
Введение:
Как композитор, вы всегда будете обеспокоены тем, понравится ли ваша песня вашей аудитории или нет, поэтому мы пытаемся сделать это с помощью машинного обучения, которое предсказывает популярность песни на основе таких характеристик, как акустика. , танцевальность, тональность, громкость и т. д.
Это было соревнование по kaggle, организованное разработчиками Google и Абхишеком Тхакуром, первым в мире четырехкратным гроссмейстером kaggle. В соревновании приняли участие 535 команд, а 5 лучших игроков, занявших первые места в таблице лидеров, получили награду от Google.
Мы получили 3-е место в мире!

Постановка проблемы:
Мы должны были прогнозировать популярность песни на основе таких характеристик, как акустика, танцевальность, тональность, громкость и так далее в этом конкурсе.
Но самая сложная часть — это работа с отсутствующими значениями, поскольку данные содержат большое количество отсутствующих значений, что позволяет очень легко подогнать модель к такому набору данных. Чтобы бороться с этим, мы разработали сильную стратегию перекрестной проверки, чтобы гарантировать, что наша модель не станет переобученной.
Ограничения:
- Стоимость переобучения будет очень высока.
- Интерпретируемость важна.
- Вероятностный прогноз важен.
Обзор данных:
Данные находились в файлах train.csv, test.csv, sample_submission.csv.
- train.csv — обучающий набор содержит 40 000 строк → размер 7,54 МБ.
- test.csv — тестовый набор содержит 10 000 строк → размер 1,86 МБ.
- sample_submission.csv — образец файла отправки в правильном формате, т. е. формате, в котором мы должны отправить наш вывод в kaggle для оценки → 68,91 КБ

Сопоставление реальной проблемы с проблемой машинного обучения:
В этом тематическом исследовании нас в первую очередь интересует применение нескольких алгоритмов машинного обучения к этому набору данных, чтобы прогнозировать популярность песни.

Тип проблемы с наклоном машины
Это проблема классификации бинарного класса, в которой мы пытаемся предсказать, станет ли песня популярной 1 или нет 0. Этот набор данных был извлечен из базы данных Spotify, хотя организаторы конкурса kaggle внесли в него некоторые изменения, например, вменили некоторые отсутствующие значения и добавлены новые функции. Нам дается 50 тысяч точек данных с 14 функциями, и мы должны обучить модель на 40 тысячах точек данных и протестировать ее на оставшихся 10 тысячах точек данных.

Показатели эффективности:
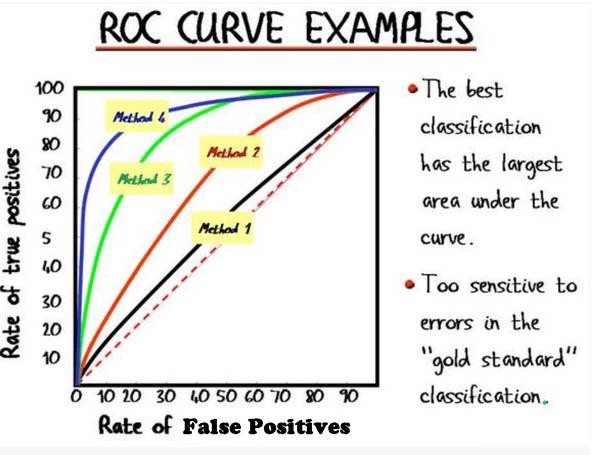
Поскольку вероятностное прогнозирование очень важно, мы должны выбирать показатели производительности с учетом этого. Кривые ROC и кривые Precision-Recall — это две основные метрики, которые мы можем использовать в двухклассовых моделях классификации. На этих графиках лучше понятен компромисс между истинно положительными показателями и ложноположительными показателями.
Эту кривую можно использовать для изучения поведения классификатора с различными пороговыми значениями и того, как оно влияет на долю истинно положительных и ложноположительных результатов.
МАСШТАБ:
Другой стратегией масштабирования является стандартизация, при которой значения центрируются вокруг среднего значения с единичным стандартным отклонением. В результате среднее значение атрибута становится равным нулю, а результирующее распределение имеет единичное стандартное отклонение.
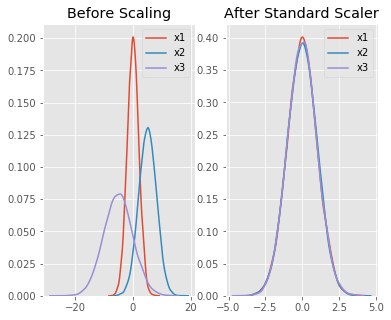
Здесь мы помещаем все функции в один масштаб
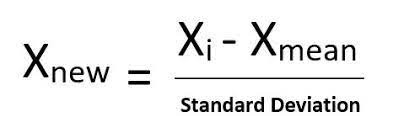
Подход
Обучающий набор данных:
Только один из 15 столбцов в наборе данных не имел значения для конкуренции (id).
Большинство столбцов в наборе данных имеют многочисленные нулевые значения. Мы заменили нулевые значения в наборе данных поезда медианным значением соответствующих столбцов. Случаи выбросов хорошо обрабатываются медианой.
Затем мы использовали StandardScaler для стандартизации набора данных поезда.
Тестовый набор данных:
Только один из 14 столбцов в тестовом наборе данных не имел значения для конкуренции (id).
Большинство столбцов в тестовом наборе данных имеют несколько нулевых значений. С соответствующими столбцами мы вменили нулевые значения в тестовом наборе данных со средним значением в наборе данных поезда.
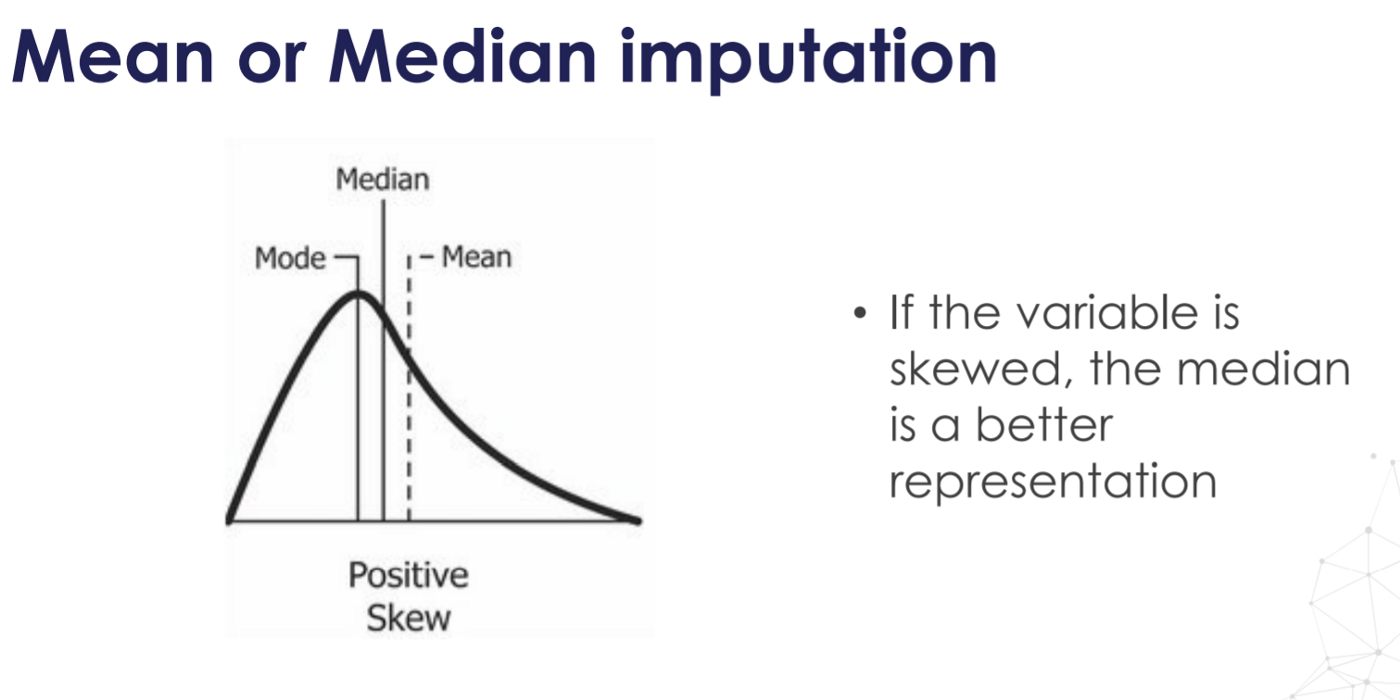
«Поскольку медиана довольно эффективно обрабатывает выбросы», вы уже знаете следующую фразу.
Затем StandardScaler использовался для стандартизации тестового набора данных.
Затем мы попробовали логистическую регрессию, случайный лес, деревья решений, дополнительное дерево, XGboost и Catboost, а также другие методы. Xgboost работал для нас лучше всего из всех подходов. Для каждой протестированной модели мы использовали GridSearchCV для настройки гиперпараметров.
Модели
Мы протестировали различные модели, в том числе D-Tree, LGBM, Random Forest, логистическую регрессию, CatBoost, модель пользовательского ансамбля, GBDT и т. д., прежде чем перейти к этой отлаженной модели XGBoost с показателем ROC-AUC 0,57653.
Дерево решений:

ЛГБМ:

Логистическая регрессия:

CatBoost:

Пользовательская модель Ensembler:

GBDT:

XGBoost:

Заключение
D-дерево, LGBM, случайный лес, логистическая регрессия, CatBoost, модель пользовательского ансамбля, GBDT и другие модели были протестированы, прежде чем остановиться на этой точно настроенной модели XGBoost с показателем ROC-AUC 0,57653. Эта модель также была наименее переобученной моделью из всего набора моделей, обученных по всему миру, что позволило нам занять третье место.
XGBoost имеет поезд AUC 0,60034.
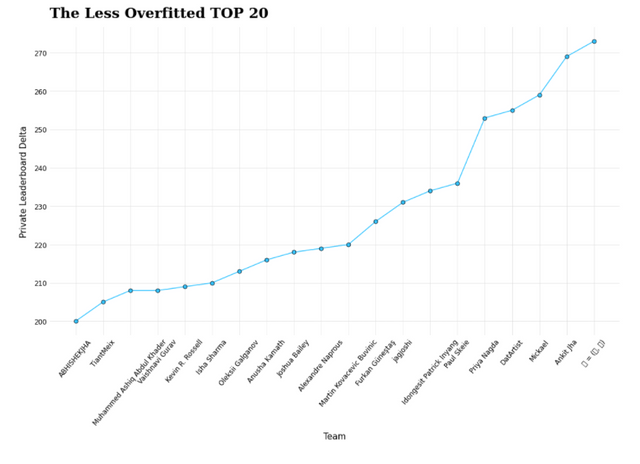
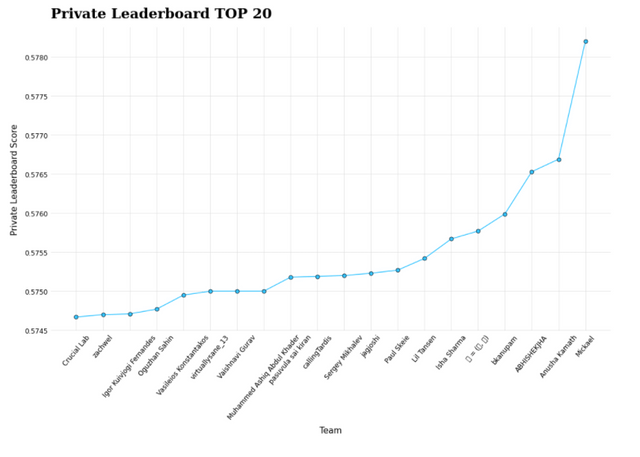
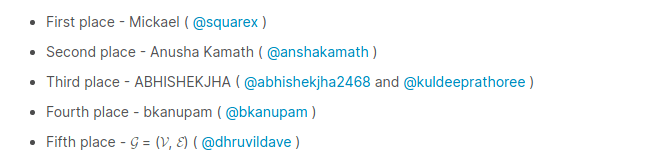
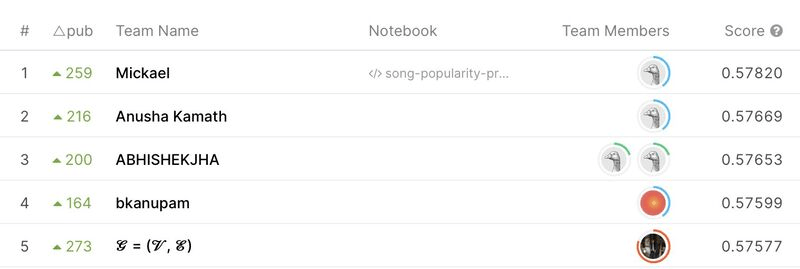
НАШИ ОЦЕНКИ ВХОДЯТ В ТОП-3 НОУТБУКА, КОТОРЫЕ БЫЛИ ПРЕДОСТАВЛЕНЫ ВО ВРЕМЯ КОНКУРСА
Источники/Полезные ссылки
ИСТОЧНИК: – Данные можно скачать из [Прогноз популярности песни].
Будущая работа
Мы можем поэкспериментировать с некоторыми другими моделями по отдельности, например, после изменения метода масштабирования на надежное масштабирование, метода выбора функций для прямого выбора функций, затем мы можем попробовать другую комбинацию моделей, чтобы найти окончательный прогноз, сопоставляя их прогнозы в соответствии с важностью отдельных модель, которая была определена их индивидуальной оценкой. Также мы можем попробовать различные методы регуляризации, чтобы предотвратить переоснащение.
Ссылки на социальные сети:-
LinkedIn:- Abhishek_Jha, Kuldeep_Rathore