Эта статья изначально была опубликована в блоге Encord, который вы можете прочитать здесь.

Эрик Ландау
При создании моделей ИИ инженеры по машинному обучению сталкиваются с двумя проблемами в отношении маркировки обучающих данных: проблемой количества и проблемой качества.
Долгое время инженеры по машинному обучению застревали на проблеме количества. Модели контролируемого машинного обучения нуждаются в большом количестве помеченных данных, и производительность модели зависит от наличия достаточного количества помеченных обучающих данных, чтобы охватить все различные типы сценариев и пограничных случаев, с которыми модель может столкнуться в реальном мире. По мере того как они получали доступ ко все большему количеству данных, командам машинного обучения приходилось искать способы их эффективной маркировки.
В последние несколько лет эти команды начали находить решения этой проблемы с количеством — либо путем найма больших групп людей для аннотирования данных, либо путем более систематического использования новых инструментов, которые автоматизируют процесс и создают множество меток. .
К сожалению, проблема качества стала по-настоящему проявляться только тогда, когда появились решения проблемы количества. Решение проблемы количества сначала имело смысл — в конце концов, первое, что вам нужно для обучения модели, — это множество помеченных обучающих данных. Однако после обучения модели на этих данных довольно быстро становится очевидным, что качество работы модели зависит не только от количества обучающих данных, но и от качества аннотаций к этим данным.
Проблема качества обучающих данных
Проблемы с качеством данных возникают по ряду причин. Качество самих обучающих данных зависит от наличия надежного конвейера для поиска, очистки и организации данных, чтобы убедиться, что ваша модель не обучена на дублирующихся, поврежденных или нерелевантных данных. После создания надежного конвейера для поиска и управления данными команды машинного обучения должны быть уверены, что метки, идентифицирующие функции в данных, не содержат ошибок.
Это непростая задача, потому что ошибки в аннотациях данных возникают из-за человеческих ошибок, и причины этих ошибок столь же разнообразны, как и сами люди-аннотаторы. Все аннотаторы могут ошибаться, особенно если они занимаются маркировкой по восемь часов в день. Иногда аннотаторы не обладают знаниями в предметной области, необходимыми для точной маркировки данных. Иногда они не были обучены должным образом для выполнения поставленной задачи. В других случаях они не добросовестны и не последовательны: они либо невнимательны, либо не обучены передовым методам аннотирования данных.

Независимо от причины, плохая маркировка данных может привести ко всем типам ошибок модели. Например, если модели обучались на неточно размеченных данных, они могут совершать ошибки неправильной категоризации, например ошибочно принимать лошадь за корову. Или при обучении на данных, где ограничивающие рамки не были плотно нарисованы вокруг объекта, модели могут допускать геометрические ошибки, например неспособность отличить целевой объект от фона или других объектов в кадре. Недавнее исследование показало, что 10 из наиболее цитируемых наборов данных ИИ имеют серьезные ошибки маркировки: знаменитый тестовый набор ImageNet имеет предполагаемую ошибку маркировки 5,8 процента.
Когда у вас есть ошибки в ваших метках, ваша модель страдает, потому что учится на неверной информации. Когда дело доходит до случаев использования, где существует высокая чувствительность к ошибкам в отношении последствий ошибки модели, таких как автономные транспортные средства и медицинская диагностика, метки должны быть конкретными и точными - для таких типов ошибок маркировки нет места. или некачественные данные. В этих ситуациях, когда модель должна работать с точностью 99,99%, небольшие запасы в ее производительности действительно имеют значение.
Снижение производительности модели из-за низкого качества данных — коварная проблема, потому что инженеры по машинному обучению часто не знают, в чем проблема — в модели или в данных. Они могут пустить пыль в глаза, пытаясь улучшить модель, только для того, чтобы понять, что модель никогда не улучшится, потому что проблема заключалась в самих ярлыках. Использование подхода к ИИ, ориентированного на данные, а не на модель, может облегчить некоторые головные боли. В конце концов, такого рода проблемы лучше всего сначала решать путем повышения качества самих обучающих данных, прежде чем пытаться улучшить качество модели. Однако ИИ, ориентированный на данные, не сможет раскрыть свой потенциал, пока мы не решим проблему качества данных.
В настоящее время обеспечение качества данных зависит от интенсивных процессов проверки, выполняемых вручную. Этот подход к качеству является проблематичным и не масштабируемым, поскольку объем данных, которые необходимо проверить, намного превышает количество доступных рецензентов. И рецензенты тоже допускают ошибки, так что во всей цепочке маркировки присутствует человеческая непоследовательность. Чтобы исправить эти ошибки, компания может попросить нескольких рецензентов просмотреть одни и те же данные, но теперь стоимость и рабочая нагрузка удвоились, поэтому это неэффективное и экономичное решение.
Полностью автоматизированный инструмент Encord для оценки качества данных и маркировки
Когда мы начинали Encord, мы были сосредоточены на проблеме количества. Мы хотели решить человеческое узкое место в маркировке данных, автоматизировав процесс. Однако после разговора со многими специалистами по ИИ, особенно в более сложных компаниях, мы быстро поняли, что они застряли на проблеме качества. Из этих разговоров мы решили обратить внимание и на решение проблемы качества данных. Мы поняли, что проблема количества будет по-настоящему решена только в том случае, если мы поумнеем в обеспечении того, чтобы объем данных, поступающих в банк, также был данными высокого качества.
Компания Encord создала и запустила первый полностью автоматизированный инструмент для оценки качества этикеток и данных для машинного обучения. Этот инструмент заменяет ручной процесс, который делает разработку ИИ дорогой, трудоемкой и сложной для масштабирования.
Краткий обзор инструмента оценки качества данных
В рамках платформы Encord мы разработали функцию контроля качества, которая выявляет вероятные ошибки в проекте клиента с помощью алгоритма полуконтролируемого обучения. Клиент выбирает из проекта все метки и объекты, которые хочет проверить, запускает алгоритм, а затем получает автоматическое ранжирование меток по вероятности ошибки.
Каждая этикетка получает оценку, поэтому вместо того, чтобы проверять качество каждой отдельной этикетки, они могут использовать алгоритм для интеллектуального отбора данных для проверки человеком.
Оценка отражает, будет ли этикетка высокого или низкого качества. Клиент может установить порог, чтобы отправлять все, что выше определенного балла, в модель и отправлять все, что ниже определенного балла, на проверку вручную. Затем человек может принять или отвергнуть ярлык в зависимости от его качества. Люди все еще в курсе, но инструмент оценки качества данных экономит им как можно больше времени, используя их время эффективно и тогда, когда это наиболее важно.
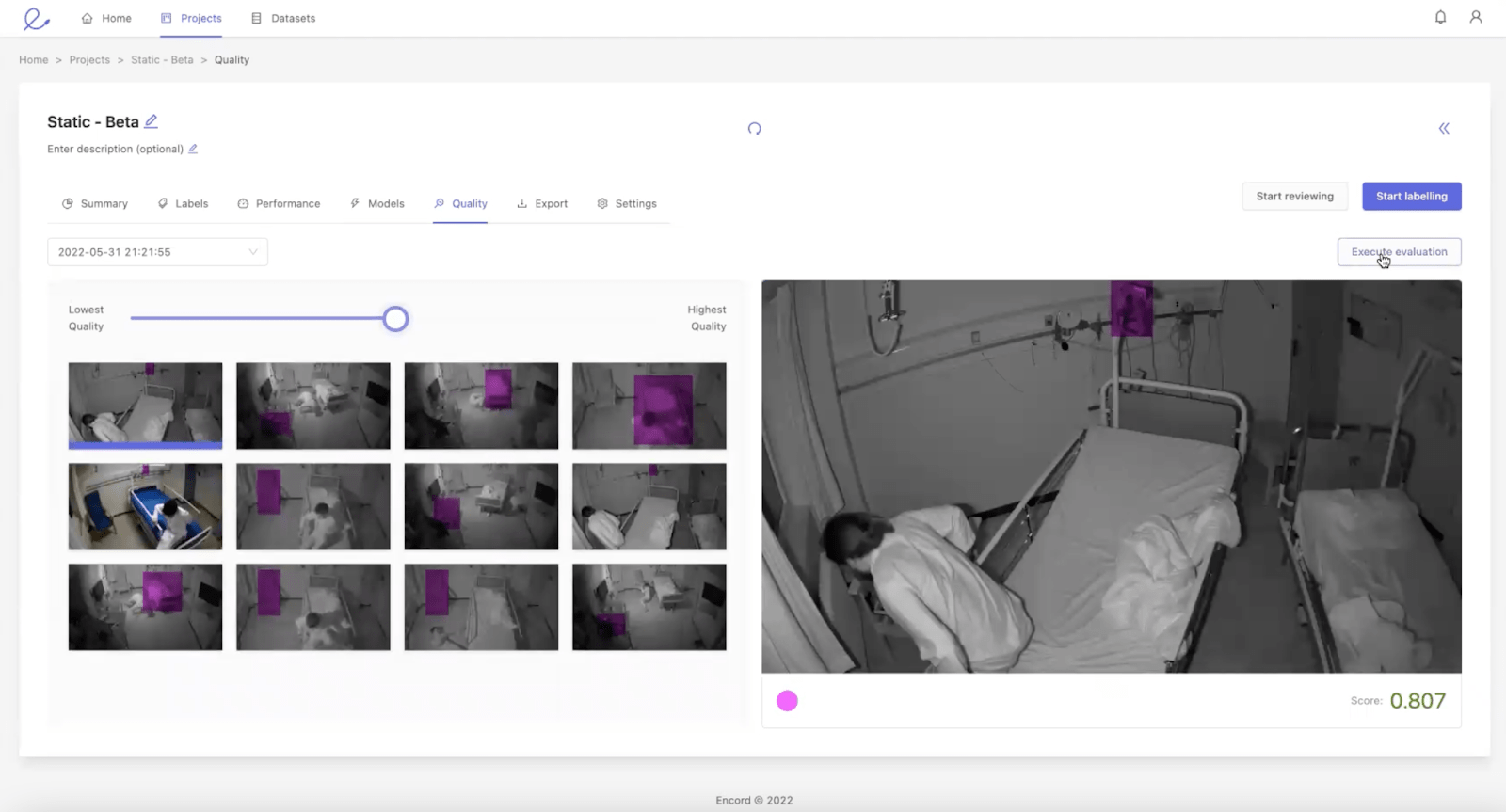
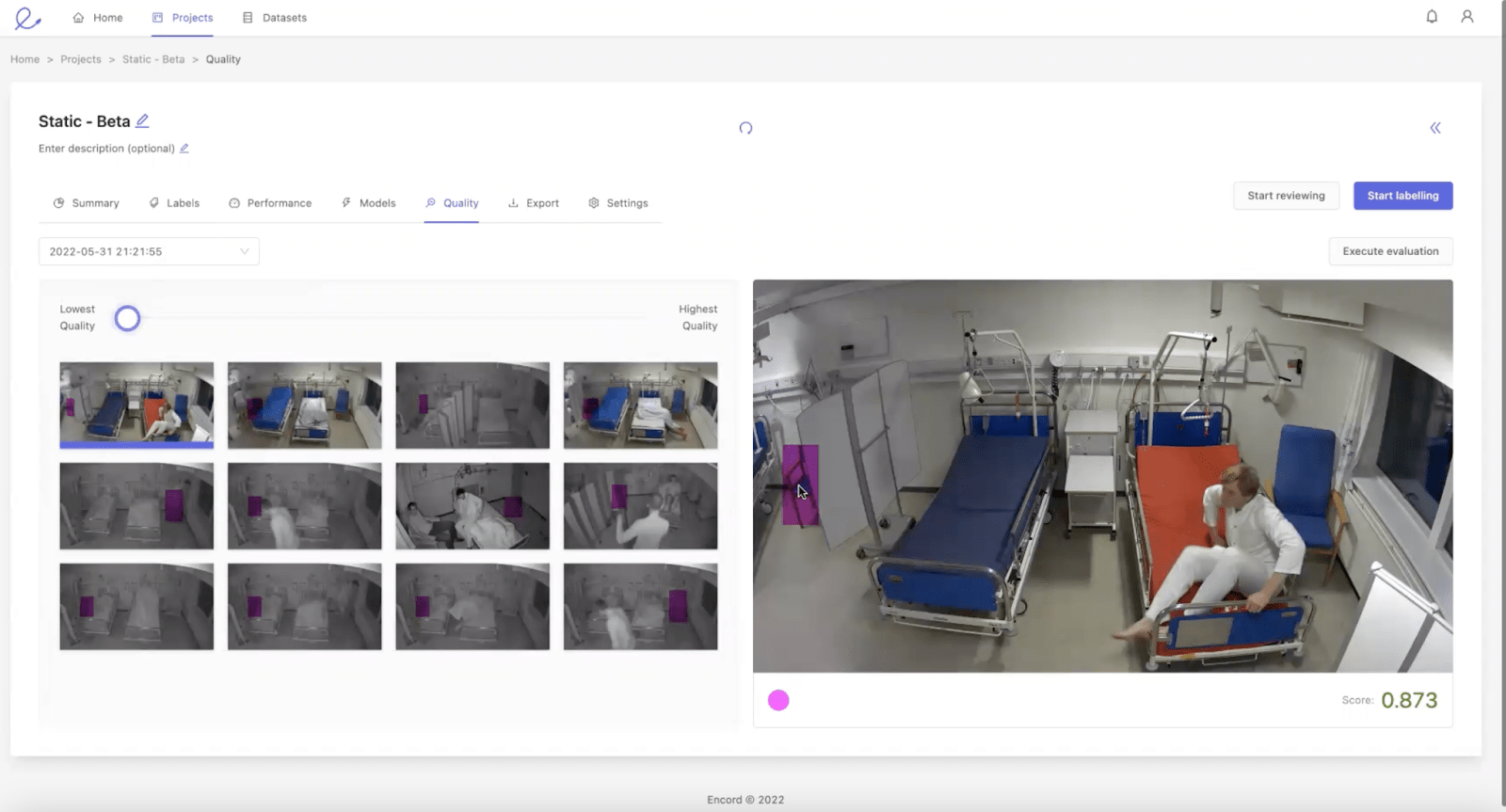
В приведенном ниже примере клиент аннотировал различные объекты в комнате. Ограничивающая рамка на изображении должна обозначать стул, но она не прилегает к стулу и пропускает часть объекта. Это ярлык, который рецензент может захотеть проверить, чтобы увидеть, можно ли его улучшить. Его оценка составляет 0,873, поэтому, если порог был установлен на 0,90 или выше, этот ярлык будет автоматически отправлен на проверку. Он никогда не попал бы в модель, если бы его не передал человек.
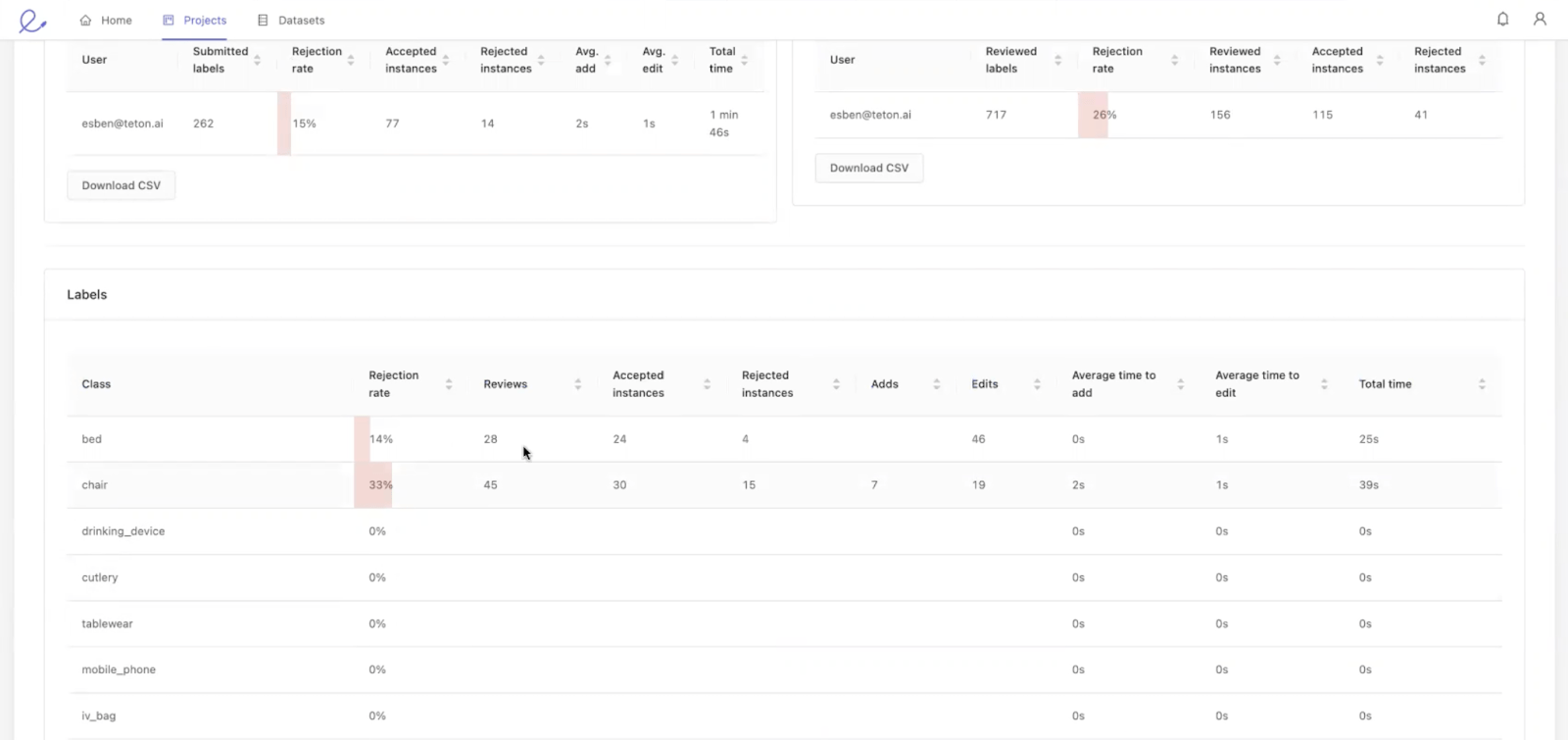
Инструмент также собирает статистические данные о частоте отказа людей от различных предметов, поэтому группы машинного обучения могут лучше понять, как часто люди отвергают определенные ярлыки. Обладая этой информацией, они могут сосредоточиться на улучшении маркировки более сложных объектов. В приведенном ниже примере кровати и стулья имеют самый высокий процент отказов.
В настоящее время этот инструмент работает с обнаружением объектов, потому что это самая большая потребность среди наших клиентов, но в настоящее время мы работаем над новаторскими исследованиями, чтобы заставить его работать и для других задач компьютерного зрения, таких как сегментация.
Повышение эффективности: сочетание автоматической маркировки данных с инструментом оценки качества данных
Платформа Encord позволяет создавать метки вручную и с помощью автоматизации (например, с помощью интерполяции, отслеживания или использования нашей собственной маркировки с помощью моделей). Он также позволяет импортировать прогнозы моделей через наш API и Python SDK. Метки или прогнозы импортированных моделей часто проверяются вручную, чтобы убедиться, что они имеют максимально возможное качество, или для подтверждения результатов.
Однако теперь, используя наш автоматизированный инструмент оценки качества, наши клиенты могут выполнять автоматизированную проверку этикеток, созданных вышеупомянутыми различными агентами этикетирования, без изменения каких-либо рабочих процессов и в масштабе.
Функция качества убеждает клиентов в качестве машинно-генерируемых этикеток. Фактически, наша платформа собирает информацию, чтобы показать, какие агенты создания меток — из группы аннотаторов-человеков, группы импортированных меток и группы автоматически создаваемых меток — работают лучше всего. Другими словами, инструмент не различает метки, созданные человеком, и метки, созданные моделью, при ранжировании меток в наборе данных. В результате эта функция помогает повысить уверенность в использовании нескольких различных методов создания меток для получения высококачественных обучающих данных.
Благодаря автоматическому созданию этикеток с использованием микромоделей и автоматизированному инструменту оценки качества данных Encord максимально оптимизирует время, затрачиваемое на участие человека в процессе. При этом мы можем дорожить временем людей, используя его только для самого необходимого и значимого вклада в машинное обучение.
Команды машинного обучения и обработки данных любого размера используют приложения Encord для совместной работы, функции автоматизации и API-интерфейсы для создания моделей, аннотирования, управления и оценки своих наборов данных. Загляните к нам здесь.