Улучшите свое портфолио Data Science с помощью этих наборов данных

Изучать науку о данных непросто, как и процесс получения результатов обучения. Ваш портфель проектов по науке о данных — это то, что оценивается как результат. Понимаете ли вы процесс обработки данных, это отразится в портфолио.
Однако иногда мы не можем достичь намеченного проекта из-за недоступности данных. Во время моего обучения я знаю, что многие студенты спрашивают: «Где легко получить набор данных для нашего проекта по науке о данных?». Этот вопрос резонирует со мной, поэтому я пишу эту статью.
В этой статье я хочу поделиться своим лучшим пакетом Python для получения наборов данных. Давайте углубимся в это.
1. Seaborn/Scikit-Learn/Statsmodels
Начните с простого, используя наш общий пакет Python для обработки данных: Seaborn, Scikit-Learn и Statsmodels. Эти три пакета по своей сути имеют разное удобство использования, но у них есть общие черты — встроенный набор данных. Давайте посмотрим на каждый набор данных в этих пакетах.
Сиборн
Seaborn — это пакет визуализации, в котором есть базовый набор данных, который мы могли бы использовать для экспериментов. Давайте попробуем получить список наборов данных и как его получить.
import seaborn as sns sns.get_dataset_names()

Из пакета seaborn у нас есть 19 различных наборов данных, которые мы можем изучить. Если вы хотите получить набор данных для своей среды, используйте следующую строку.
titanic = sns.load_dataset('titanic')
titanic.head()

Scikit-Learn
Scikit-Learn содержит различные API для наборов данных игрушек и реального мира, которые мы могли бы использовать для нашего эксперимента.

Для каждого отдельного набора данных существует API для загрузки этого конкретного набора данных. Например, вы можете загрузить набор данных Iris, используя следующую строку.
from sklearn.datasets import load_iris data = load_iris() data.target[[10, 25, 50]] data.keys()

Все наборы данных содержатся в словаре, где вы можете загрузить их в другую переменную для изучения.
Статсмодели
Statsmodels — это пакет Python для статистического моделирования, но этот пакет также предоставляет пользователям различные наборы данных для изучения. Доступный набор данных показан на изображении ниже.

Чтобы получить набор данных из statsmodels, мы могли бы использовать следующую строку. Например, мы возьмем набор данных Лонгли.
data = sm.datasets.longley.load_pandas() data.data

Вы можете посетить справочную страницу, чтобы получить подробную информацию о каждом наборе данных.
2. Пидатасет
Pydataset — это пакет Python, предоставляющий различные наборы данных с открытым исходным кодом. Многие наборы данных из этих пакетов — это то, что вы, возможно, уже встречали в начальных курсах по науке о данных, таких как Титаник и Ирис.
Однако это не означает, что pydataset не является хорошим пакетом набора данных. Я обнаружил, что многие наборы данных хороши для ваших первоначальных проектов.
Давайте попробуем изучить, какой набор данных мы могли бы получить. Во-первых, нам нужно установить пакет pydataset.
pip install pydataset
После успешной установки пакета нам нужно импортировать следующую строку, чтобы получить все списки наборов данных.
from pydataset import data data()

В итоге мы получаем 757 наборов данных. Это много наборов данных для изучения.
Что, если мы хотим проверить детали для каждого набора данных? Тогда мы могли бы сделать это с помощью следующей строки.
#Pass the dataset_id to the first parameter and show_doc = True
data('BJsales', show_doc=True)

Вся информация о наборе данных находится в пределах вашей досягаемости и полезна. Теперь нам нужно только получить набор данных со следующей строкой.
bjsales = data('BJsales')
bjsales.head()

Pydataset очень прост в использовании и интуитивно понятен. Однако вам может понадобиться нечто большее, чем базовые наборы данных. Итак, давайте рассмотрим другие пакеты.
3. НЛТК
NLTK — это пакет Python, специально предназначенный для обработки естественного языка. Он предоставляет различные API-интерфейсы для текстовых задач. Для нашего использования NLTK также предоставляет набор текстовых данных, который мы можем использовать для наших проектов.
Мы можем использовать около 111 наборов текстовых данных из NLTK. Полный список смотрите на этой странице. Давайте попробуем получить набор данных из NLTK.
import nltk
# Download the abc corpus
nltk.download('abc')

Теперь набор данных загружен и готов к использованию нами. Мы могли бы использовать следующую строку для доступа к данным в целях исследования.
abc.words()

Список слов теперь доступен. Другие наборы данных содержат больше данных, чем просто слова, поэтому исследуйте их в соответствии со своими потребностями.
4. Наборы данных
Наборы данных — это пакет Python от HuggingFace, созданный специально для доступа и обмена наборами данных. Пакеты наборов данных были предназначены для быстрого получения данных обработки естественного языка (NLP), компьютерного зрения и звуковых задач, особенно для моделирования глубокого обучения.
Что хорошего в пакете Dataset, так это то, что независимо от того, насколько велик набор данных, вы можете обрабатывать набор данных с чтением с нулевым копированием без каких-либо ограничений памяти, поскольку Dataset использует Apache Arrow в фоновом режиме. Полный список из 2600+ наборов данных можно посмотреть в концентраторе данных HuggingFace.
Давайте попробуем загрузить образец набора данных с помощью пакета Datasets. Во-первых, нам нужно установить пакет.
pip install datasets
Для начала нам нужно решить, какие наборы данных мы хотим загрузить в нашу среду. После того, как вы узнали, какой набор данных вам нужен, давайте воспользуемся следующей строкой, чтобы прочитать информацию о метаданных набора данных.
from datasets import load_dataset_builder
#I want the IMDB dataset
dataset_builder = load_dataset_builder('imdb')

Используя функцию load_dataset_builder, мы могли бы вывести функции набора данных и доступное конкретное подмножество набора данных.
print(dataset_builder.info.features)

print(dataset_builder.info.splits)

Мы могли бы получить функции набора данных («текст», «метка») и доступное подмножество («обучение», «тест», «неконтролируемый»). Кроме того, каждый вывод содержит более подробную информацию.
Попробуем загрузить набор данных. Мы будем использовать следующие строки для загрузки данных IMDB.
from datasets import load_dataset
#We load the train dataset subset from IMDB dataset
dataset = load_dataset('imdb', split='train')
Приведенная выше строка позволит нам получить данные о поездах из IMDB. Давайте посмотрим полную информацию о наборе данных.
print(dataset.info)

Мы также можем получить доступ к именам столбцов, используя следующие строки.
dataset.column_names
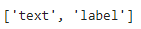
Если мы хотим более подробно изучить набор данных, мы всегда можем получить доступ к набору данных, аналогичному API Pandas. Например, если я хочу получить доступ к первым данным из набора данных IMDB, я бы использовал подмножество с нулевой индексацией.
dataset[0]

Или, если мы хотим получить доступ к манерам столбцов, нам нужно только выбрать набор данных с именем функций. Когда мы выбираем по признаку, сам набор данных будет объектом списка, поэтому мы можем выбрать его дальше с нулевой индексацией.
dataset['text'][0]

Вы можете использовать следующую страницу, чтобы узнать больше об использовании пакета Datasets.
5. Наборы открытых данных
Opendatasets — это пакет Python для загрузки набора данных из онлайн-источников, особенно Kaggle и Google Drive. Кроме того, наборы открытых данных предоставляют различные наборы данных, которые мы могли бы использовать из пакета.
Чтобы начать загрузку набора данных из Kaggle Datasets, нам нужно войти на веб-сайт Kaggle и получить API. Из API в разделе Kaggle вы получите файл kaggle.json, содержащий ваше имя пользователя и ключ.
{"username":"YOUR_KAGGLE_USERNAME","key":"YOUR_KAGGLE_KEY"}
Начнем с установки пакета. Мы будем использовать следующую строку для установки Opendatasets.
pip install opendatasets
Чтобы начать загрузку набора данных из Kaggle, нам нужно найти набор данных ссылок, который вы хотите получить. В этом примере я бы попытался загрузить набор данных о выборах в США с Kaggle.
import opendatasets as od
od.download('https://www.kaggle.com/tunguz/us-elections-dataset'

Вам необходимо указать свое имя пользователя и ключ Kaggle перед началом процесса загрузки. Папка набора данных будет находиться в вашем пути к каталогу Jupyter Notebook.
Кроме того, доступны встроенные наборы данных для загрузки из пакета Opendatasets. На изображении ниже представлен набор данных, который вы можете получить.

od.download('stackoverflow-developer-survey-2020')

Загруженный набор данных также будет доступен в вашем каталоге.
Заключение
Каждый проект по науке о данных требует правильного набора данных для работы. Без набора данных мы не можем вести наш проект данных. В этой статье я хочу рассказать о своих лучших пакетах Python для получения наборов данных. Пакеты:
- Seaborn/Scikit-Learn/Statsmodels
- набор данных
- НЛТК
- Наборы данных
- Наборы открытых данных
Я надеюсь, что это помогает!
Посетите меня в моем LinkedIn или Twitter.
Не пропустите мои материалы и получите более глубокие знания о данных, чтобы улучшить свою карьеру в науке о данных, подписавшись на мою новостную рассылку здесь
Если вы не подписаны как участник Medium, рассмотрите возможность подписки через моего реферала.