Узнайте, как работать с библиотекой h20 с помощью языка R.

[Отказ от ответственности: этот пост содержит партнерские ссылки на мой курс Udemy]
R имеет множество библиотек машинного обучения, которые можно использовать для обучения моделей. От caret до автономных библиотек, таких как randomForest, rpart или glm, R предоставляет широкий спектр возможностей. когда вы хотите выполнить некоторые задачи по науке о данных.
Любопытная библиотека, о которой вы, возможно, никогда не слышали, называется h2o. Платформа in-memory для распределенного и масштабируемого машинного обучения h2o может работать на мощных кластерах, когда вам нужна повышенная вычислительная мощность. Другой интересный момент заключается в том, что это библиотека не только для R — например, вы также можете использовать тот же API с помощью Python.
Кроме того, h2o — очень интересная и разнообразная библиотека. Он содержит так много разнообразных функций (от обучающих моделей до возможностей automl ), что при его использовании легко немного потеряться, особенно из-за большого количества методов и функций, которые можно использовать с пакетом. . Это разнообразие функций — основная причина, по которой я написал эту запись в блоге — я хочу помочь вам ориентироваться в интерфейсе h2o!
В этом сообщении блога мы рассмотрим несколько примеров (с кодом) h2o, а именно:
- обучить пару моделей машинного обучения;
- сделать некоторую настройку гиперпараметров;
- выполнить процедуру automl;
- взгляните на модуль объяснимости;
Давайте начнем!
Загрузка данных
Для этого сообщения в блоге мы будем использовать Лондонский набор данных по совместному использованию велосипедов — этот набор данных содержит информацию о спросе на велосипеды для Лондонской программы совместного использования велосипедов. Если вы хотите узнать об этом больше, перейдите по ссылке Kaggle, чтобы проверить описание столбцов и то, как эти данные были сгенерированы.
В основном это задача обучения с учителем, где мы хотим предсказать количество новых поездок на велосипеде в час, основываясь на нескольких особенностях, касающихся дня и погоды в течение определенного часа.
Мы можем загрузить набор данных, используя read.csv R:
london_bike <- read.csv(‘./london_merged.csv’)
После загрузки данных давайте просто проверим наши типы данных. Если мы вызовем команду str для london_bike, мы увидим, что:
'data.frame': 17414 obs. of 10 variables: $ timestamp : chr "2015-01-04 00:00:00" "2015-01-04 01:00:00" "2015-01-04 02:00:00" "2015-01-04 03:00:00" ... $ cnt : int 182 138 134 72 47 46 51 75 131 301 ... $ t1 : num 3 3 2.5 2 2 2 1 1 1.5 2 ... $ t2 : num 2 2.5 2.5 2 0 2 -1 -1 -1 -0.5 ... $ hum : num 93 93 96.5 100 93 93 100 100 96.5 100 ... $ wind_speed : num 6 5 0 0 6.5 4 7 7 8 9 ... $ weather_code: num 3 1 1 1 1 1 4 4 4 3 ... $ is_holiday : num 0 0 0 0 0 0 0 0 0 0 ... $ is_weekend : num 1 1 1 1 1 1 1 1 1 1 ... $ season : num 3 3 3 3 3 3 3 3 3 3 ...
Наш фрейм данных содержит только числовые столбцы (кроме метки времени, которую мы не будем использовать) — поскольку мы хотим, чтобы алгоритмы обрабатывали weather_code и season как категориальные переменные (по крайней мере, в первом эксперименте), давайте преобразуем их в факторы:
london_bike$weather_code <- as.factor(london_bike$weather_code) london_bike$season <- as.factor(london_bike$season)
Загрузив набор данных в R, давайте разделим наши данные на две части, создав кадр поезда и тест.
Поезд-тестовый сплит
h2oимеет удобную функцию для выполнения пробных сплитов. Чтобы запустить h2orunning, нам нужно загрузить и инициализировать нашу библиотеку:
library(h2o) h2o.init()
Когда мы вводим h2o.init() , мы настраиваем локальный кластер h2o . По умолчанию h2o задействует все доступные ЦП, но вы можете указать определенное количество ЦП для инициализации с помощью nthread .
Это одно из основных отличий от других библиотек машинного обучения в R — чтобы использовать h2o, нам всегда нужно запускать кластер h2o. Преимущество заключается в том, что если у вас есть экземпляр h2o, работающий на сервере, вы можете подключиться к этому компьютеру и использовать эти вычислительные ресурсы без слишком большого изменения кода (вам нужно только указать yourinitна другой компьютер).
Используя h2o.splitFrame , мы можем удобно создать случайное разделение наших данных для обучения и тестирования, но перед этим нам нужно преобразовать наш фрейм данных в специальный объект, который h2o может распознать:
london_bike.h2o <- as.h2o(london_bike)
Первое знание: h2o не может работать с обычными фреймами данных R, а только со специальным типом объекта h2OFrame, поэтому шаг преобразования фреймов данных с использованием as.h2o является обязательным.
Теперь мы готовы выполнить тестовое разделение поезда с нашим новым объектом london_bike.h2o:
london_bike_split <- h2o.splitFrame(data = london_bike.h2o, ratios = 0.8, seed = 1234)
training_data <- london_bike_split[[1]]
test_data <- london_bike_split[[2]]
Используя h2o.splitFrame, мы можем сразу разделить наш набор данных на два разных h2o кадра — ratios определить процент, который мы хотим выделить для наших обучающих данных, и в приведенной выше функции мы используем 80% набора данных для целей обучения, оставив 20% в качестве набор задержек.
Разделив наши данные между тестом и обучением в формате h2o, мы готовы обучить нашу первую модель h2o!
Обучение модели
Из-за своей простоты первой моделью, которую мы будем обучать, будет линейная регрессия. Эту модель можно обучить с помощью функцииh2o.glm, и сначала нам нужно определить целевые и функциональные переменные:
predictors <- c("t1", "t2", "hum", "wind_speed", "weather_code",
"is_holiday","is_weekend", "season")
response <- "cnt"
Поскольку столбец cnt содержит количество велосипедов, используемых за каждый час, это столбец, который мы будем использовать для нашего ответа/цели.
Чтобы обучить модель, мы можем сделать следующее:
london_bike_model <- h2o.glm(x = predictors,
y = response,
training_frame = training_data)
Вот и все! Всего с тремя аргументами мы можем обучить нашу модель:
xопределяет имена столбцов, которые мы будем использовать в качестве функций.yопределяет целевой столбец- в аргументе
training_frameмы передаем обучающий набор данных.
Наша модель готова! Давайте сравним наши прогнозы с реальным значением в тестовом наборе — мы можем удобно использовать функцию h2o.predict, чтобы получить прогнозы из нашей модели:
test_predict <- h2o.predict(object = london_bike_model,
newdata = test_data)
objectполучает модель, которую мы хотим применить к нашим данным.newdataполучает данные, где мы будем применять модель.
И затем мы можем cbind наши прогнозы с cnt из тестового набора:
predictions_x_real <- cbind( as.data.frame(test_data$cnt), as.data.frame(test_predict) )
Мы можем быстро сравнить наши прогнозы с целью:

Очевидно, что наша модель немного превышает нашу цель — давайте применим некоторую регуляризацию внутри h2o.train с помощью параметра alpha :
london_bike_model_regularized <- h2o.glm(x = predictors,
y = response,
training_frame = training_data,
alpha = 1)
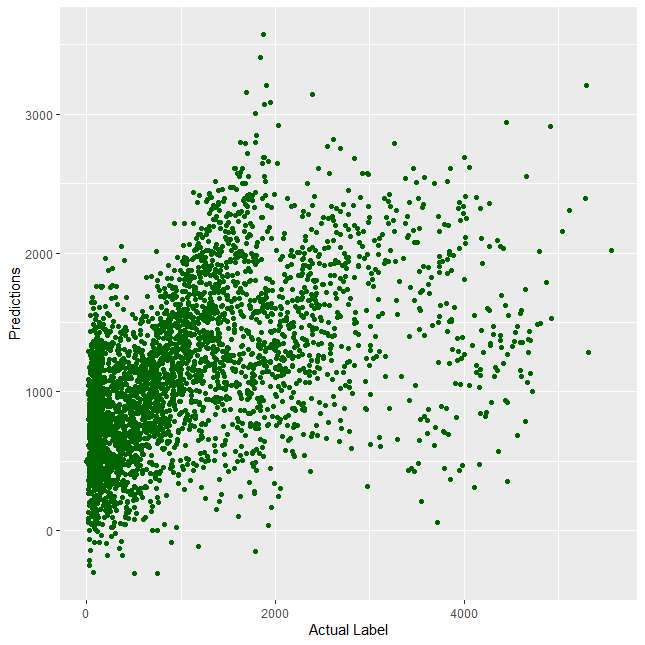
В h2o.glm alpha=1 представляет регрессию Лассо. Не похоже, чтобы наша модель так сильно улучшилась, и нам, вероятно, нужно еще немного поработать с функциями или попробовать другие аргументы с линейной регрессией (хотя маловероятно, что это сильно улучшит нашу модель).
В документации библиотеки вы найдете массу параметров для настройки этой обобщенной функции линейной модели. Важным выводом из этого первого процесса обучения является то, что реализация обучения h2o содержит множество настраиваемых параметров, которые мы можем экспериментировать и тестировать.
При оценке нашей модели мы провели только визуальное «тестирование», сопоставив наши прогнозы с реальной целью. Конечно, если мы хотим провести более научную оценку, у нас есть все известные метрики регрессии и классификации, доступные в структуре h2o!
Давайте посмотрим, что дальше.
Оценка наших моделей
Одна из замечательных вещей, которые мы можем сделать с h20, — это передать набор тестов непосредственно в нашу модель и использовать его для извлечения показателей проверки. Например, если мы хотим получить метрики из набора тестов, мы можем подключить их непосредственно к аргументу validation_frame в любой модели, обученной h2o:
london_bike_model <- h2o.glm(x = predictors,
y = response,
training_frame = training_data,
validation_frame = test_data)
Передача этого нового аргумента validation_frame даст нам возможность очень быстро извлекать метрики для обоих фреймов данных — например, давайте получим среднеквадратичную ошибку для нашей модели как для обучения, так и для теста (здесь это называется valid ):
h2o.rmse(london_bike_model, train=TRUE, valid=TRUE) train valid 936.5602 927.4826
Учитывая, что среднее значение нашей целевой переменной составляет 1143 велосипеда в час, наша модель работает не так хорошо. Мы также видим, что доказательств переобучения мало, поскольку обучающие и тестовые наборы кажутся похожими.
Как мы можем изменить метрику, с которой мы хотим получить добычу? Мы просто настраиваем функцию h2o! Например, если мы хотим посмотреть на r-квадрат, мы просто используем h2o.r2 :
h2o.r2(london_bike_model, train=TRUE, valid=TRUE) train valid 0.2606183 0.2456557
Супер просто! Положительным моментом является то, что вам не нужно беспокоиться обо всех деталях того, как реализовать эти показатели самостоятельно.
В этом примере я следую проблеме регрессии, но, конечно же, у вас также есть доступные модели классификации и метрики. Для просмотра всех метрик, доступных в h2o, перейдите по следующей ссылке.
Вполне ожидаемо, что наша линейная регрессия работает не так хорошо — мы не занимались разработкой каких-либо признаков и, вероятно, нарушаем слишком много допущений линейной регрессии. Но если мы сможем обучить простые линейные регрессии, мы, вероятно, сможем обучить и другие типы моделей в h2o, верно? Это верно ! Давайте посмотрим, что в следующем разделе.
Дополнительные примеры моделей
Как вы уже догадались, если мы изменим функцию h2o, связанную с тренировочным процессом, нам подойдут другие типы моделей. Давайте обучим случайный лес, вызвав h2o.randomForest:
london_bike_rf <- h2o.randomForest(x = predictors,
y = response,
ntrees = 25,
max_depth = 5,
training_frame = training_data,
validation_frame = test_data)
Я устанавливаю два гиперпараметра для своего случайного леса при вызове функции:
ntrees, задающий количество деревьев в лесу.maxdepth, который устанавливает максимальную глубину каждого дерева.
Если вам нужно, вы можете найти все настраиваемые параметры, вызвав help(h2o.randomForest) в консоли R.
Круто то, что теперь мы можем использовать то, что мы узнали о метриках модели, в этой новой модели, просто переключив модель, которую мы передаем в метрическую функцию — например, чтобы получить rmseэтой модели, мы переключаем первый аргумент на london_bike_rf:
h2o.rmse(london_bike_rf, train=TRUE, valid=TRUE) train valid 909.1772 900.5366
И чтобы получить r2 :
h2o.r2(london_bike_rf, train=TRUE, valid=TRUE) train valid 0.3032222 0.2888506
Обратите внимание, что наш код практически не изменился. Единственное, что было изменено, — это модель, которую мы передали в первый аргумент. Это делает эти метрические функции легко адаптируемыми к новым моделям, если они обучаются внутри структуры h2o.
Если вы перейдете по этой ссылке, вы найдете другие модели, которые вы можете тренировать с библиотекой. Из этого списка давайте подгоним нейронную сеть, используя h2o.deeplearning:
nn_model <- h2o.deeplearning(x = predictors,
y = response,
hidden = c(6,6,4,7),
epochs = 1000,
train_samples_per_iteration = -1,
reproducible = TRUE,
activation = "Rectifier",
seed = 23123,
training_frame = training_data,
validation_frame = test_data)
hidden — очень важный аргумент в функции h2o.deeplearning. Требуется вектор, который будет представлять количество скрытых слоев и нейронов, которые мы будем использовать в нашей нейронной сети. В нашем случае мы используем c(6,6,4,7), 4 скрытых слоя с 6, 6, 4 и 7 узлами в каждом.
Будет ли наша функция h2o.r2 точно так же работать с нейронными сетями? Давайте проверим:
h2o.r2(nn_model, train=TRUE, valid=TRUE)
train valid
0.3453560 0.3206021
Оно работает!
Итог: большинство функций, которые мы используем в структуре h2o, можно настроить для других моделей. Это очень хорошая функция, поскольку она позволяет легко переключаться между моделями с меньшим количеством кода, избегая чрезмерно сложной или подверженной ошибкам разработки.
Еще одна интересная особенность h2o заключается в том, что мы можем очень плавно настраивать гиперпараметры — давайте посмотрим, как это сделать.
Настройка гиперпараметров
Выполнение поиска по гиперпараметрам также очень просто в h2o — вам нужно только знать:
- Модель, в которой вы хотите выполнить поиск.
- Имя параметров, доступных для каждой модели.
- Значения, которые вы хотите проверить, для каких параметров.
Помните, что в случайном лесу, который мы обучили выше, мы установили ntrees и maxdepth вручную.
В примере с сеткой мы выполним поиск по обоим параметрам плюс min_rows. Мы можем сделать это с помощью функции h2o.grid:
# Grid Search
rf_params <- list(ntrees = c(2, 5, 10, 15),
max_depth = c(3, 5, 9),
min_rows = c(5, 10, 100))
# Train and validate a grid of randomForests
rf_grid <- h2o.grid("randomForest",
x = predictors,
y = response,
grid_id = "rf_grid",
training_frame = training_data,
validation_frame = test_data,
seed = 1,
hyper_params = rf_params)
Мы начинаем с объявления rf_params, которые содержат список значений, которые мы будем использовать в нашем поиске по сетке, а затем мы передаем эту сетку в аргумент hyper_params в h2o.grid. Что h2oбудет делать, так это обучать и оценивать каждую комбинацию доступных гиперпараметров.
Посмотреть результаты нашего поиска очень просто:
h2o.getGrid(grid_id = "rf_grid",
sort_by = "r2",
decreasing = TRUE)
Функция h2o.getGrid дает нам сводку лучших гиперпараметров в соответствии с определенной метрикой. В данном случае мы выбрали r2, но другие показатели, такие как RMSE или MSE, также работают. Давайте посмотрим на 5 лучших результатов нашего поиска по сетке:
Hyper-Parameter Search Summary: ordered by decreasing r2 max_depth min_rows ntrees model_ids r2 1 9.00000 5.00000 15.00000 rf_grid_model_30 0.33030 2 9.00000 5.00000 10.00000 rf_grid_model_21 0.32924 3 9.00000 5.00000 5.00000 rf_grid_model_12 0.32573 4 9.00000 10.00000 15.00000 rf_grid_model_33 0.32244 5 9.00000 10.00000 10.00000 rf_grid_model_24 0.31996
Нашей лучшей моделью была та, которая имела max_depth из 9, min_rows из 5 и 15 ntrees — эта модель достигла r2 0,3303.
Крутая часть? Вы можете расширить эту сетку до любого гиперпараметра, доступного в ?h2o.randomForest, или до любой модели, доступной в документации h2o, открывая бесконечное количество возможностей с одной и той же функцией.
Возможности AutoML
Если вам нужен быстрый и простой способ посмотреть, как различные модели работают с вашим набором данных, h2o также предлагает интересную процедуру automl:
aml <- h2o.automl(x = predictors,
y = response,
training_frame = training_data,
validation_frame = test_data,
max_models = 15,
seed = 1)
Аргумент max_models указывает максимальное количество моделей, которые нужно протестировать в конкретном ансамбле automl. Имейте в виду, что выполнение подпрограммы automl может занять некоторое время, в зависимости от ваших ресурсов.
Мы можем получить доступ к лучшим моделям нашей процедуры, проверив aml@leaderboard :
aml@leaderboard

Из приведенной выше таблицы видно, что модель Stacked Ensemble стала победителем (по крайней мере, с точки зрения rmse). Более подробную информацию о лучшей модели мы также можем получить по телефонам:
h2o.get_best_model(aml) Model Details: ============== H2ORegressionModel: stackedensemble Model ID: StackedEnsemble_AllModelsread.csvAutoMLread.csv20221027_95503 Number of Base Models: 15 Base Models (count by algorithm type): deeplearning drf gbm glm 4 2 8 1
Результат h2o.get_best_model(aml) возвращает дополнительную информацию о модели, получившей наилучший результат в нашей automlroutine. Из фрагмента выше мы знаем, что наш ансамбль объединяет результат:
- 4 модели глубокого обучения;
- 2 ранфовых леса;
- 8 моделей повышения градиента;
- 1 обобщенная линейная модель;
В зависимости от вашего варианта использования подпрограмма automl может быть быстрым и грязным способом понять, как ансамбли и отдельные модели ведут себя с вашими данными, давая вам подсказки о том, что делать дальше. Например, помощь в принятии решения о том, следует ли использовать более сложные модели или вам, вероятно, потребуется получить больше обучающих данных/функций.
Объяснимость
Наконец, давайте взглянем на некоторые из модулей объяснимости h2o. В этом примере мы будем использовать модель случайного леса, которую мы обучили выше:
london_bike_rf <- h2o.randomForest(x = predictors,
y = response,
ntrees = 25,
max_depth = 5,
training_frame = training_data,
validation_frame = test_data)
Как и в большинстве библиотек машинного обучения, мы можем получить график важности переменных непосредственно с помощью интерфейса h2o:
h2o.varimp_plot(london_bike_rf)

На графике важности мы видим, что влажность (hum) и температура (t1, t2) являются наиболее важными переменными для нашего обученного случайного леса. Вызов varimp_plot немедленно показывает график важности для конкретной модели, без необходимости настраивать что-либо еще.
Важность одной переменной — не единственные доступные модели объяснимости в h2o — мы также можем быстро проверить shapvalues:
h2o.shap_summary_plot(london_bike_rf, test_data)

Вуаля! Под shap_summary_plot мы понимаем направление связи между нашими функциями и целью. Например:
- более высокие температуры объясняют большее использование велосипеда.
- более низкая влажность также объясняет большее использование велосипеда.
В приведенном выше случае мы запросили общее объяснение shap для нашего test_data, но мы также можем проверить объяснимость отдельных строк, используя h2o — например, давайте посмотрим на 4-ю строку нашего тестового набора:

По сути, это был очень холодный январский день, и этот фактор, вероятно, повлиял на использование велосипедов в Лондоне, влияя на прогноз нашей модели — давайте передадим этот ряд толкователю:
h2o.shap_explain_row_plot(london_bike_rf, test_data, row_index = 4)

Интересный! Несколько функций снижают прогноз использования велосипедов. Например:
- Высокое значение влажности (93) отрицательно влияет на прогноз.
- Тот факт, что этот день был выходным, означает меньше поездок на работу и способствует нашему прогнозу.
Давайте посмотрим на лето, ряд дней недели:

В данном случае имеем обратное. Переменные температуры и влажности положительно влияют на высокую ценность использования велосипеда (прогноз ~ 2617).
Кроме того, анализируя строки, вы, вероятно, заметили, что час будет очень важной функцией — можете ли вы добавить эту функцию и обучить больше моделей в рамках h2o? Попробуйте сами и добавьте в свой репертуар немного практики h2o!
Спасибо, что нашли время, чтобы прочитать этот пост! Я надеюсь, что это руководство помогло вам начать работу с h2o и что теперь вы можете проверить, подходит ли эта библиотека для ваших конвейеров обработки данных. Хотя другие библиотеки, такие как caret, более известны, h2o не следует сбрасывать со счетов как претендента на выполнение задач машинного обучения. Основными преимуществами h2o являются:
- интересные
automlи объяснимые особенности. - возможность запускать
h2oзадач на удаленных серверах через локальную среду. - Широкий спектр различных моделей для использования и применения.
- Простые функции plug-and-play для поиска гиперпараметров или оценки модели.
Не стесняйтесь проверять другие руководства, которые я написал по библиотекам R, такие как caret, ggplot2 или dplyr.
Если вы хотите посетить мои курсы по R, присоединяйтесь сюда (Программирование на R для начинающих) или здесь (Учебный курс по науке о данных). Мои курсы R подходят для начинающих/разработчиков среднего уровня, и я буду рад видеть вас рядом!

Вот суть кода, использованного в этом посте:
Набор данных, используемый в этом посте, соответствует положениям и условиям лицензии открытого правительства, доступным по адресу https://www.kaggle.com/hmavrodiev/london-bike-sharing-dataset.