В следующих нескольких частях я расскажу о нескольких различных типах графиков и о том, как их кодировать в Python. В список входят следующие графики: точечные диаграммы, диаграммы ствола и листа, гистограммы, круговые диаграммы и коробчатая диаграмма с усами. В основном я буду использовать пакеты Seaborn для визуализации и добавлять ссылку на документацию везде, где это необходимо. В этой статье мы рассмотрим диаграммы рассеяния.

Точечная диаграмма. Точечная диаграмма (также известная как точечный график) представляет точки данных в двумерной плоскости, где два числовых атрибута представлены на любой из осей. Это похоже на просмотр данных, которые у нас есть, с высоты птичьего полета, как если бы каждая точка данных была человеком, стоящим на земле в двух измерениях. Вот синтаксис функции диаграммы рассеяния, я буду добавлять только те аргументы, которые используются чаще всего (по крайней мере, мной), остальные аргументы вы можете изучить в документации здесь.
seaborn.диаграмма рассеяния(data=None, x=None, y=None, hue=None , style=нет)
Данные. Представляет собой входной фрейм данных, из которого вы будете брать данные для визуализации.
x,y:переменная, которая будет представлена на оси x и оси y соответственно.
Оттенок: входом для этого аргумента является переменная, по которой ваш график будет сгруппирован с разными цветами каждого типа.
Стиль. Выполняет ту же функцию, что и оттенок, но вместо разных цветов использует разные стили маркеров.
Я буду использовать Набор данных покемонов для демонстрации визуализаций, вы можете найти код здесь.
Прежде всего, давайте импортируем необходимые библиотеки. Для инструментов визуализации я импортирую библиотеку seaborn, а для работы с фреймами данных буду использовать pandas. Кроме того, в фоновом режиме seaborn использует matplotlib для построения своих графиков. В результате некоторые функции/методы проще реализовать с помощью matplotlib.pyplot, а не с помощью seaborn. Следовательно, я также буду импортировать matplotlib.pyplot с псевдонимом plt.
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Теперь давайте импортируем набор данных, вы можете загрузить набор данных (Набор данных Pokemon) и прочитать информацию из файла CSV с помощью pandas в фрейм данных.
pokemons = pd.read_csv('pokemon.csv')
pokemons
Это напечатает кадр данных, который выглядит следующим образом.

П. S:Python обычно печатает кадр данных, когда вы вводите имя в конце своего блока.
В иллюстративных целях я буду использовать только несколько столбцов. Помните, что диаграмма рассеяния всегда представляет собой сравнение двух числовых переменных, что означает, что переменные на двух осях являются числовыми. Их можно стилизовать соответствующим образом по разным категориям, о чем мы и поговорим в нескольких словах. Здесь я выбираю следующие атрибуты.
scatter_pokemons = pokemons[['Type 1','Total','HP','Generation']]
Поскольку диаграммы рассеяния обычно состоят из множества маленьких точек, я устанавливаю размер фигуры немного больше, чем он выглядит по умолчанию. Вы можете сделать это, используя одну строку кода, как показано ниже, чуть ниже, где вызывается функция диаграммы рассеяния. Как видите, чтобы показать график, здесь я использую метод show из matplotlib.pyplot. Обычно, если вы строите один график для каждого блока кода, вам не нужно специально использовать команду plt.show(). Он просто автоматически рисует его для вас в Google Colab.
ax = sns.scatterplot(data = scatter_pokemons, x='HP', y='Total')
sns.set(rc={'figure.figsize':(20,8)})
plt.show()

Я могу сделать вывод, что при небольшом изменении HP значительно увеличивается общий атрибут любого покемона, за исключением нескольких выбросов. Здесь я взял ось X в качестве очков здоровья (HP) покемонов и ось Y в качестве общих атрибутов. Предположим, я поменяю местами этот выбор оси, посмотрим, какую информацию мы получим.
sns.scatterplot(data = scatter_pokemons, y='HP', x='Total')

Здесь я могу сделать вывод, что при огромном увеличении общих атрибутов покемонов HP меняется очень мало. То же, что и предыдущий вывод, только в другом формате. То, что кажется вам естественно удобным, вы можете пойти с ним!
Теперь я хотел бы увидеть разницу между HP и Total, но для разных типов покемонов. Я могу использовать аргумент оттенка, чтобы указать это. По умолчанию Seaborn может заставить вашу легенду перекрывать ваш график. Чтобы избежать этого, мы используем метод move_legend.
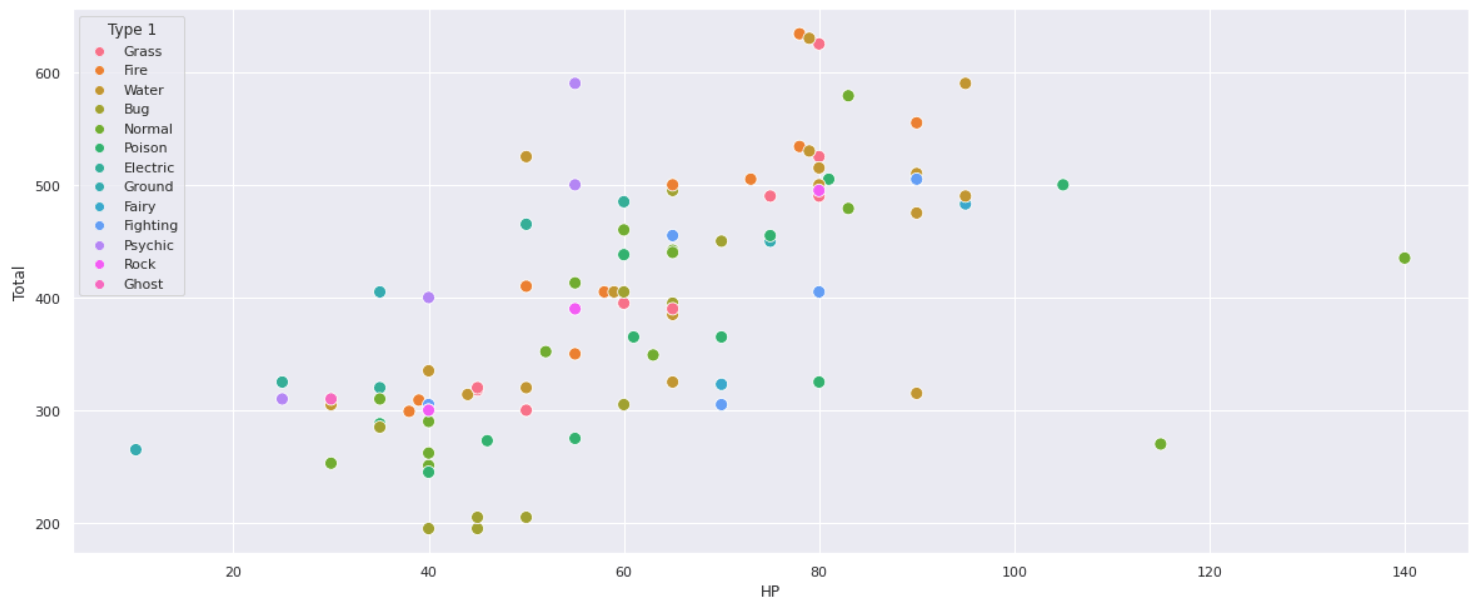
ax = sns.scatterplot(data = scatter_pokemons, x='HP', y='Total', hue='Type 1')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
sns.set(rc={'figure.figsize':(20,8)})

Арх! Точки слишком маленькие, и ваш клиент будет щуриться, просто чтобы узнать вариацию для одного типа. Но не волнуйтесь, мы можем увеличить размер, задав аргументу ’s’ желаемое значение.
sns.scatterplot(data = scatter_pokemons, x='HP', y='Total', hue='Type 1', s=100)

Намного лучше! Теперь предположим, что вы хотите классифицировать с другой категорией в дополнение к этой. Мы можем сделать это, указав аргумент стиля. Здесь я выбираю поколение, из которого состоит покемон (каждое поколение представляет новую серию, с точки зрения непрофессионала. Вероятность того, что вы не смотрели покемонов, очень мала. Однако никто не должен чувствовать себя обделенным, отсюда и информация xD).
sns.scatterplot(data = scatter_pokemons, x='HP', y='Total', hue='Type 1', s=100, style = 'Generation')

Из-за такого огромного количества данных трудно провести различие между разными типами покемонов. Возможно, если мы уменьшим количество точек данных, мы сможем увидеть более четкую картину. Мы будем использовать метод головы, чтобы извлечь только первые 100 наблюдений.
sns.scatterplot(data = scatter_pokemons.head(100), x='HP', y='Total', hue='Type 1', s=100)
Мы также можем классифицировать, изменив размер каждой точки данных на основе определенной категории.
sns.scatterplot(data = scatter_pokemons.head(100), x='HP', y='Total', size = 'Type 1', sizes=(20,200), hue = 'Type 1')

Это все разные способы, которыми мы можем использовать функцию диаграммы рассеивания Seaborn и настраивать ее в соответствии с нашими потребностями. Как видите, вы можете немного поиграть с ним и настроить свой сюжет. Есть больше параметров, которые вы можете использовать, чтобы сделать вашу диаграмму рассеяния более понятной и проницательной. Вы можете найти их в документации, предоставленной Seaborn. Цель состоит в том, чтобы ваш сюжет выглядел как можно более понятным, и это может варьироваться в зависимости от различных областей, которые вы хотите выделить.
Надеюсь, вам понравился этот подход к объяснению библиотеки диаграмм рассеяния Seaborn. В следующей части этой серии я попытаюсь объяснить графики стеблей и листьев.
До следующего блога!