В этом посте мы обсудим, как можно использовать графовые нейронные сети (GNN) для прогнозирования аномалий в производственных условиях, где данные имеют сложный, разнородный и последовательный характер. Мы рассмотрим, как GNN могут эффективно обрабатывать неполные входные данные, и предоставим комплексное решение для прогнозирования аномалий и их причин в таких условиях.
Введение
В современном промышленном производстве существует множество этапов и взаимодействующих элементов. Если что-то пойдет не так, это может привести к потере материалов и производственных затрат. Вот почему важно уметь предсказывать неудачи, чтобы предотвратить их. Однако из-за сложности производственного процесса бывает трудно выявить и предсказать неисправности. Использование ручных процессов и экспертных знаний требует больших затрат времени и средств. К счастью, современные производственные линии оснащены датчиками, которые в режиме реального времени предоставляют данные о том, что происходит. Здесь на помощь приходит машинное обучение. Используя вычислительные методы для обработки данных и прогнозирования, мы можем использовать эти данные для автоматической идентификации и прогнозирования аномалий и их основных причин.

В этом посте мы рассмотрим процесс использования графовых нейронных сетей для решения этой проблемы. Во-первых, мы обсудим основы графовых нейронных сетей и то, как их можно использовать для обнаружения аномалий. Во-вторых, мы углубимся в особенности того, как мы применили этот подход к набору данных производственной линии Bosch. Наконец, мы обсудим результаты нашего подхода и покажем, как мы можем оценить источники аномалий.
Граф нейронных сетей
Графовые нейронные сети — это мощный инструмент для анализа графоструктурированных данных, состоящих из набора взаимосвязанных узлов, где каждый узел представляет собой одну точку данных, а ребра между узлами указывают отношения или зависимости. Одним из ключевых преимуществ GNN является их способность обрабатывать неевклидовы данные, которые относятся к данным, которые не имеют регулярной или предсказуемой структуры. Это отличается от традиционных моделей глубокого обучения, которые предназначены для работы с данными, структурированными в регулярной сетке, такими как изображения или текст.
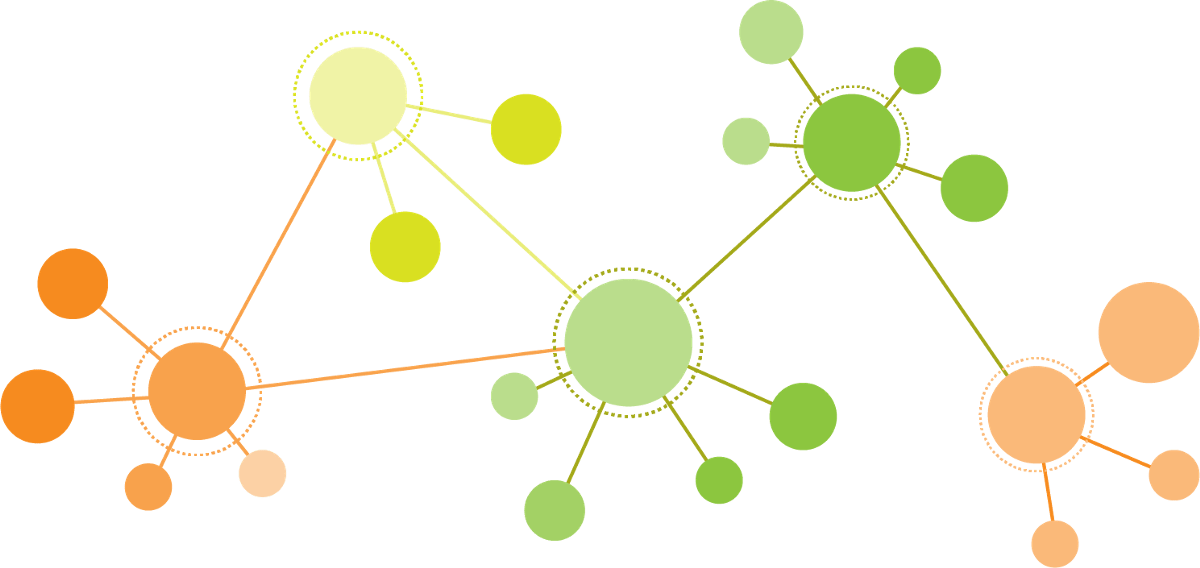
Одним из важных аспектов GNN является алгоритм передачи сообщений, который позволяет модели распространять информацию между узлами в графе. В алгоритме передачи сообщений каждый узел в графе обновляет свои вложения на основе информации, полученной от его соседей, и обрабатывает информацию с помощью нейронной сети. Количество раз, когда происходит этот процесс передачи сообщений, известно как количество слоев в GNN. Чем больше слоев у модели, тем больше информации может распространяться по графику.
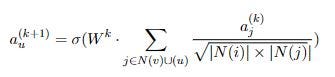

GNN можно использовать для различных задач, включая классификацию и регрессию узлов и графов, а также предсказание ссылок. В нашей демонстрации мы будем использовать классификацию графов для прогнозирования аномалий на производственной линии. Чтобы выполнить классификацию графа с использованием GNN, нам нужно агрегировать вложения всех узлов в графе. Это можно сделать с помощью таких методов, как получение среднего значения или суммы всех вложений узлов, или с помощью более сложных методов, таких как объединение на основе внимания. Затем агрегированные вложения узлов могут быть переданы в полносвязный слой, чтобы сделать окончательный прогноз.
Набор данных
Набор данных производственной линии Bosch представляет собой набор из трех наборов данных, которые предоставляют информацию о производственном процессе в Bosch. Первый набор данных является числовым и содержит множество характеристик, измеряемых для каждого продукта. Эти функции могут варьироваться в зависимости от конкретного производимого продукта, и многие из них отсутствуют для данного продукта. Второй набор данных является временным и включает временную метку для каждого измерения в числовом наборе данных, а также временные метки в третьем наборе данных. Этот третий набор данных является категориальным и обеспечивает дополнительные категориальные измерения производимых продуктов.


Всего насчитывается около 1,8 млн уникальных данных о товарах с этикетками. Класс аномалий представлен только процентом 0,5%, что делает эту проблему несбалансированной классификации.
Набор данных производственной линии Bosch представляет собой уникальную проблему из-за большого количества пропущенных значений и большого размера. Одним из возможных решений этой проблемы является использование модели XGBoost, известной своей способностью обрабатывать отсутствующие данные. Однако размер набора данных (как с точки зрения количества функций, так и количества примеров) может вызвать ограничения памяти при использовании XGBoost.
Несмотря на эти ограничения, с XGBoost все еще можно добиться успеха, работая с подмножеством функций и обучающими примерами. Фактически, этот подход был самой эффективной моделью в конкурсе. Однако у этого подхода есть некоторые недостатки. Используя ограниченное количество функций и обучающих данных, мы не сможем полностью охватить сложность проблемы. Кроме того, этот подход не принимает во внимание последовательный характер продукта на производственной линии, что может быть важно для понимания производственного процесса.
Одним из способов устранения ограничений памяти при работе с набором данных производственной линии Bosch является использование модели MLP (многослойный персептрон). Однако это требует ввода отсутствующих значений с некоторым числом, чтобы использовать модель. Обычный подход к обработке отсутствующих значений заключается в использовании многомерного импутера, который оценивает отсутствующее значение на основе всех других значений. Однако в этом случае значения отсутствуют «неслучайно», что означает, что причина их отсутствия связана с отсутствием измерения датчика. Использование многомерного импьютера для оценки этих отсутствующих значений может быть не лучшим подходом.
Вместо этого может быть более подходящим ввести пропущенные значения со статистически значимым значением, таким как среднее значение или медиана. Однако важно помнить, что само отсутствующее значение является важной информацией, которую следует сохранить. Для этого отсутствующие значения могут быть бинаризированы и объединены с исходными значениями. Это позволяет модели учитывать отсутствующие значения, сохраняя при этом содержащуюся в них информацию.
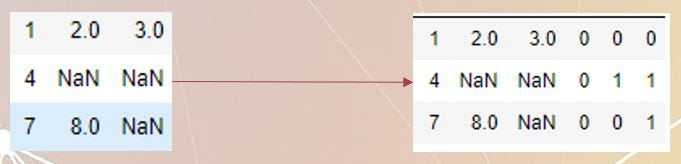
Хотя этот подход может быть эффективным, он не будет работать так же хорошо, как модель XGBoost. Неясно, связано ли это с шумом, вносимым во время вменения пропущенных значений, или с самой моделью, но поиск лучшего решения еще не завершен.
Один из распространенных подходов, используемых в подобных задачах, заключается в создании отдельной модели для каждого возможного пути в данных. Хотя на первый взгляд это решение может показаться простым и эффективным, на самом деле оно может иметь некоторые существенные ограничения. Например, если у вас большое количество путей, становится сложно масштабировать это решение, поскольку вам потребуется создать соответствующее количество моделей. Кроме того, если путь имеет небольшое количество выборок, может быть сложно или даже невозможно обучить на нем модель. Наконец, если у вас есть продукты с похожими путями, вы можете в конечном итоге обучать отдельные модели для каждого из них, что не очень эффективно, поскольку, вероятно, существует много общей информации, которую можно использовать для обучения обеих моделей.
Наше решение устраняет ограничения, связанные с созданием отдельной модели для каждого пути с помощью нейронной сети графа для представления характеристик каждого продукта в виде узлов на графе. При таком подходе неизмеряемые признаки не включаются в график, что позволяет более эффективно и действенно решать проблему пропущенных значений.
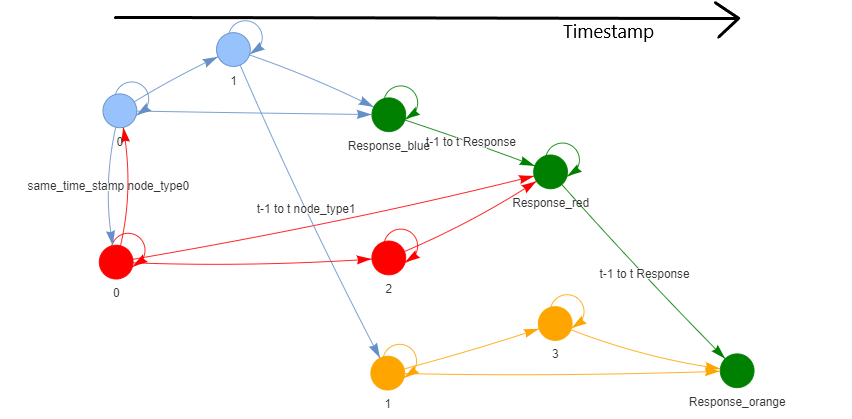
Существует два способа представления данных в виде графика для использования в модели графовой нейронной сети: представление каждой функции в виде узла и представление набора функций в виде узла. В любом случае мы можем представить данные только с помощью гетерогенного графика, чтобы представить неоднородность признаков.
Первый метод, представляющий каждую функцию в виде узла, более интуитивно понятен, однако такой подход может привести к большому количеству узлов и типов ребер, что может увеличить время обучения и потенциально ограничить эффективность модели GNN.
Второй метод, представляющий набор функций в виде узла, уменьшает общее количество узлов и, следовательно, количество типов ребер. Один из способов добиться этого — искать функции, которые измеряются одновременно.
Последним шагом в нашем решении является определение того, как определить ребра в каждом графе. Прямой подход состоит в том, чтобы соединить прошлые узлы с более поздними с помощью прямого края. Мы также можем добавить петли к узлам, чтобы сохранить информацию об отдельных функциях.
Чтобы упростить понимание и объяснение нашего анализа, мы сосредоточимся на числовых функциях, которые имеют временную метку в нашем временном наборе данных. Это позволит нам построить связность узлов в хронологическом порядке и работать с меньшим набором данных для удобства экспериментов.
Полученные результаты
Чтобы оценить наш подход, мы будем использовать 150 000 образцов для обучения, оценки и тестирования из 1,8 миллиона образцов. 100 000 образцов будут использованы для обучения, 25 000 — для оценки, а остальные 25 000 — для тестирования. Большое количество образцов для оценки и тестирования предназначено для минимизации риска наличия небольшого количества аномалий в обоих наборах данных из-за проблемы несбалансированной классификации.
Мы будем обучать, оценивать и тестировать наши модели на одних и тех же наборах данных и использовать библиотеку оптимизации гиперпараметров Optuna для всех моделей. Наша первая модель представляет собой простую нейронную сеть (MLP) на нормализованных признаках со средним вменением. Вторая модель, Нейронная сеть + OHE, аналогична первой модели, но с конкатенацией бинаризации отсутствующих значений. Модель XGBoost была обучена на необработанных числовых данных без вменения среднего. Heterogeneous Graph Transformer (HGT), единственная модель графовой нейронной сети в этом сравнении, была обучена на графиках, созданных на основе нормализованных числовых признаков. Мы будем использовать реализацию HGT из библиотеки Pytorch Geometric.
В следующей таблице показан лучший показатель коэффициента корреляции Мэтьюза в наборе данных проверки и его соответствующее значение в наборе тестовых данных. Изначально мы намеревались установить такое же количество испытаний Optuna, но время обучения HGT превзошло наши ожидания, и нам пришлось остановиться, как только мы получили удовлетворительные результаты. Большое количество испытаний Optuna для обеих моделей нейронных сетей должно было продемонстрировать, что даже при большем количестве поисков гиперпараметров результаты были недостаточно хорошими.


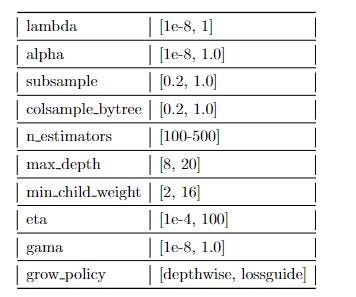
Стоит отметить, что производительность моделей HGT и XGBoost очень похожа, но у HGT есть ключевое преимущество, которого нет у XGBoost: возможность делать прогнозы с неполными входными данными.
Прогнозы в реальном времени с графическими нейронными сетями
На производственной линии важно иметь возможность прогнозировать состояние продукта как можно раньше, чтобы можно было предпринять корректирующие действия для предотвращения дальнейших потерь. Традиционный подход к этой проблеме может состоять в том, чтобы дождаться окончания производственного процесса, чтобы сделать прогноз, но это не идеально, поскольку не позволяет своевременно вмешиваться.
Одной из ключевых характеристик наших графиков является их хронологический порядок узлов. Мы можем использовать эту характеристику, чтобы разбить каждый граф продуктов на подграфы в зависимости от их хронологического порядка.
Делая это, мы можем делать прогнозы, используя нашу ранее обученную модель, и изучать, как выходные данные модели развиваются с течением времени при каждом сделанном измерении.

Чтобы визуализировать это поведение, мы построили логиты модели (выходные данные до сигмовидной функции активации) для каждого добавленного узла и сравнили логиты продуктов, которые, по прогнозам, будут работать со сбоями, с теми, которые не были неисправны.


Мы обнаружили, что логиты этих двух групп ведут себя одинаково до определенного количества узлов, но после этого момента начинают расходиться.
Мы также рассчитали среднее значение и два стандартных отклонения логитов для каждой группы и каждого количества узлов и нанесли их на график, чтобы показать распределения «отказ» и «отсутствие отказа».
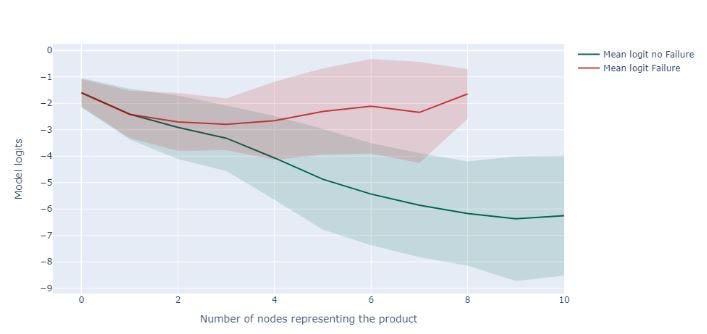
В целом, эти графики могут предоставить ценную информацию о состоянии продукта в режиме реального времени и помочь выявить потенциальные проблемы как можно раньше, что позволит своевременно вмешаться и свести к минимуму потери. Важно отметить, что это исследование может быть легко проведено по пути продукта для более точного анализа.
GNNExplainer
Неисправные продукты могут стать дорогостоящими, поэтому важно в первую очередь понять, почему они выходят из строя. Одним из подходов к этой проблеме является использование специализированных моделей объяснимости, специально разработанных для GNN, таких как GNNExplainer. Эта модель идентифицирует подграфы, наиболее релевантные данному прогнозу. Однако реализация Pytorch Geometric GNNExplainer в настоящее время не поддерживает разнородные графы.

Чтобы решить эту проблему, мы разработали пользовательскую модель GNNExplainer, основанную на реализации Pytorch Geometric, чтобы придать важность функциям/узлам вместо подграфа.
Понимая важность различных функций в прогнозе, мы можем определить основные причины отказа продукта и предпринять корректирующие действия, чтобы предотвратить будущие неисправности. Используя эту пользовательскую модель GNNExplainer, мы можем получить представление о факторах, которые способствуют неисправности продукта, что позволит нам проектировать и создавать более надежные продукты в будущем.
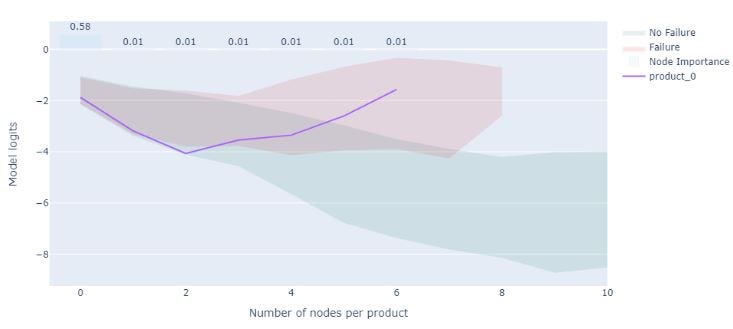
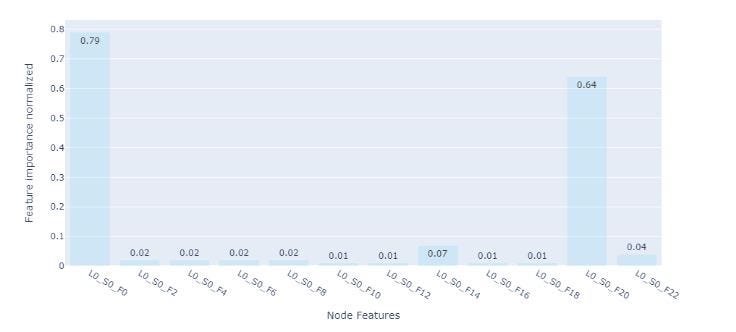
Улучшения/будущая работа
В нашем первоначальном подходе мы сосредоточились исключительно на числовых характеристиках в наборе данных производственной линии. Однако есть потенциал улучшить наши результаты, также включив временные данные в набор данных. Вычисляя прошедшее время между узлами и используя его в качестве граничных функций, мы можем более точно фиксировать сложные отношения и зависимости в производственной линии.
Еще один многообещающий подход для рассмотрения — использование подхода классификации узлов. В этом подходе мы бы представили каждый продукт в виде большого графа, где неисправность продукта является функцией его собственных узлов, а также узлов других продуктов. Это позволяет нашей модели фиксировать более подробные взаимодействия между продуктами.
Использование более продвинутых моделей GNN, определение более широкого диапазона гиперпараметров в процессе оптимизации Optuna и использование большего количества испытаний также являются предложениями, которые, вероятно, дадут лучшие результаты.
Выводы
В этой работе мы показываем, что графовые нейронные сети предлагают комплексное решение для прогнозирования аномалий в производственных линиях, особенно когда данные имеют сложный и разнородный характер. Их способность моделировать последовательную информацию делает их подходящими для этой задачи. Кроме того, GNN предлагают более широкий спектр инструментов и возможностей по сравнению с традиционными моделями, что делает их ценным дополнением к набору инструментов любого специалиста по данным, работающего в производственных условиях.