
(Часть I) Рабочий процесс машинного обучения, ориентированный на многоканальное развертывание, для моделей качества захвата на устройстве
Эдвард Ли, старший менеджер по компьютерному зрению
Чтобы проекты машинного обучения были успешными, крайне важно иметь правильный тип рабочего процесса, чтобы максимизировать эффективность команды и увеличить скорость итераций, одновременно устраняя блокираторы и потенциальные проблемы как можно раньше. В этой серии из двух частей мы подробно рассмотрим традиционный рабочий процесс машинного обучения и рассмотрим, какие изменения наша команда добавила в этот традиционный процесс, чтобы облегчить развертывание нашей модели качества захвата на устройстве.
Обобщить:
- В первой части мы обсудим традиционный рабочий процесс машинного обучения.
- Во второй части мы рассмотрим модифицированный рабочий процесс Omni Channel и углубимся в изменения, которые мы вносим в рабочий процесс Omni Channel, чтобы развернуть нашу модель качества захвата на устройстве.
Часть I. Традиционный рабочий процесс машинного обучения
Традиционный рабочий процесс машинного обучения (рис. 1) состоит из нескольких отдельных этапов, от определения масштаба проекта до развертывания модели. Есть некоторые важные вещи, которые мы учитываем на каждом этапе:
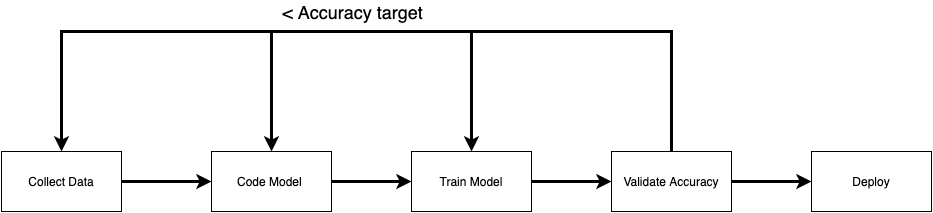
1. Определение масштаба проекта
2. Курирование набора данных
3. Обучение модели и экспериментирование
4. Развертывание модели
Обзор проекта
Проект начинается с понимания проблемы, а затем определения объема работ таким образом, чтобы решение было выполнимым с учетом определенных ограничений точности или производительности. При определении объема необходимо учитывать множество разных факторов, в том числе: как получить данные, какова желаемая цель модели, требуемая продолжительность цикла разработки и как эта модель вписывается в продукт. Объем проекта — это баланс между осуществимостью, сроками и влиянием функций, чтобы мы решали проблему, которая максимизирует продукт. Например, детектор удостоверений личности, который может точно найти четыре угла объекта, похожего на удостоверение личности, является гораздо более простой задачей, чем модель, которая одновременно обнаруживает углы и различает разные типы удостоверений личности. Правильное определение масштаба проекта значительно снижает риск и повышает качество и скорость итераций.
Курирование набора данных
После определения объема курирование набора данных является одним из наиболее важных этапов рабочего процесса машинного обучения. На этом этапе мы собираем все необходимые наборы данных и соответствующие метки (если они есть). Набор обучающих данных напрямую определяет производительность и охват вашей модели. Наличие репрезентативного высококачественного набора данных напрямую влияет на эффективность продукта. Есть несколько вещей, которые следует учитывать на этом этапе, в зависимости от конкретных ситуаций. Во-первых, это разнообразие данных: это очень сложная проблема, поскольку наборы данных могут по своей природе содержать смещения в распределении, и такие смещения могут привести к тому, что модели, обученные на основе этих наборов данных, будут плохо обобщать.
Во-вторых, доступность меток: может быть сложно получить маркированные данные, поскольку трудно маркировать данные с приемлемой скоростью и качеством (например, оценка глубины). В других ситуациях может оказаться невозможным пометить каждую выборку данных вручную. В этих случаях жесткий анализ меток может помочь создать огромное количество меток в ущерб качеству (мы поговорим об этом в следующем посте в блоге).
Наконец, на этом этапе важно подумать о наборе данных для тестирования/проверки, который репрезентативен для реальных вариантов использования и может использоваться для измерения производительности модели и облегчения сравнения с предыдущими методами.
Обучение моделей и эксперименты
Теперь, когда у нас есть набор данных для обучения, мы хотим начать проводить некоторые эксперименты, чтобы проверить наши идеи. Этот процесс очень итеративный и может длиться месяцами в зависимости от масштаба проекта. Таким образом, на этом этапе мы применяем научный метод (да, тот, что был в старшей школе).
- Разработка модели — это накопление нескольких проверенных гипотез. Например, может ли архитектура resnet-50 научиться классифицировать данные моего документа?
- Является ли Адам лучшим оптимизатором для моей архитектуры?
- Какая функция активации даст мне лучший результат?
Понятно, что на некоторые вопросы ответить легче, чем на другие, и некоторые интуитивные догадки подсказывают нам комбинации различных компонентов, которые, как мы знаем, хорошо работают вместе, например свертка с пакетной нормой. Тем не менее, эмпирическое правило состоит в том, чтобы разбить эксперимент на небольшие простые фрагменты, чтобы мы могли проверить отдельные изменения, которые мы внесли в нашу модель или процесс обучения (например, elu вместо relu; или resnet50 против resnet100; или пакетная норма перед сверткой). против после). Каждое из этих изменений представляет собой эксперимент, результаты которого подтверждаются нашим проверочным набором данных на этапе курирования набора данных.
Каждый из экспериментов должен иметь версионный код (git commit/Pull request/Merge request) и запись в трекере экспериментов, такую как тензорная доска или веса и смещения, которые детализируют точные конфигурации и гиперпараметры, в дополнение к версионным наборам данных. Нам нужно знать, при каких именно обстоятельствах можно воспроизвести нашу модель.
Кроме того, оптимизация гиперпараметров помогает ускорить процесс экспериментирования. Еще один совет, который я могу предложить: вместо того, чтобы тренироваться на всем наборе данных с вашим первым кандидатом модели, обучите его на небольшом наборе данных, чтобы увидеть, является ли ваш кандидат модели оптимальным для решения вашего типа проблемы. Если это так, итеративно масштабируйте модель/данные, пока не сойдетесь на приемлемой модели, при необходимости внося изменения в архитектуру модели или цикл обучения. Это дополнительно помогает нам понять, как наша модель масштабируется с данными.
Если эффективность проверки модели (точность, полнота) не является оптимальной, повторите эту модель. Если вы исчерпали свои эксперименты с моделированием без улучшений, вернитесь к этапу обработки данных и улучшите свой набор данных, чтобы он был более репрезентативным.
Модели, обученные на этапе моделирования, также можно использовать для получения сложных примеров для маркировки. Во время этого процесса итерации вы также можете настроить масштаб проекта, если это необходимо.
Развертывание модели
После определения кандидата на развертывание разверните модель в соответствии с рекомендациями. Если вы столкнулись с проблемами, связанными с развертыванием или ограничениями производительности модели, работающей в производственной среде, повторите свою модель или улучшите модель/набор данных, чтобы устранить любые производственные проблемы.
Часть II
В следующем посте мы рассмотрим модифицированный рабочий процесс Omni Channel и углубимся в изменения, которые мы вносим в рабочий процесс Omni Channel, чтобы развернуть нашу модель качества захвата на устройстве.