Вариант использования качества данных с расширенным EDA
Визуализация является краеугольным камнем EDA. Когда мы сталкиваемся с новым неизвестным набором данных, визуальный осмотр позволяет нам получить представление об имеющейся информации, нарисовать некоторые закономерности в отношении данных и диагностировать несколько проблем, которые нам, возможно, придется решить. В этом отношении Pandas Profiling был незаменимым швейцарским ножом в поясе инструментов каждого специалиста по данным. В своих прошлых статьях я упоминал, как профилирование pandas может быть полезным при выполнении EDA временных рядов, но что, если бы мы могли сравнить два набора данных?
Сколько из нас начали разработку проекта по науке о данных и изо всех сил пытаются понять, сколько мы получаем от наших преобразований данных и разработки?
И это именно то, что я расскажу в сегодняшней статье — как использовать самую известную строку кода EDA для ускорения процесса развития науки о данных и улучшения качества данных. Я покажу вам, как использовать функцию сравнительного отчета Pandas-Profiling, чтобы ускорить процесс EDA и проиллюстрировать его потенциал в более быстром и разумном преобразовании наших данных.
Набор данных, используемый в этой статье, можно найти в Kaggle, наборе данных HCC Мириам Сантос (лицензия: CC0: Public Domain). Для этого конкретного варианта использования я искусственно ввел некоторые дополнительные проблемы с качеством данных, чтобы показать вам, как визуализация может помочь нам обнаружить их и направить нас к их эффективному устранению. Весь код и примеры доступны на GitHub, и, если вам нужно немного освежиться, не забудьте проверить этот блог, чтобы стряхнуть пыль со своих навыков профилирования панд. Итак, приступим к нашему варианту использования!
Pandas Profiling: EDA у вас под рукой
Мы начнем с профилирования набора данных HCC и изучения проблем качества данных, предложенных в отчете:
pip install pandas-profiling==3.5.0
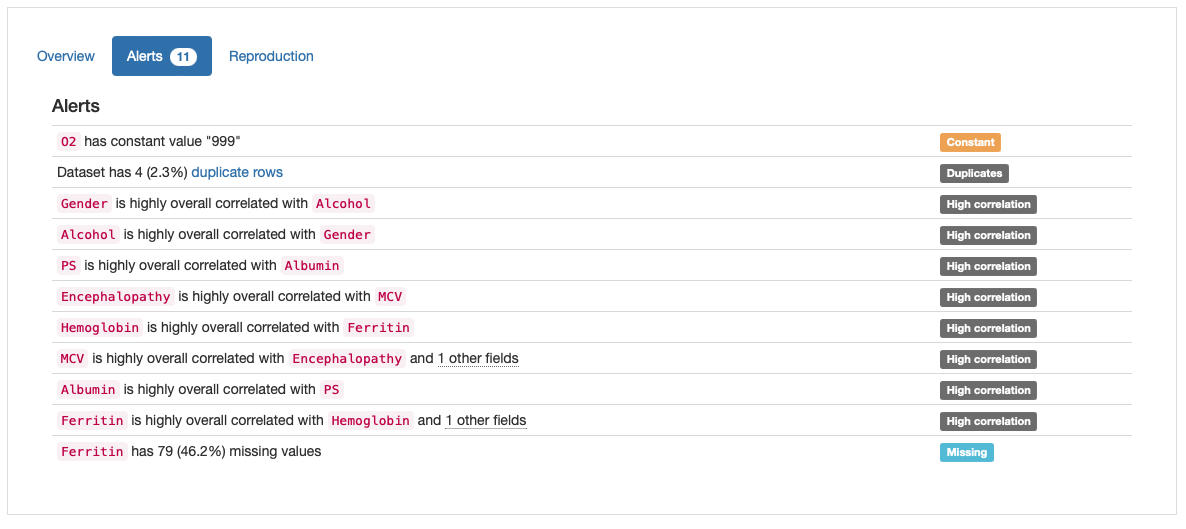
Согласно обзору «Предупреждения», существует четыре основных типа потенциальных проблем, которые необходимо решить:
- Дубликаты: 4 повторяющиеся строки в данных;
- Константа: постоянное значение «999» в «O2»;
- Высокая корреляция: несколько функций отмечены как сильно коррелированные;
- Отсутствует: Отсутствующие значения в «Ферритине».
Обоснованность каждой потенциальной проблемы (а также необходимость поиска стратегии ее устранения) зависит от конкретного варианта использования и знаний предметной области. В нашем случае, за исключением предупреждений о «высокой корреляции», которые потребуют дальнейшего изучения, оставшиеся предупреждения, по-видимому, отражают реальные проблемы с качеством данных и могут быть решены с помощью нескольких практических решений:
Удаление повторяющихся строк. В зависимости от характера домена могут быть записи с одинаковыми значениями, но это не является ошибкой. Однако, учитывая, что некоторые признаки в этом наборе данных весьма специфичны и относятся к индивидуальным биологическим измерениям (например, «гемоглобин», «MCV», «альбумин»), маловероятно, что несколько пациентов сообщают одинаковые точные значения для всех признаков. . Начнем с удаления этих дубликатов из данных:
Удаление ненужных функций. Постоянные значения в O2 также отражают истинное несоответствие данных и, похоже, не содержат ценной информации для разработки модели. В реальных сценариях использования было бы хорошим стандартом выполнить итерацию с доменом или бизнес-экспертами, но для целей этого примера использования мы продолжим и исключим их из анализа:
Вменение отсутствующих данных: набор данных HCC также кажется чрезвычайно чувствительным к отсутствующим данным. Простой способ решить эту проблему (избегая удаления неполных записей или целых объектов) — прибегнуть к вменению данных. Мы будем использовать среднее вменение для заполнения отсутствующих наблюдений, так как это наиболее распространенный и простой из методов статистического вменения и часто служит базовым методом:
Прямое сравнение: более быстрые и рациональные итерации ваших данных
Теперь самое интересное! После реализации первой партии преобразований в нашем наборе данных мы готовы оценить их влияние на общее качество наших данных. Вот где пригодится функциональность отчета сравнения с профилированием pandas. В приведенном ниже коде показано, как начать работу:
Вот как оба отчета показаны в сравнении:

Что мы можем сразу понять из нашего обзора набора данных? Преобразованный набор данных содержит на один категориальный признак меньше («O2» был удален), 165 наблюдений (по сравнению с исходными 171, содержащими дубликаты) и без пропущенных значений (в отличие от 79 отсутствующих наблюдений в исходном наборе данных).
Но как эти преобразования повлияли на качество наших данных? И насколько хороши были эти решения?
Давайте углубимся в это. Что касается повторяющихся записей, то особого влияния на распределение переменных и шаблоны наборов данных после удаления не произошло. Вменение пропущенных значений, которое было выполнено, — это отдельная история.
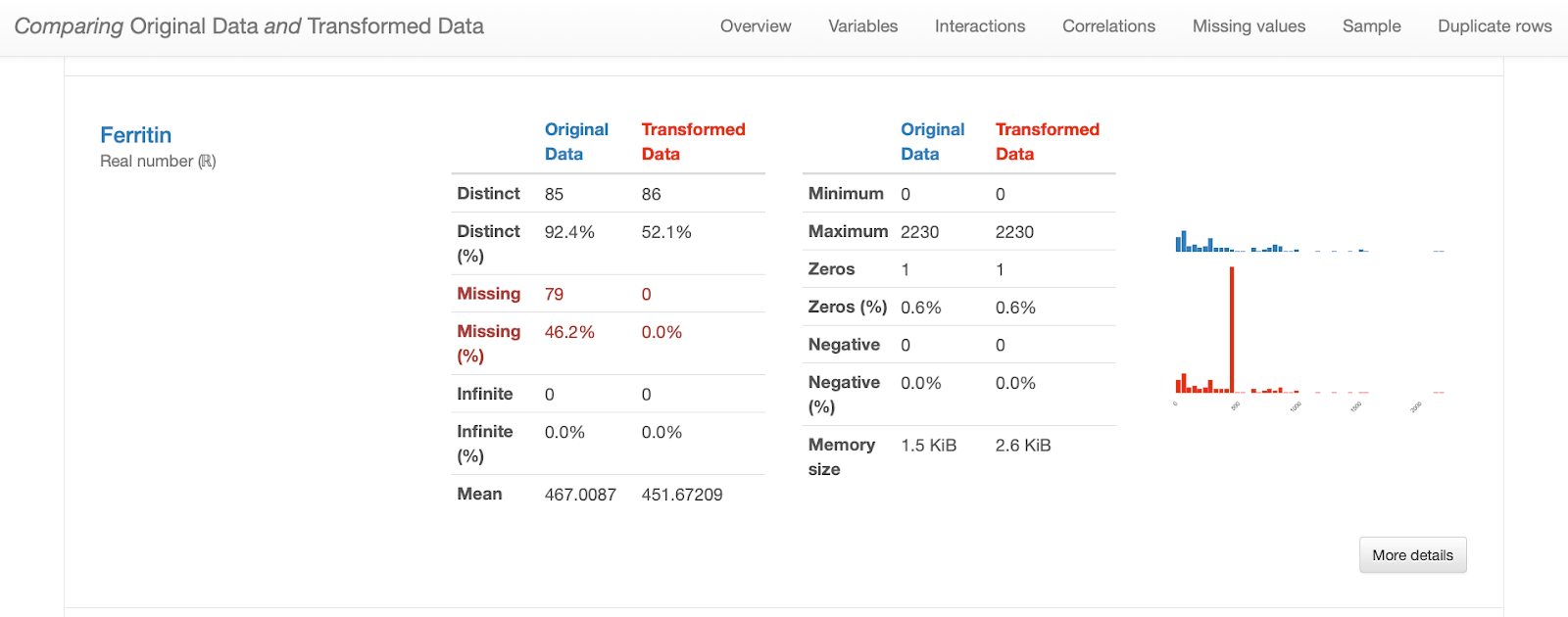
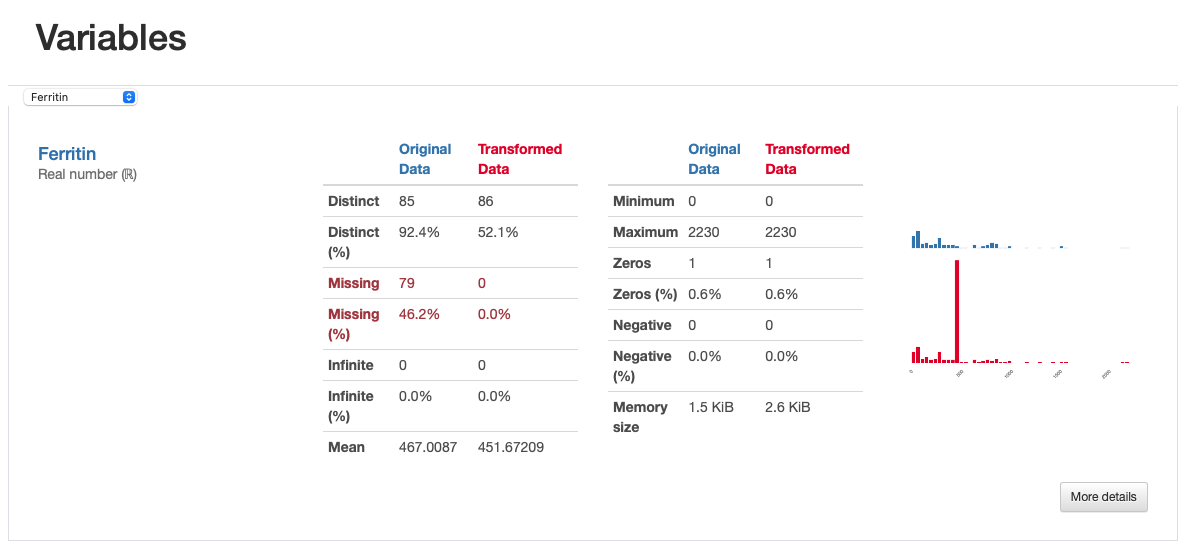
Как и ожидалось, после выполнения импутации данных отсутствуют пропущенные наблюдения. Обратите внимание, как подсчет недействительности и матрица показывают различия между обеими версиями данных: в преобразованных данных «ферритин» теперь имеет 165 полных значений, а в матрице недействительности нет пробелов.

Однако из сравнительного отчета мы можем сделать еще кое-что. Если бы мы изучили гистограмму «Ферритин», мы бы увидели, как вменение значений со средним значением исказило исходное распределение данных, что нежелательно.
Это также наблюдается посредством визуализации взаимодействий и корреляций, где возникают нелепые паттерны взаимодействия и более высокие значения корреляции в отношениях между «ферритином» и остальными характеристиками.
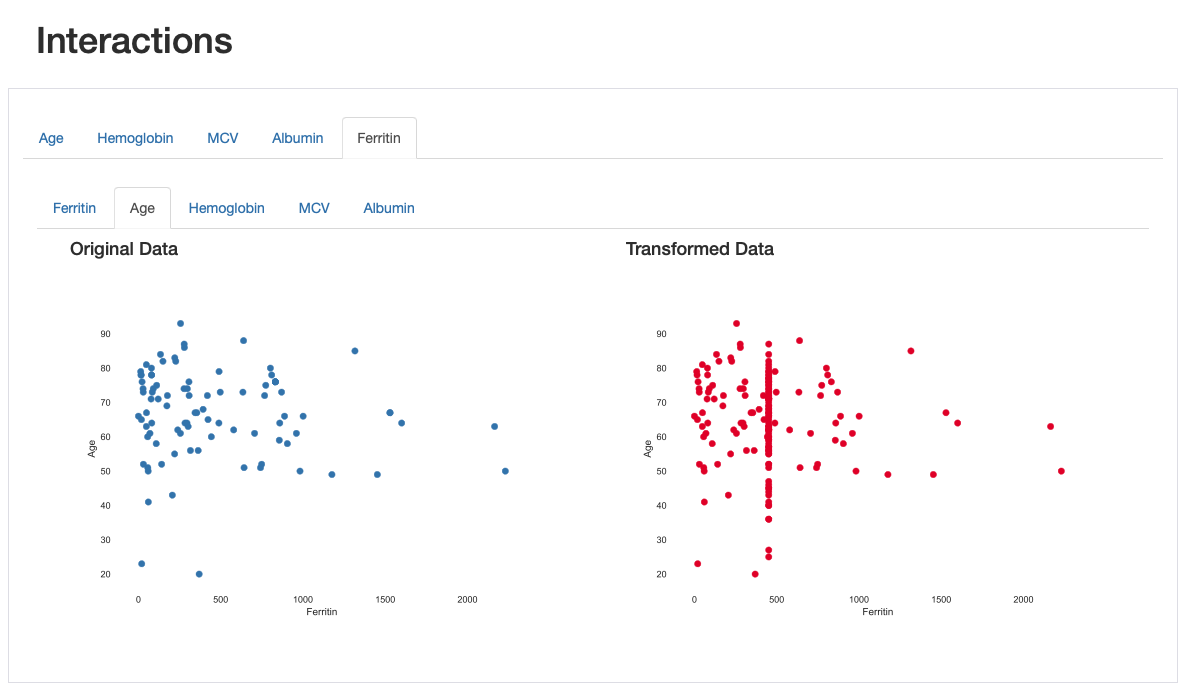
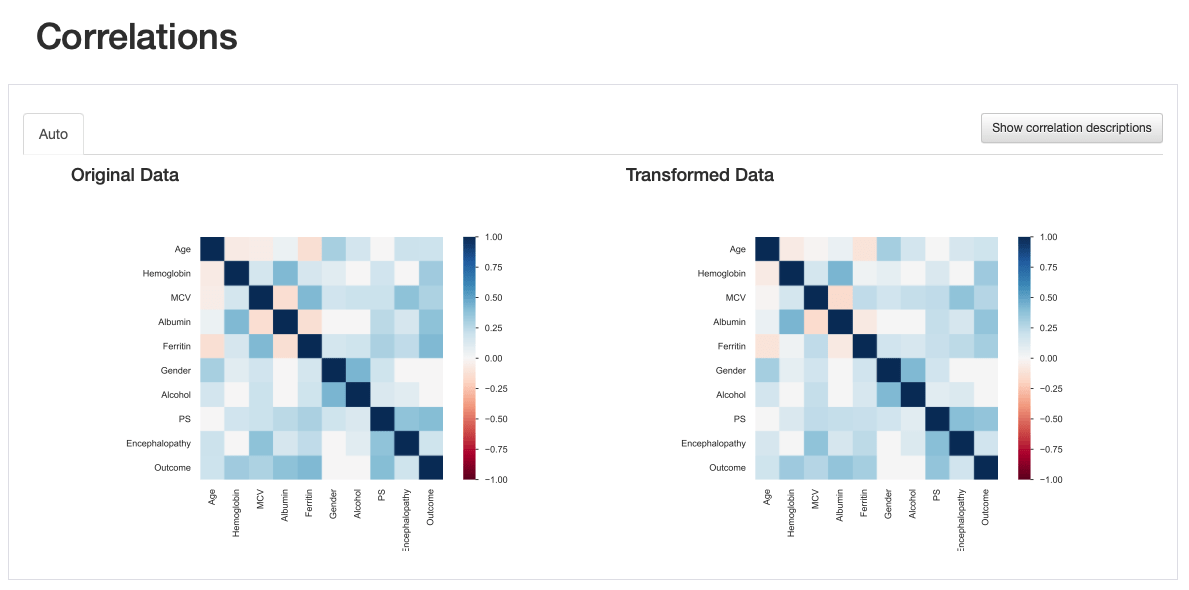
Это показывает, что сравнительный отчет не только полезен для выделения различий, появившихся после преобразования данных, но и предоставляет несколько визуальных подсказок, которые ведут нас к важной информации об этих преобразованиях: в этом случае следует рассмотреть более специализированную стратегию импутации данных. .
Последние мысли
В этом небольшом примере использования мы рассмотрели полезность сравнения двух наборов данных в одном и том же отчете о профилировании, чтобы выделить преобразования данных, выполненные во время EDA, и оценить их влияние на качество данных.
Тем не менее, применение этой функциональности безгранично, поскольку необходимость (повторного) повторения оценки характеристик и визуального контроля жизненно важна для решений, ориентированных на данные. От сравнения наборов обучения, проверки и тестирования, распределений или контроля качества данных до более сложных вариантов использования, таких как процесс синтетического создания данных. ».
Фабиана Клементе, CDO в YData
Ускорение работы ИИ с улучшенными данными.