Актуальные обновления (SOTA) за 7–13 ноября 2022 г.

Прежде всего… зачем еще один информационный бюллетень о документах по машинному обучению?
Охватить все нюансы реализации модели в статье практически невозможно. Выпуск кода является ключом к воспроизведению работы или построению на ее основе. В то время как небольшой процент исследователей выпускает код на бумаге, другие могут выпускать код с задержкой, иногда начиная с пустого репозитория-заполнителя. Документы SOTA сообщаются здесь только в том случае, если репозиторий Github содержит официальный выпуск кода.
Этотеженедельный информационный бюллетень освещает работу исследователей, которые создали ультрасовременную работу, побив существующие рекорды по эталонным тестам. Они также
- написал свою статью
- выпустили свой код
- выпущенные модели в большинстве случаев
- выпущенные ноутбуки/приложения в нескольких случаях
Стоит отметить, что значительная часть лицензий на выпуск кода допускает коммерческое использование. Единственная просьба этих исследователей в ответ от публики - это атрибуция. Также стоит отметить, что многие из этих исследователей SOTA практически не представлены в Интернете.
Новые рекорды были установлены по следующим задачам
- Создание изображения
- Оценка качества видео
- Подсказка видео
- Сегментация экземпляров
Этот еженедельник представляет собой сводку ежедневных сообщений в Твиттере, отслеживающих исследователей SOTA. Ежедневные обновления SOTA также публикуются на @[email protected] — альтернативе твиттера от сообщества ИИ и для него
На сегодняшний день 27,5%(90 902) от общего числа опубликованных статей (331 016) имеют код, выпущенный вместе с статьями (источник).
Сведения о SOTA ниже представляют собой снимки моделей SOTA на момент публикации этого информационного бюллетеня. Сведения о SOTA в ссылке, приведенной под снимками, скорее всего, будут отличаться от снимка с течением времени по мере появления новых моделей SOTA.
№1 в области создания изображений для FFHQ 256 x 256

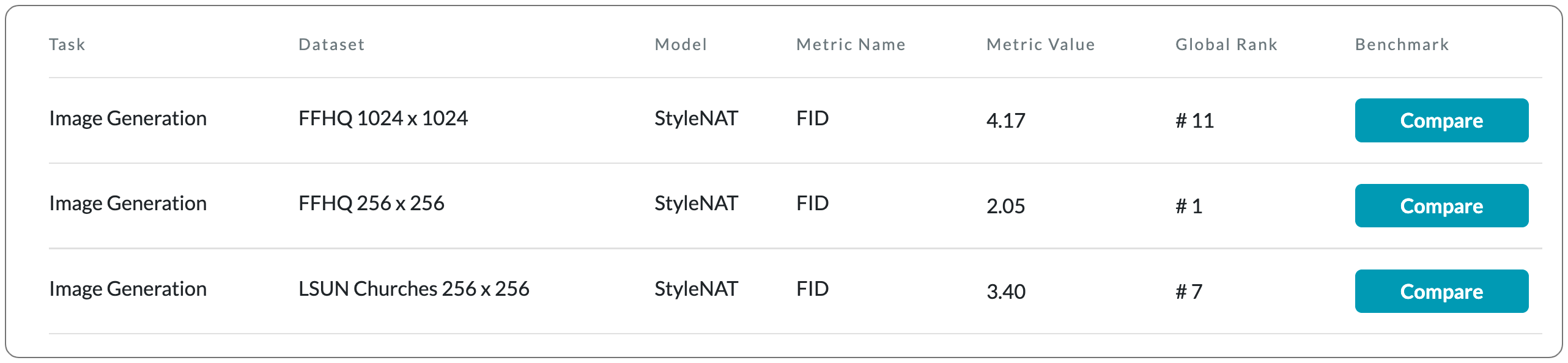

Название модели: StyleNAT
Примечания. В этом документе представлена новая платформа на основе преобразователя, получившая название StyleNAT, предназначенная для создания высококачественных изображений с превосходной эффективностью и гибкостью. Эта модель имеет структуру, которая разделяет головы внимания для захвата локальной и глобальной информации, что достигается за счет использования соседского внимания (NA). С разными головами, способными обращать внимание на разные рецептивные поля, модель способна лучше комбинировать эту информацию и очень гибко адаптироваться к имеющимся данным.
Демонстрационная страница: пока нет
Лицензия: на сегодняшний день нет
№1 в оценке качества видео по 3 наборам данных
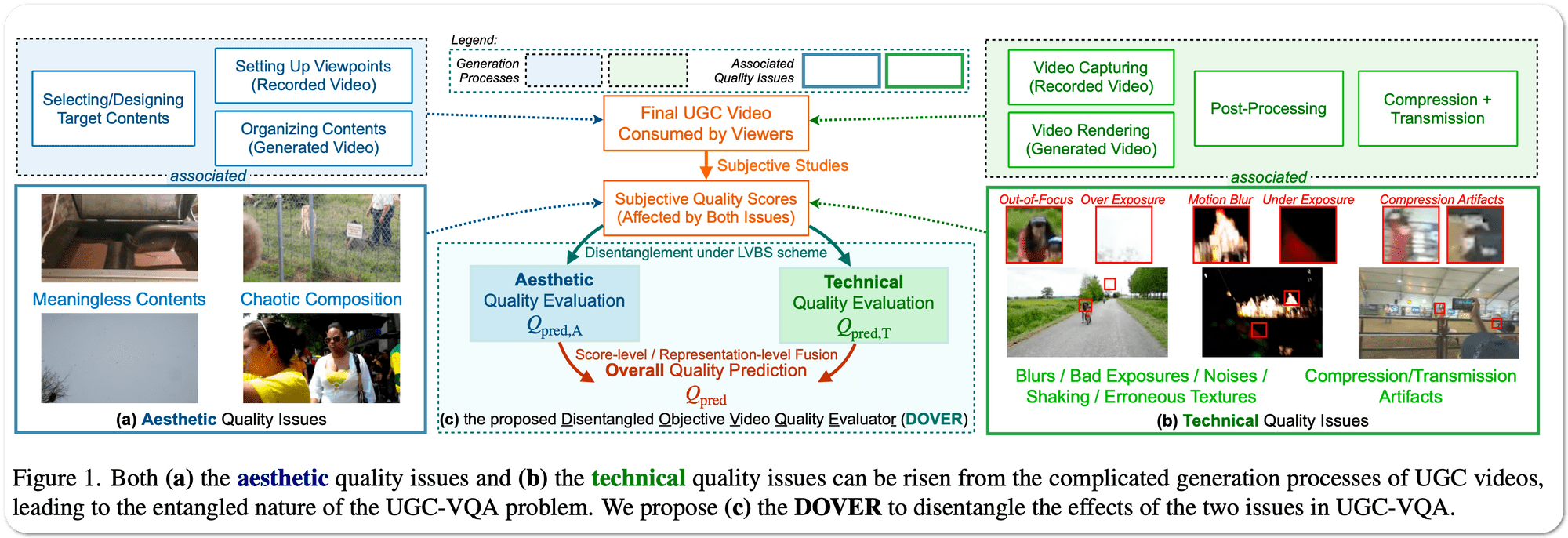


Название модели: ДУВЕР
Примечания. Видео с пользовательским контентом (UGC) доминировали в Интернете в последние годы. Хотя многие методы пытаются объективно оценить качество этих видео UGC, механизмы человеческого восприятия качества в проблеме UGC-VQA еще предстоит изучить. Чтобы лучше объяснить механизмы восприятия качества и изучить более надежные представления, в этой статье делается попытка разделить влияние эстетических проблем качества и технических проблем качества, возникающих из-за сложных процессов генерации видео в проблеме UGC-VQA. Чтобы преодолеть отсутствие соответствующего надзора во время распутывания, в документе предлагается схема предвзятого надзора с ограниченным представлением (LVBS), в которой два отдельных оценщика обучаются с помощью декомпозированных представлений, специально разработанных для каждой проблемы.
Демонстрационная страница: добавлен блокнот для тестирования модели. Качество пользовательских видео можно загружать и оценивать с помощью блокнота. Пример теста ниже

Лицензия: лицензия MIT
№1 в прогнозировании видео на Kinetics-600, 12 кадров, набор данных 64 x 64

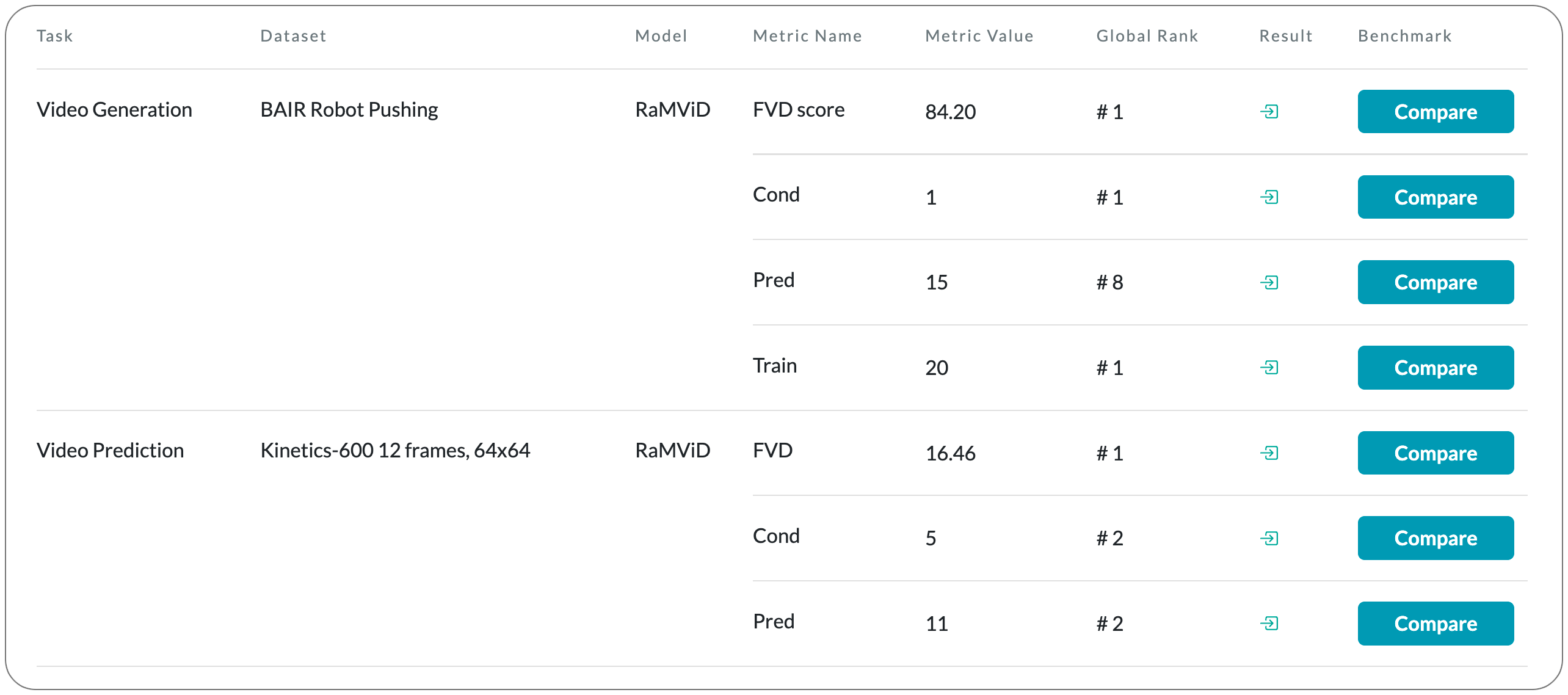

Название модели: RaMViD
Примечания. Прогнозирование и предвосхищение будущих результатов или обоснование отсутствующей информации в последовательности являются критически важными навыками, позволяющими агентам принимать разумные решения. Это требует сильных, согласованных во времени генеративных способностей. Диффузионные модели показали замечательные успехи в нескольких генеративных задачах, но не были широко исследованы в области видео. В этой статье представлена диффузия видео со случайной маской (RaMViD), которая расширяет модели диффузии изображений до видео с использованием 3D-сверток и представляет новую технику кондиционирования во время обучения. Изменяя обусловленную маску, модель может выполнять предсказание видео, заполнение и повышающую дискретизацию. С помощью простой схемы кондиционирования они могут использовать ту же архитектуру, что и для безусловного обучения, что позволяет им одновременно обучать модель условным и безусловным образом.
Демонстрационная страница: пока нет. Несколько примеров на странице блога статьи
Лицензия: лицензия MIT
№1 в сегментации экземпляров в наборе данных COCO



Название модели: DiNAT-L
Примечания. Прошлые попытки унифицировать сегментацию изображений в последние десятилетия включают анализ сцен, паноптическую сегментацию и, совсем недавно, новые паноптические архитектуры. Однако такие паноптические архитектуры на самом деле не унифицируют сегментацию изображений, поскольку для достижения наилучшей производительности их необходимо индивидуально обучать семантической, экземплярной или паноптической сегментации. В идеале действительно универсальная структура должна быть обучена только один раз и хорошо работать во всех трех задачах сегментации изображений. В этой статье предлагается OneFormer, универсальная структура сегментации изображений, которая объединяет сегментацию с многозадачной однократной схемой обучения. Во-первых, стратегия совместного обучения, обусловленная задачами, позволяет проводить обучение основным истинам каждой области (семантической, экземплярной и паноптической сегментации) в рамках единого многозадачного учебного процесса. Во-вторых, токен задачи используется для приведения модели в соответствие с текущей задачей, что делает модель динамичной для поддержки многозадачного обучения и логического вывода. В-третьих, контрастная потеря текста запроса используется во время обучения, чтобы установить лучшие межзадачные и межклассовые различия.
Демонстрационная страница: Ссылка на блокнот Colab
Лицензия: лицензия MIT