
В этой серии статей я постараюсь познакомить вас с обязательными библиотеками, если вы собираетесь использовать Python и будете работать с данными и/или машинным обучением. Стек будет разделен на две основные части, первая часть будет посвящена библиотекам, которые позволят вам работать с данными, манипулировать ими и визуализировать их. Во второй части мы рассмотрим библиотеки и фреймворки для машинного обучения.
Все, что связано с машинным обучением и данными, — это процесс, который, без сомнения, в значительной степени зависит от вычислительной мощности. Вам нужно сделать векторизацию, трансляцию (мы доберемся до этого чуть позже) и работать с тензорами (которые являются просто матрицами на стероидах). Таким образом, NumPy, написанный в основном на C, обеспечивает вычислительную мощность, необходимую для этих операций, для Python. Это в значительной степени подходящая библиотека для выполнения любой вычислительной работы и манипулирования данными в Python. Независимо от того, хотите ли вы заниматься трансляцией, индексированием или более амбициозной задачей, например, написать алгоритм машинного обучения с нуля, NumPy — это ответ. Давайте взглянем на фрагмент кода, в котором мы используем встроенный в Python модуль random и NumPy для генерации 10 миллионов случайных целых чисел, и посмотрим, сколько времени потребуется для их запуска, а затем посмотрим на результаты. Я буду использовать timeit, чтобы узнать, сколько времени требуется для выполнения каждой строки кода.
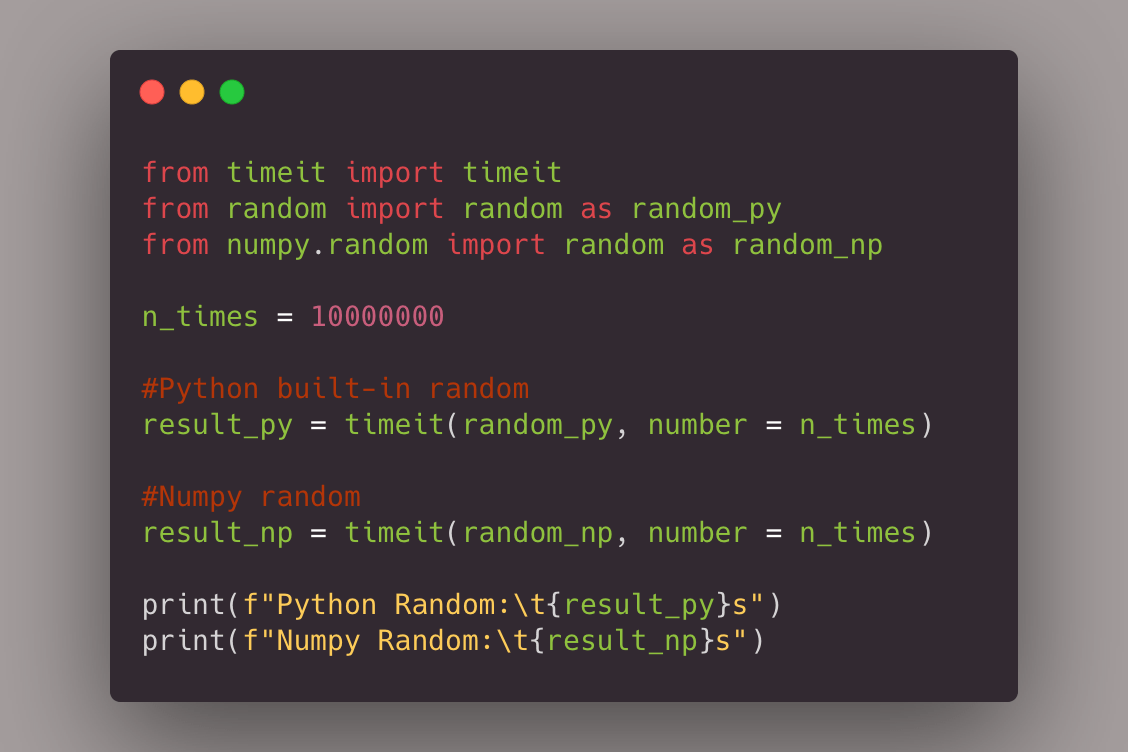

Как видите, Python побеждает в этом раунде, будучи примерно в 7 раз быстрее, чем NumPy. Теперь давайте посмотрим, что происходит, когда мы пытаемся сгенерировать не целые числа, а массив случайных значений. Это самая важная часть, поскольку вы почти всегда будете работать с массивами.


Ну-ну-ну, как вертушки…. Похоже, на этот раз NumPy работает в 8 раз быстрее. Это связано с тем, что NumPy обрабатывает эти операции многопоточным образом и при добавлении скорости, которую он получает от написания в основном на C, становится незаменимым инструментом для работы с массивами.
Почему все используют NumPy?
NumPy предоставляет вам огромный выбор быстрых и эффективных способов создания массивов и манипулирования числовыми данными внутри них. Хотя список Python может содержать разные типы данных в одном списке, все элементы в массиве NumPy должны быть однородными. Математические операции, предназначенные для выполнения над массивами, были бы крайне неэффективны, если бы массивы не были однородными. Массивы NumPy быстрее и компактнее, чем списки Python. Массив потребляет меньше памяти и удобен в использовании. NumPy использует гораздо меньше памяти для хранения данных и предоставляет механизм указания типов данных. Это позволяет еще больше оптимизировать код.
Что делает NumPy настолько хорошим для работы с массивами
- Массивы Numpy должны содержать только один тип данных, что делает их действительно удобными для памяти и простыми в обработке.
- NumPy выполняет эти вычисления в многопоточном режиме, разделяя свои операции между всеми доступными ядрами на вашем компьютере, что существенно сокращает время, необходимое для завершения. Он изначально работает на вашем ЦП и обычно не имеет поддержки графического процессора, если у вас нет графического процессора с поддержкой CUDA, который вы можете использовать для выполнения аналогичных вычислений, которые вы обычно выполняете на ЦП. По этой причине большинство (если не все) платформ машинного обучения, особенно если вы выполняете сериализацию и многопоточные операции, работают на графических процессорах, но мы вернемся к ним в следующих статьях.
- NumPy в основном написан на C, что делает его быстрее с самого начала, поскольку код C компилируется перед запуском.
- Однако будьте осторожны, есть некоторые методы, которые не являются многопоточными и написаны/реализованы на простом C (т.е. np.mean()).
Объяснение векторизации и широковещания
Векторизация
Когда ваш код или вычисления с массивами выполняются скалярно, вы можете представить, что они обрабатываются процессором в одной строке. Векторизация дает вам возможность использовать незанятую вычислительную мощность, которая не используется, и дает вашему коду значительный прирост производительности. Внедрение векторизации — действительно важный шаг, если вы пишете алгоритм машинного обучения с нуля.
Вещание
Вещание используется NumPy, когда в вычислении используются два массива или матрицы, и их формы не совпадают. Это обрабатывается следующим образом: если одно из измерений второй матрицы/массива совпадает с размером первой матрицы/массива, то первое измерение как бы удлиняется путем копирования одних и тех же значений до тех пор, пока два измерения не совпадут. Я знаю, что это сложно выразить простым предложением, поэтому вот несколько иллюстраций из официальной документации NumPy.

Второй массив превращается в матрицу 4 на 3, каждая строка которой состоит из значений [1, 2, 3]. Затем выполняется операция сложения.
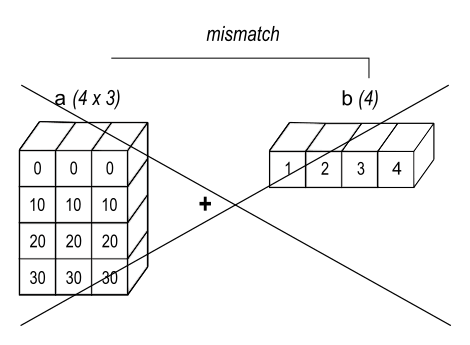
Номера столбцов 3 и 4 не совпадают, поэтому мы не можем сделать то, что делали в первом примере. Если бы второй массив имел форму (4, 1), он бы сработал.
Основы NumPy и некоторые основные функции
Создание n-мерных массивов
Вы можете создавать массивы 1D, 2D, 3D и т. д. В принципе, жестких ограничений нет, но ограничивающим фактором является архитектура аппаратного обеспечения вашей машины и ее памяти. Существуют обходные пути, которые можно реализовать, изменив тип данных или используя разреженные матрицы, в которых хранятся только ненулевые значения и их места в матрице. В конечном итоге вы сэкономите много места в долгосрочной перспективе, если у вас действительно большая разреженная матрица с большим количеством нулевых элементов.
Не пытайтесь повторить это дома
Проведем небольшой эксперимент. Я собираюсь запустить np.zeros(), который в основном генерирует матрицу с указанной вами формой, которая содержит все нули, с типом данных float64 и основным порядком столбцов, который определяет, как записи упорядочены в памяти, столбец- Major идет столбец за столбцом, а row-major идет строка за строкой. С порядком, установленным на C, вы можете ожидать лучшего времени выполнения для операций по строкам в массиве, а для F операции по столбцам выполняются быстрее.
Я пытался создать эту огромную матрицу на экземпляре colab с памятью 12,7 гигабайт.

И я наблюдал, как моя сессия рушилась со следующей ошибкой.

Итак, как видите, есть ограничения на то, что вы можете сделать, но, тем не менее, NumPy — действительно мощный инструмент.
Начальные функции NumPy
В этом разделе мы рассмотрим некоторые основные, но часто используемые функции, которые помогут вам начать работу с NumPy. Допустим, вы работаете с матрицей (5, 4) и присвоили ей имя переменной test_arr. Первое число указывает количество строк, второе — количество столбцов для вашей матрицы.
- np.ndim() — дает вам размеры вашей матрицы. test_arr.ndim выведет 2, так как это двумерная матрица.
- np.shape() — дает форму вашей матрицы 5 на 4 для test_arr
- np.size() — выводит размер заданной матрицы. Размер матрицы – это произведение количества строк и столбцов, а для test_arr – 20.
- np.append() — если в функцию передается матрица размерности 2 или выше, матрица по умолчанию сглаживается (если вы не укажете ось для добавления), а затем заданное значение добавляется в конец конец массива. Если добавленные вами значения имеют ту же длину, что и длина столбца или строки, которые были у матрицы ранее, вы можете изменить ее форму до той же формы, что и раньше, используя функцию изменения формы и передав ей (6,4) или (5,5) значения в этом случае. Или вы можете изменить его форму до любой другой формы, если размер матрицы соответствует требованиям. Вы можете использовать параметр values для передачи значений, которые будут добавлены к матрице, что обеспечит добавление новых значений в копию исходной матрицы. Вы также можете использовать параметр оси, чтобы указать ось, к которой будут добавляться значения. «1» добавит значения в новую строку, «0» добавит их в новый столбец. Имейте в виду, что использование оси для добавления потребует, чтобы форма массива, которую вы передаете для добавления, была той же формы, что и матрица, к которой вы пытаетесь добавить.
- np.insert() — Добавляет переданное значение или значения в массив перед указанным индексом. Давайте рассмотрим это на примере, чтобы вы могли лучше различать append() и insert().
Мы создали массив с именем test_arr, используя функцию нулей (что дает вам массив формы, содержащий все нули, вы также можете использовать единицы).

Давайте воспользуемся функцией вставки в test_arr. Значение 0 определяет индекс, в который будут вставлены значения 1, а значение оси 1 указывает, что значения будут вставлены в индекс 0 каждой строки.

Имейте в виду, что, поскольку мы использовали его как «np.insert» и не назначали новую переменную этой строке кода, она фактически не перезаписывала исходную переменную test_arr, и вы не можете ссылаться на результаты этой строки позже.
- np.linspace() и np.arange() — оба возвращают одномерный массив со значениями между заданными начальной и конечной точками. Эти два параметра очень похожи, но основное отличие состоит в том, что вы можете указать размер шага между двумя элементами массива в arange. Linspace определяет размер шага в соответствии с интервалом, который вы ему передаете, и следит за тем, чтобы значения были равномерно распределены.
- np.transpose() — Наконец, у нас есть функция транспонирования, которая берет столбцы заданной матрицы и превращает их в строки, изменяя форму матрицы (3, 4) на (4, 3) например.
В этом я попытался дать вам представление о том, что происходит под капотом numpy и какие преимущества они предоставляют, почему так важно иметь под рукой, и мы также изучили некоторые основные функции, чтобы вы начал использовать эту замечательную библиотеку в своем собственном коде. Я надеюсь, что это было полезно, потому что в следующих постах мы собираемся взглянуть на pandas, еще одну очень популярную библиотеку Python, которая на самом деле полагается на numpy для работы. Освоение операций с матрицами и принятие логики, лежащей в их основе, значительно облегчит вам жизнь при работе с пандами. Увидимся в следующем посте!