Множественная регрессия почти аналогична простой линейной регрессии, но с более чем одной независимой функцией, что означает, что мы пытаемся предсказать значение на основе более чем одной переменной.

В этой статье мы собираемся реализовать множественную линейную регрессию всего за несколько шагов:
#шаг 1: Настройка рабочей среды
Вы можете использовать Google Colab, Jupiter Notebook или загрузить PyCharm и python на свой локальный компьютер.
Затем импортируйте необходимые библиотеки. В этом уроке мы будем использовать Numpy и Matplotlib.

import math,copy import numpy as np import matplotlib.pyplot as plt
# Шаг 2: Реализуйте необходимые функции
Вы должны быть знакомы с функциями и алгоритмами машинного обучения. Во-первых, у нас есть линейная функция, которая отображает линейную зависимость между входными данными и выходными данными: сильный>
задается линейной функцией:
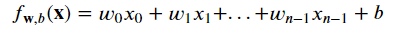
или в векторной записи:

это не векторизованная версия кода:
def compute_model_output(x,w,b):
m=x.shape[0]
fx=0
for i in range(m):
fx_i=x[i]*w[i]
fx=fx+fx_i
fx=fx+b
return fx
и это векторизованная версия, намного проще:
def compute_model_output_v(x,w,b):
# x : ndarray(n,)
# w : ndarray(n,)
# b : scalar
fx=np.dot(x,w)+b
return fx
Я советую вам использовать векторизованную версию намного быстрее намного проще.
Затем вычислите Функция стоимости, которая дает нам четкое представление о производительности модели и определяется следующим уравнением:

График функции стоимости для итерации говорит нам, как работает модель, например:

мы не хотим, чтобы модель была ни переоснащена, ни недообучена, и это код для реализации функции стоимости:
def compute_cost(X,y,w,b):
# X : ndarray(m,n)
# w : ndarray(n,)
# y : ndarray(n,)
# b : scalar
m = X.shape[0]
cost = 0.0
for i in range(m):
fx_i = np.dot(X[i], w) + b # (n,)(n,) = scalar (see np.dot)
cost = cost + (fx_i - y[i]) ** 2 # scalar
cost = cost / (2 * m) # scalar
return cost
Реализуйте алгоритм градиентного спуска (GD) — это итеративный алгоритм оптимизации первого порядка, используемый для поиска локального минимума/максимума заданной функции.
мы собираемся использовать его для обновления параметров w и b, чтобы минимизировать функцию стоимости:


именно так градиентный спуск достигает глобального минимума, используя скорость обучения альфа и количество итераций.
def gradient_desent(X,y,w_in,b_in,alpha,iterations,compute_cost,compute_derivative):
# save cost function values to plot them later
J_history=[]
w = copy.deepcopy(w_in) #avoid modifying global w within function
b=b_in
for i in range(iterations):
dj_dw,dj_db=compute_derivative(X,y,w,b)
w=w-alpha*dj_dw
b=b-alpha*dj_db
# Save cost J at each iteration
if i < 100000: # prevent resource exhaustion
J_history.append(compute_cost(X, y, w, b))
# Print cost every at intervals 10 times or as many iterations if < 10
if i % math.ceil(iterations / 10) == 0:
print(f"Iteration {i:4d}: Cost {J_history[-1]} ")
return w, b, J_history # return final w,b and J history for graphing
Чтобы вычислить градиентный спуск, нам нужно вычислить производную от w и b, чтобы параметры обновлялись одновременно.

def compute_derivative(X,y,w,b):
# X : ndarray(m,n)
# w : ndarray(n,)
# y : ndarray(n,)
# b : scalar
# dj_dw : nsarray(n,)
# dj_db : scalar
m,n=X.shape
dj_dw=np.zeros((n,))
dj_db=0
for i in range(m):
temp=(np.dot(X[i],w)+b)-y[i]
for j in range(n):
dj_dw[j]=dj_dw[j]+temp*X[i,j]
dj_db=dj_db+temp
dj_dw=dj_dw/m
dj_db=dj_db/m
return dj_dw,dj_db
эта функция предназначена для построения функции стоимости для итераций:
def plot2d(x, y, mode):
plt.title("DATA")
plt.xlabel("x axis caption")
plt.ylabel("y axis caption")
plt.plot(x, y, mode)
plt.show()
return
Иногда функции находятся в совершенно разных диапазонах, поэтому мы используем масштабирование функций, чтобы преобразовать функции, чтобы они были в одинаковом масштабе.
это делает работу модели более быстрой и плавной.

def zscore_norm(X):
# X : ndarray(m,n)
# mu : ndarray(n,)
# sigma :ndarray(n,)
mu=np.mean(X)
sigma=np.std(X)
X_norm=(X-mu)/sigma
return X_norm,mu,sigma
#Шаг 3: приступим к обучению нашей модели
Прежде всего, импортируйте набор данных и ознакомьтесь с ним:
# import our data from a csv file
data= np.genfromtxt("data2.csv", delimiter=',')
print("data dimensions= ",data.shape)
numOfFeatures = np.size(data, 1) - 1
print(numOfFeatures)
X_train = data[:, 0:numOfFeatures]
y_train = data[:, numOfFeatures]
m,n = X_train.shape
Затем нормализуйте функции перед обучением модели:
X_norm,mu,sigma=zscore_norm(X_train)
Инициализировать параметры:
initial_w=np.zeros(n) initial_b=0. alpha=0.03e-1 iterations=1000
Запустите градиентный спуск и начните прогнозировать:
final_w,final_b,J_history=gradient_desent(X_norm,y_train,initial_w,initial_b,alpha,iterations,compute_cost,compute_derivative)
print(f"b,w found by gradient descent: {final_b:0.2f},{final_w} ")
for i in range(m):
print(f"prediction: {np.dot(X_norm[i], final_w) + final_b:0.2f}, target value: {y_trai
Не забудьте нормализовать тренировочный пример перед прогнозированием:
example=[2104,3]
norm_example=(example-mu)/sigma
print(f"prediction is {np.dot(norm_example,final_w)+final_b}")
В конце нарисуйте функцию стоимости, чтобы проверить, насколько хорошо работает ваша модель:
x_axis = np.mat(range(0, iterations)).reshape(( iterations,1)) plot2d(x_axis, J_history, ".b")

И все, спасибо за чтение, если вы хотите проверить весь код, вы можете! на гитлабе.