Превратите информацию из фрейма данных в фрейм данных и создайте гистограмму

Некоторые данные просто важнее других. С тех пор, как я начал изучать науку о данных как профессию, у меня в голове возник мучительный вопрос: почему так мало женщин были рядом со мной в этом исследовании. Я по-разному спрашивал друзей, почему они выбрали свою профессию. Среди моих друзей есть учителя, юристы, финансисты и другие профессии. И среди всех них я не нашел ни одной основной причины того, почему их карьера увела их от роли специалиста по данным.
В рамках изучения этого вопроса я оцениваю данные для построения модели. При этом я хотел бы начать с изучения общедоступных наборов данных по полу. Я хочу изучить различные факторы и ключевые различия между мужчинами и женщинами, занимающимися данными.
Мое исследование данных в конечном итоге превратится в прогнозное моделирование. Набор данных должен соответствовать минимальным условиям, чтобы его можно было считать существенным для построения моделей/машинного обучения. К ним относятся:
- переменные-предикторы имеют линейную связь с переменными результата. Другими словами, вызывает ли x результат y?
- данные нормально распределены. Графики гистограммы и нахождение распределения в форме колокола являются ключом к этому условию.
- Баланс данных
Что такое сбалансированные данные?
Для целей этого проекта данных нас интересует пол и ключевые факторы, которые помогают определить карьеру специалиста по данным между мужчинами и женщинами. В сбалансированном наборе данных выборочная совокупность в наборе данных будет иметь соотношение мужчин и женщин, занимающихся данными, такое же соотношение, как и общее число ученых, занимающихся данными. Кроме того, чтобы данные были сбалансированными, каждая из других переменных, кроме пола, должна иметь ненулевую запись.
Давайте продолжим и изучим этот набор данных Kaggle, который я нашел относительно удовлетворенности работой среди специалистов по данным:
import pandas as pd
df=pd.read_csv('/data_science.csv')
df.info()

Глядя на информацию из фрейма данных, я вижу, что этот набор данных для изучения пола проблематичен. Отсутствует значительное количество гендерных записей. Когда я подустанавливаю пол:
female=df[df['gender']=='Female'] female.info()
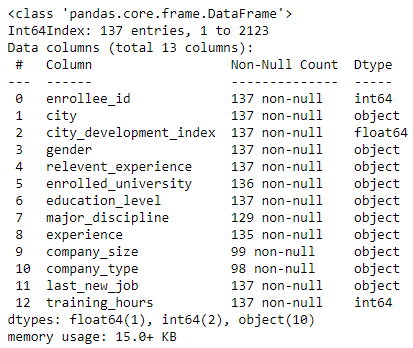
У нас есть колоссальные 137 записей из более чем 2000 из исходного фрейма данных.
Теперь, хотя это может показаться абсолютным, давайте предположим, что это соотношение женщин и мужчин 64: 1000 отражало численность населения. В этом случае данные будут считаться сбалансированными. Бывают рабочие дни, когда я просто хочу включить на повторе последний ремастированный альбом Т. Свифта. В такие дни соотношение 64:1000 может показаться довольно точным.
Теперь давайте посмотрим на общий баланс переменных фрейма данных:
import io buf = io.StringIO() df.info(buf=buf) s = buf.getvalue() lines = [line.split() for line in s.splitlines()[3:-2]] pd.DataFrame(lines) df_info=pd.DataFrame(lines) df_info.columns=df_info.iloc[0] df_info=df_info[2:] df_info['Non-Null']=df_info['Non-Null'].astype(int) df_info

Выше мы видим, что пакет io превратил информацию в строку, затем разделил эти строки и ввел их в фрейм данных с именем df_info.
Оттуда оператор iloc находит правильные заголовки и обрезает лишнюю строку данных, которая является пустой между заголовками и первой строкой данных. Затем мы конвертируем количество «Non-Null» в целое число, чтобы создать нашу визуализацию. Ниже приведен код для создания гистограммы.
import seaborn as sns
import matplotlib.pyplot as plt
chart=plt.figure(figsize=(9, 15))
sns.barplot(x="Non-Null", y="Column", data=df_info, palette=sns.color_palette("mako"))
plt.xticks( rotation='vertical')

Выше вы можете увидеть визуализацию, которая четко определяет количество записей для каждого столбца в фрейме данных. Если бы пол, размер и тип компании интересовали нас больше, чем какие-либо другие факторы в этом фрейме данных, было бы рекомендовано обрезать набор данных, чтобы включить сбалансированный набор данных в целом.
Женщины, составляющие 6,4% населения, могут быть не идеальным набором данных для изучения женщин в науке о данных. В примере данных, использованном выше, была значительно меньшая выборка из интересующей совокупности, чем хотелось бы. Часто для поиска этих нишевых результатов требуется значительно больший набор данных, что само по себе создает проблемы. Тем не менее, принятие мер по всестороннему изучению данных означает получение в целом более надежного набора выводов.
Ссылки:
Хотит ли сотрудник остаться или нет, анализ данныхEkaanshhttps://www.kaggle.com/code/ekaansh/does-employee-wants-to-stay-or-not- анализ данных/данные
Дополнительные материалы на PlainEnglish.io. Подпишитесь на нашу бесплатную еженедельную рассылку новостей. Подпишитесь на нас в Twitter и LinkedIn. Посетите наш Community Discord и присоединитесь к нашему Коллективу талантов.