“Gender”].astype(“category”)
19. to_datetime()
to_datetime() преобразует объект Python в формат даты и времени. Он может обрабатывать целые числа, числа с плавающей запятой, серии pandas и кадры данных pandas в качестве аргументов.
data_df[“date”] = pd.to_datetime(data_df[“Gender”])
20. значение_счетчиков ()
value_counts() может подсчитывать появление уникальных значений в серии pandas. Функция вернет серию со счетчиками справа.
data_df[“State”].value_counts()
В нашем примере он вернет счетчики для каждого состояния, доступного в наборе данных.
21. drop_duplicates()
drop_duplicates() удаляет дубликаты в кадре данных Pandas. Он вернет фрейм данных без дубликатов. Вы можете легко проверить количество строк, используя метод формы.
data_df.drop_duplicates(inplace=true)
inplace=true гарантирует, что изменения будут применены к исходному набору данных.
22. слияние ()
merge() используется для объединения двух объектов Pandas DataFrame или DataFrame с объектом Series в общем столбце.
data_df.merge(data2_df, on=”CustomerId”, how=”left”)
23. наполнить()
Как правило, в большом наборе данных вы найдете несколько записей, помеченных NaN (не числом). Эти записи NaN не были заполнены в исходном наборе данных. fillna() помогает найти и заменить их, заменяя эти отсутствующие значения более подходящими значениями.
data_1[“City temp”].fillna(35, inplace=True)
Вы также можете использовать среднее значение, медиану или режим, например, для вменения пропущенных значений.
Это были некоторые из наиболее важных функций и методов pandas, которые вы должны знать как Data Scientist. Я скоро вернусь к теме Pandas с более продвинутыми функциями и методами.
Подпишитесь на меня, чтобы не пропустить мои статьи о #Blockchain, #DataScience, #MachineLearning и #Growth.
Спасибо, что прочитали эту статью! Если вы хотите поддержать меня, вы можете сделать это следующим образом:
1. Подпишитесь на меня здесь, на Medium или в Twitter, Instagram, TikTok или YouTube.
2. Подпишитесь на статью.
> 3. Оставьте короткий комментарий
Я очень ценю любую поддержку! Каждое ваше взаимодействие с контентом поможет мне расти и со временем предоставлять более качественный контент. 🚀
Спасибо, vegxcodes
Больше контента на plainenglish.io. Подпишитесь на нашу бесплатную еженедельную рассылку новостей. Получите эксклюзивный доступ к возможностям написания и советам в нашем сообществе Discord.