Сыграйте лучшую роль человека в жизненном цикле машинного обучения

Об авторе: Цзянчун (LinkedIn, GitHub) в настоящее время работает старшим специалистом по данным в ViSenze, стартапе в области искусственного интеллекта, базирующемся в Сингапуре. До прихода в ViSenze она работала специалистом по данным в лаборатории AXA Data Innovation Lab.

В марте у меня появилась возможность выступить с докладом о реальной практике машинного обучения для AISG. Это краткий пост для разговора.
Выбранная мною тема, как сказано в заголовке, в основном о том, как Человек участвует в жизненном цикле машинного обучения. Он во многом вдохновлен книгой с точно таким же названием Human-in-the-Loop Machine Learning, написанной Робертом (Манро) Монархом.
Мне повезло, что я могу закончить предварительную версию еще до того, как она будет официально опубликована (ориентировочно в мае 2021 года). Это определенно одна из самых проницательных книг по машинному обучению, которые я читал за последнее время. Я настоятельно рекомендую его всем, кто интересуется реальной практикой машинного обучения.
Кто такие люди в петле
На практике успешная проектная группа по машинному обучению требует разнообразного сочетания людей и навыков. Специалисты по обработке данных — лишь малая часть этого. В идеале должно быть не менее пяти разных ролей.

Менеджеры по продуктам общаются с клиентами, собирают требования и преобразуют полезную информацию в документы с требованиями к продукту (PRD). PRD — это отправная точка любого проекта машинного обучения.
Аналитики данных извлекают ценную информацию из данных, чтобы помочь команде принимать более обоснованные решения. Например, анализ конкурентов и исследование рынка дают команде четкие ориентиры и основные направления деятельности.
Эксперты в предметной области внедряют профессиональные знания в продукты машинного обучения, преобразуя неструктурированные, неявные знания предметной области в структурированные, явные материалы (таксономии, рекомендации по аннотациям и т. д.) для разработки продуктов машинного обучения.
Исследователи данных отвечают за сквозную разработку моделей, включая подготовку данных, обучение моделей, развертывание, мониторинг моделей и т. д.
И последнее, но не менее важное: учитывая, что алгоритмы глубокого обучения нуждаются в данных, поставщики (аутсорсинговые работники) предоставляют крупномасштабные услуги аннотирования для создания обучающих данных.
Постановка задачи машинного обучения
Прежде чем погрузиться в разработку решения ML, стоит потратить время на то, чтобы тщательно сформулировать проблему машинного обучения таким образом, чтобы ее можно было решить с помощью методов ML.
Я настоятельно рекомендую этот курс, созданный Google: Введение в формулирование задач машинного обучения. Он содержит исчерпывающие инструкции по постановке задач ML, в том числе: (цитата из целей курса)
- Определить распространенные термины ML
- Опишите примеры продуктов, которые используют ML, и общие методы решения проблем ML, используемые в каждом из них.
- Определите, нужно ли решать проблему с ML
- Сравните и сопоставьте ML с другими методами программирования
- Применяйте проверку гипотез и научный метод к задачам машинного обучения
- Поговорите о методах решения проблем ML
Важные решения перед разработкой
После правильной постановки задачи машинного обучения остается принять несколько важных решений, прежде чем переходить к этапу разработки. Мы используем идентификацию породы собак в качестве примера, чтобы продемонстрировать процесс принятия решений.
Каков охват?
Почти все модели машинного обучения строятся в условиях закрытого мира. С точки зрения модели ее «область охвата» определяет ее «мир» или ее ожидаемые возможности. Определение надлежащей области — это наиболее важное решение, которое влияет на последующий выбор стратегий сбора данных, сложности модели, методологий оценки и т. д. Это также влияет на понимание и ожидания заинтересованных сторон. Все заинтересованные стороны должны участвовать в обсуждении и представлять различные точки зрения.

Возможные вопросы, на которые можно ответить в ходе обсуждения:
- Каков целевой вариант использования? Идентификация породы собак.
- Сколько всего пород собак? 120.
- Какие бывают породы собак? Список из 120 пород собак.
- Мультикласс или мультилейбл? Мультикласс, одна собака может принадлежать только к одной породе.
- Какие ожидаемые типы изображений? Фотографии. (другими возможными типами изображений могут быть наброски, рисунки, отрисовки и т. д. Разные типы изображений обычно подразумевают разные уровни сложности. Справочник)
- Включено ли обнаружение? Нет. Модель не сможет правильно обрабатывать изображения с несколькими породами собак.
- Каковы ожидаемые успешные сценарии? Если на входном изображении есть только одна единственная порода собак (не имеет значения, если их несколько), модель должна быть в состоянии распознать породу собаки с высокой точностью.
- Какие могут быть возможные сценарии сбоя? Учитывая отсутствие ограничивающей рамки объекта, если на входном изображении несколько пород собак, модель может работать плохо. Понимание ограничений модели так же важно, как и понимание ее возможностей. Специалисты по данным будут более способны отлаживать проблемы с производительностью, если они заранее продумали все возможности. Менеджеры по продукту, безусловно, выиграют, поскольку им всегда нужно давать обоснованные объяснения клиентам, когда что-то идет не так. Кроме того, указание на неудачные сценарии может вдохновить команду на новые идеи. В этом примере команда может подумать о включении в план решения по обнаружению собак, если они хотят обрабатывать изображения с несколькими породами собак.
Как выглядит ввод?
Фотографии одной собаки или нескольких собак одной породы.

Как выглядит вывод?
Слева: если нет обнаружения. Правильно: если обнаружение включено. Одним из возможных расширений является вывод уровня достоверности модели или требование, чтобы показатель прогнозирования представлял уровень достоверности.

Как оценить производительность?
- Как создать репрезентативный оценочный набор? Например, оценочный набор должен содержать как минимум 10 изображений каждой породы собак, охватывать как внутреннюю, так и внешнюю среду, а также широкий диапазон приемлемых условий освещения и т. д.
- Все типы ошибок одинаково серьезны? Например, прогнозирование маламута как сибирского хаски так же плохо, как прогнозирование маламута как Шетландская овчарка? Более серьезные проблемы должны быть приоритетными.

- Какие показатели использовать и какова цель? Для этого примера мы требуем, чтобы оценка F1 для каждой породы собак была не менее 0,8, а взвешенная (в соответствии с важностью) общая оценка F1 составляла не менее 0,85.
Дизайн и уточнение аннотаций
Аннотация помещает «Человека» в машинное обучение «Человек в цикле». Создание наборов данных с точными и репрезентативными метками для машинного обучения часто является самым недооцененным компонентом приложения машинного обучения.
Если вы только участвовали в проектах по машинному обучению в школе, вы можете даже не знать, как работает аннотация данных. Обычно наборы данных, даже разбивки (обучение/проверка/тестирование), готовятся с самого начала, особенно если вы используете открытые наборы данных, такие как ImageNet.
К счастью, есть исследовательские работы, подробно описывающие процесс аннотирования данных. Возьмем в качестве примера бумагу ImageNet:
Чтобы собрать высокоточный набор данных, мы полагаемся на людей для проверки каждого изображения-кандидата, собранного на предыдущем шаге для данного синсета. Это достигается с помощью службы Amazon Mechanical Turk (AMT), онлайн-платформы, на которой можно размещать задачи для выполнения пользователями и получения оплаты.
ImageNet: крупномасштабная иерархическая база данных изображений
Подобно проекту ImageNet, многие академические проекты выбрали краудсорсинговых работников в качестве рабочей силы для аннотаций, главным образом потому, что использование краудсорсинговых работников позволяет гибко масштабировать вверх и вниз. Хотя краудсорсинговые работники являются самой обсуждаемой рабочей силой, они на самом деле являются наименее используемой рабочей силой в отраслях.
В то время как академические исследовательские проекты в основном сосредоточены на быстрых экспериментах для различных вариантов использования, компании, занимающиеся искусственным интеллектом, стремятся к «постоянному повышению точности для одного варианта использования» (цитата из книги). С их точки зрения, более эффективно нанимать специальных аннотаторов для последовательного создания высококачественных аннотаций данных.
В большинстве компаний крупные и устойчивые проекты машинного обучения редко полагаются на краудсорсинговых работников.
Более того, аннотирование реальных данных никогда не бывает одноразовым. Он образует небольшую петлю внутри себя.

На практике компании, занимающиеся ИИ, в основном полагаются на три типа специалистов по аннотациям.
Собственные доменные эксперты
Эксперты в предметной области - это профессионалы с желаемыми знаниями в конкретных областях. Здравоохранительные ИИ-компании могут нанимать людей с медицинским образованием в качестве штатных экспертов. Модные ИИ-компании могут искать модельеров, а компании, специализирующиеся на мебели, могут нанимать дизайнеров мебели.
Эксперты предметной области представляют производительность на уровне человека любой предметно-ориентированной задачи, для выполнения которой мы хотим разработать модели машинного обучения. Производительность на уровне человека часто также рассматривается как производительность модели машинного обучения с верхней границей. Помимо установления стандартов правильной маркировки данных, их вклад в аннотирование данных включает, помимо прочего:
- Определите значение каждой метки.
- Уточните границы между разными метками.
- Рекомендации по дизайну аннотаций для непрофессиональных аннотаторов.
- Получите отзывы от непрофессионалов-аннотаторов и уточните стандарты аннотаций.
Члены команды проекта
Независимо от того, какое сочетание рабочей силы вы используете, я рекомендую проводить сеансы аннотирования среди максимально возможного разнообразия внутренних сотрудников.
Как и в приведенном выше совете, мы всегда рекомендуем проводить небольшие сеансы внутреннего аннотирования перед крупномасштабным внешним аннотированием. Помимо экспертов в предметной области, во внутренних сеансах аннотирования всегда участвуют специалисты по данным (иногда аналитики данных или даже менеджеры по продуктам). На самом деле, мы предпочитаем относиться к этому как к строгому требованию, а не как к рекомендуемой практике, потому что преимущества очевидны.
- Чтобы эффективно обучать и диагностировать модели машинного обучения, специалистам по данным необходимо вооружиться необходимыми знаниями для выполнения целевых задач.
- Испытывая начальные задачи по аннотированию в небольшом масштабе, специалисты по данным значительно помогают устранять неполадки и предоставляют ценную обратную связь с точки зрения аннотаторов-непрофессионалов.
В идеале большинство проблем должно быть обнаружено и решено после нескольких раундов внутренней аннотации. Сторонние поставщики могут рассчитывать на высококачественные инструкции по аннотации в то время, когда они начинают работать над задачами аннотации.
Сторонние поставщики
Сторонние поставщики являются основной рабочей силой для аннотирования крупномасштабных данных. На этапе крупномасштабного внешнего аннотирования предполагается, что инструкции по аннотированию четко определены, а задачи аннотирования максимально упрощены. Поэтому разумно полагать, что вендоры способны создавать качественные аннотации, хотя и не обладают исчерпывающими знаниями о задачах, просто потому, что это не требуется.
Однако качество аннотаций поставщиков по-прежнему считается ниже, чем у внутренних аннотаторов-непрофессионалов, главным образом потому, что они обычно должны аннотировать большой объем данных в условиях жестких временных ограничений. Качество может быть еще хуже, если нет должного контроля качества. (Они могут просто аннотировать случайным образом.) На практике внутренние аннотации часто используются для контроля качества.
Скрытые факты об аннотации
Факт 1. Надлежащие рекомендации по написанию аннотаций требуют больших усилий
Особенно, когда задача специфична для предметной области.
Неудивительно, что иногда мы можем выполнять определенные задачи, но не можем объяснить их логику. Точно так же эксперты в предметной области часто пытаются преобразовать термины, зависящие от предметной области, в понятные для неспециалистов языки. Представьте, как вы могли бы создать инструкции по различению сиба и акиты.
Ниже приведен пример страницы нашего руководства по аннотации по распознаванию пола. Даже описать разницу между женскими и мужскими товарами не так просто, как может показаться.

Факт 2. Коммуникация может стать узким местом
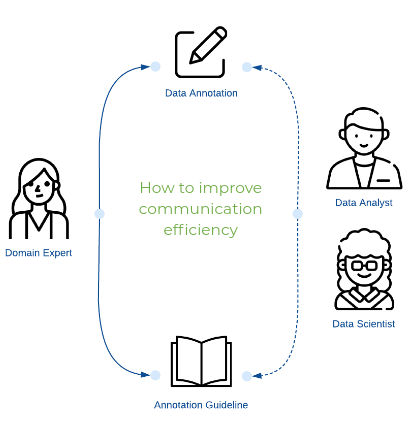
Внутренний сеанс аннотирования требует обратной связи между экспертами предметной области и внутренними аннотаторами. Без тщательно разработанных протоколов коммуникация вскоре станет узким местом, особенно когда эксперты в предметной области отвечают за несколько проектов параллельно.
Ниже приведен пример, показывающий, как внутренний аннотатор указывает на запутанную часть руководства, а также комментарии эксперта в предметной области.

Данные — новая нефть?
В каждой отрасли, которую я видел, современная модель, которая выигрывала в долгосрочной перспективе, была победителем благодаря лучшим обучающим данным, а не благодаря новым алгоритмам. Вот почему наличие более качественных данных часто называют «рвом данных»: данные — это барьер, который не позволяет вашим конкурентам достичь того же уровня точности.
Простой ответ - да.
Это может разочаровать многих людей, которые хотят продолжить карьеру в области машинного обучения, поскольку специалисты по данным на самом деле проводят большую часть своего времени, просматривая данные, обнаруживая и устраняя проблемы с данными. Я считаю, что именно по этой причине нас называют учеными данных, а не инженерами-программистами, инженерами-алгоритмистами или учеными-исследователями и т. д. Если вы не любите работать с данными, быть специалистом по данным — это не ваш выбор.
Кроме того, мы не должны принимать это как должное. Специалисты по данным не смогут сосредоточиться на данных без огромных усилий самоотверженных первопроходцев и участников. Нам не нужно изобретать велосипед, потому что мы можем легко начать работу с scikit-learn, PyTorch, TensorFlow, Keras и т. д. Нам очень помогают предварительно обученные модели, выпущенные академическими исследовательскими группами и крупными компаниями, поэтому даже отдельные люди могут создавать мощные Современные модели ML. Также стало удобнее получать доступ к современным результатам исследований благодаря arXiv, GitHub и т. д.

Хотя решение проблем с данными может показаться не таким уж захватывающим, на практике это, как правило, в наибольшей степени способствует повышению производительности. В реальных случаях простое улучшение охвата данных и качества аннотаций может повысить производительность модели более чем на 10%, в то время как настройка гиперпараметров не поможет, если только вы не переключитесь на более крупную модель или не используете больший размер входных данных. Конечно, мы предполагаем, что вы понимаете общеизвестные рекомендации, такие как перенос обучения и снижение скорости обучения, и уже применили их к обучению моделей.
Другим исключением может быть то, что вы достаточно опытны и вам повезло обнаружить «золотую» настройку гиперпараметра, при условии, что вы полностью понимаете особенности стоящей перед вами задачи, поэтому у вас есть четкое представление о том, какие параметры нужно настроить. Но в целом шанс редкий. Вместо этого я продолжаю видеть, как люди настраивают гиперпараметры, не зная логики.
Возможно, вы не увидите много исследовательских работ, в которых говорится об устранении проблем с данными или улучшении качества данных, поскольку исследовательские проекты обычно не имеют возможности изменить данные, если они хотят объективно сравнивать друг с другом. На практике нам разрешено свободно изменять данные, если это улучшает производительность модели. Кроме того, некоторые методы слишком просты, поэтому нет необходимости писать исследовательскую работу. Но это не значит, что они неэффективны.
Мусор на входе, мусор на выходе (GIGO)
Высококачественные входы отвечают за высококачественные результаты. Обучающие данные являются окончательным учебным материалом для любой модели, обученной с помощью обучения с учителем. Нет причин отрицать важность данных.
Разработка функций против «инженерии» данных
Как уже упоминалось в предыдущей сессии, специалисты по данным по-прежнему тратят большую часть своего времени на подготовку данных, независимо от того, работают ли они с традиционными алгоритмами машинного обучения или глубокого обучения.
Традиционное машинное обучение: проектирование функций
До моей нынешней работы я работал специалистом по данным в крупной страховой компании. В то время я работал со структурированными данными и создавал традиционные модели машинного обучения для прогнозирования поведения пользователей, включая прогнозирование покупок клиентов, прогнозирование оттока, обнаружение ошибок и т. д.
Поскольку мы предсказывали человеческое поведение, ярлыки могли быть получены естественным образом на основе фактов. Нет требований к человеческой аннотации. Количество пригодных для использования данных обычно было ограничено, потому что только конечный набор признаков был тесно связан с целью прогнозирования. Даже если бы потенциально полезных функций могло быть больше, ручная разработка функций была неэффективной и вскоре стала узким местом.
Как специалисты по данным, мы полностью осознавали силу хороших функций. Мы вкладываем огромные усилия в разработку функций, несмотря на утомительную работу. Чтобы создать значимые функции, мы часто общались с бизнес-командами, пытаясь вдохновиться соответствующими бизнес-показателями, а также лежащей в их основе логикой. Наш босс также активно общался с различными сторонами, чтобы узнать, сможем ли мы получить новые источники данных для улучшения общей прогностической способности.
В то время наиболее часто используемыми алгоритмами машинного обучения были логистическая регрессия, дерево решений, случайный лес, XGBoost и т. д. Все эти алгоритмы не могут извлекать признаки самостоятельно. Таким образом, их производительность сильно зависит от того, насколько точно определены и представлены функции. Это основная причина, по которой проектирование признаков жизненно важно для традиционных алгоритмов машинного обучения.
Глубокое обучение: «Инженерные данные»
В последнее время все больше и больше специалистов по данным, включая меня, переключают свою карьеру с традиционного машинного обучения на глубокое обучение. Не только потому, что глубокое обучение считается более мощным и модным, но и потому, что весьма вероятно, что люди хотят избавиться от утомительного проектирования признаков, зная, что алгоритмы глубокого обучения могут изучать признаки непосредственно из данных.
Однако бесплатного обеда не бывает. Как я заметил, специалисты по данным по-прежнему тратят большую часть своего времени на подготовку данных при работе с алгоритмами глубокого обучения. Единственная разница в том, что вместо разработки функций они работают над «инженерией» данных. Я использую здесь двойную кавычку, потому что словосочетание «инженерия данных» используется только для того, чтобы соответствовать термину «инженерия» функции. Это не то же самое, что общеизвестная инженерия данных. Другими словами, хотя алгоритмы глубокого обучения могут изучать функции из данных, они могут изучать хорошие функции только в том случае, если в данных есть хорошая и значимая информация. Поэтому специалисты по данным просто переключают свои усилия с ручного создания хороших функций на создание высококачественных данных, то есть инженерию данных. Вот некоторые возможные «инженерные» моменты:
- Сбор данных: как собрать большой объем репрезентативных данных.
- Аннотации данных: как разрабатывать эффективные и точные задачи аннотирования
- Очистка данных: как обнаружить и исправить неправильные аннотации
- Обогащение данных: как включить наиболее ценные точки данных
Очистка данных на практике
Ошибки в аннотациях неизбежны. Целью очистки данных является повышение точности существующих аннотаций путем обнаружения и исправления неправильных аннотаций. Здесь я представляю три простых, практичных и эффективных метода.

Открытие на основе противоречий: KFold Cleaning
Этот метод обычно применим, если правильных аннотаций в обучающей выборке больше, чем неправильных. Основная идея состоит в том, чтобы получить неправильные аннотации большинством голосов. Для получения объективных прогнозов нам необходимо использовать перекрестную проверку KFold.
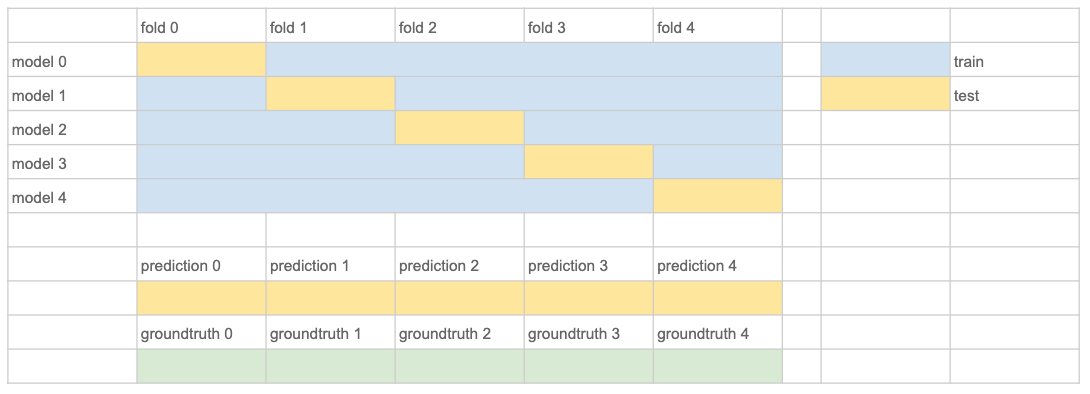
- Получите объективные прогнозы для всего обучающего набора с помощью k-кратной перекрестной проверки. Рекомендуемое «k» здесь равно 3 или 5 (не будет 10), так как обучение модели глубокого обучения обычно занимает много времени.
- Сравните беспристрастные прогнозы с аннотированными основными фактами.
- Выберите точки данных, в которых прогнозы отличаются от наземных истин, ранжируя по убыванию оценок прогнозов.
- Выберите верхние X точки данных и создайте задачи аннотирования для корректировки человеком.
Открытие, основанное на путанице: точная очистка
Этот метод можно использовать, если имеется несколько меток с относительно низкой точностью. Представьте, что у вас есть многоклассовая задача с тремя метками: A, B, C ии A имеет очень низкий показатель точности. Метка A имеет низкую точность, поскольку многие НЕ-A (B, C) прогнозируются как A. Разумно сделать вывод, что в обучающем наборе A (ошибочно обозначенном как A) может быть много элементов B, C.
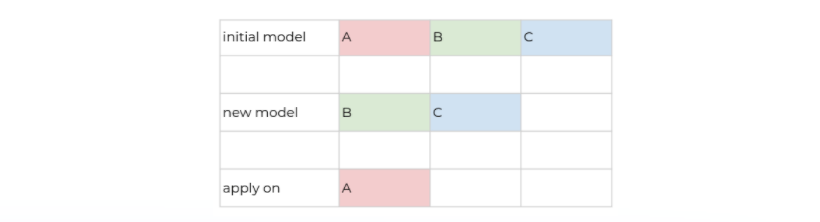
- Обучите модель только с B, C и примените модель к A, ранжируя по убыванию оценки прогноза.
- Выберите верхние X точек данных и создайте задачи аннотирования для проверки человеком. Поскольку теперь все данные из A могут быть предсказаны только как B или C, мы можем напрямую проверить, верны ли прогнозы.
Обнаружение на основе неопределенности: очистка энтропии
Этот метод обычно применим, если текущая модель достигла стабильной производительности. Модель считается стабильной, если ее производительность не будет существенно колебаться при небольших изменениях параметров или начальных условий. Основная идея состоит в том, чтобы получить неопределенные точки данных, близкие к границам решения.
- Получите непредвзятые оценки прогноза всего обучающего набора с помощью k-кратной перекрестной проверки, такой же, как KFold Cleaning.
- Для каждой точки данных вычислите значение энтропии, используя оценки несмещенного прогноза. Ранжируйте точки обучающих данных по значению энтропии по убыванию.
- Выберите верхние X точки данных с высокими значениями энтропии для проверки человеком, поскольку они близки к границам принятия решений.
Активное обучение
Помимо очистки существующих аннотаций, это почти всегда помогает получить больше обучающих данных. Лично я рассматриваю активное обучение как набор стратегий для выбора ценных точек данных для обогащения данных.
Я получил большую часть своих знаний об активном обучении из Human-in-the-Loop Machine Learning, поэтому я бы предпочел просто перечислить свои рекомендации.
Во-первых, рекомендую прочитать статью Active Transfer Learning with PyTorch, написанную автором (Robert (Munro) Monarch), особенно часть Перед началом работы, где он любезно обобщил все свои статьи о активное обучение на Medium. Людям, которые хотят подробно разобраться в активном обучении и аннотации, я предлагаю прочитать книгу.
Мониторинг моделей в продакшене
Я рекомендую эту статью от Domino: Maintaining Data Science at Scale. Ниже приведена аннотация:
В этой статье рассказывается о смещении модели, о том, как определить модели, которые ухудшаются, и о рекомендациях по мониторингу моделей в рабочей среде. Для получения дополнительной информации и передовых методов помимо того, что представлено в этой статье, включая шаги по исправлению дрейфа модели, загрузите технический документ «Передовые методы мониторинга моделей: поддержка науки о данных в масштабе».
Далее: Рекомендуемые учебные материалы
В конце обмена я рекомендовал несколько учебных материалов, основанных на моих личных предпочтениях и опыте. Недавно я действительно получил несколько запросов на рекомендации учебных материалов, поэтому я хотел бы написать отдельную статью для полноты картины.
Первоначально опубликовано на https://towardsdatascience.com 12 апреля 2021 г.