В последние годы многие исследователи предлагают множество моделей глубокого обучения. Модели глубокого обучения интересны во многих областях промышленности, поскольку модели имеют множество возможностей для решения таких задач, как компьютерное зрение, обработка сигналов и обработка естественного языка.Они разрабатывают множество структур для конкретных задач, такие как сверточные нейронные сети, рекуррентные нейронные сети, долговременная память, преобразователь и т. д.

Хотя модели глубокого обучения успешны в широких областях, они требуют огромных ресурсов для обучения. Это эра моделей глубокого обучения, поскольку они обладают очень высокой производительностью, которую можно применять практически в различных отраслях. . Кроме того, возможности компьютеров теперь могут ускорить время обучения моделей и легко манипулировать большими данными. Однако модели потребляют много ресурсов, таких как компьютерные процессоры (ЦП) и графические процессоры (ГП), для оптимизации своей производительности.
Эти причины побуждают многих исследователей изучать другие методы, которые могут заменить традиционный (алгоритм «назад-вперед»). Один из методов, о котором говорится в этой статье, — это Машина экстремального обучения (ELM). .
1.) Определение машины для экстремального обучения
Структура ELM представляет собой сеть прямой связи с одним скрытым слоем. это означает, что он имеет только один скрытый слой. ELM обучается методом псевдообратной матрицы. Этот метод позволяет ELM избегать обучения входного слоя, а ELM обучать только выходную часть.
- ELM предложен Huang et al, 2004.
- ELM имеет только один скрытый слой и может не обучать входной слой.
2.) Обозначения
2.1) Данные о функциях или матрица входных данных

В приведенном ниже коде показан пример входных данных наборов данных радужной оболочки.
#Import Packages
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# Loading Iris Datasets
iris = sns.load_dataset("iris")
X = iris.iloc[:, :4] #Input Matrix
2.2) Метка или выходная матрица


y = iris.iloc[:, -1] y = pd.get_dummies(y) #Output Matrix
2.3) Активировать функцию

#Activative Function
def sigmoid(x, w, c):
return 1 / (1 + np.exp(-(np.dot(x, w) + c)))
- Сигмовидная функция

2.4) Вес
ELM имеет один скрытый слой, поэтому он имеет две весовые матрицы, которые
- Введите вес
Это вес между входными данными "X" и "скрытыми единицами". Это может быть определено:

а смещение этой части определяется

L = 5 # A number of hidden nodes. M = X.shape[1] # A number of features data. w = np.random.normal(size=(M, L)) # Weight between input matrix and hidden layer. c = np.random.normal(size=(L)) # bias
Наконец, мы можем построить матрицу функции активации или H-матрицу следующим образом:

#Activation
def sigmoid(x, w, c):
return 1 / (1 + np.exp(-(np.dot(x, w) + c)))
def gaussian(x, w, c):
return np.exp(-c * np.linalg.norm(x - w, 'fro'))
def hyperbolic_tangent(x, w, c):
return (1 - np.exp(-(np.dot(w, x) + c)))/(1 + np.exp(-(np.dot(x, w) + c)))
#Get function
def getActivation(name):
return {
'sigmoid': sigmoid,
'gaussian': gaussian,
'hyperbolic_tangent': hyperbolic_tangent,
}[name]
#Activate function matrix
def H(x, activate, L):
M = x.shape[1]
w = np.random.normal(size=(M, L))
c = np.random.rand(L)
act = getActivation(activate)
return act(x, w, c)
- Выходной вес или бета-матрица
Этот вес представляет собой вес, который сопоставляет функции от «скрытых единиц» до «выходных данных» y.

3.) Модель ELM
Модель ELM использовала фиксированный входной вес, и была рассчитана матрица H. Бета-матрица оптимизируется этой задачей оптимизации:

Эту задачу можно решить методом псевдообратного.

Из приведенного выше уравнения мы можем использовать обратную матрицу и единичную матрицу для вычисления псевдообратной. Кроме того, мы можем использовать свойство единичной матрицы следующим образом:

и присвоить нашей бета-матрице это значение:

Эта бета-матрица может минимизировать указанную выше проблему оптимизации. Однако эта бета-матрица может привести к проблеме переобучения. Итак, нам нужно добавить в модель регуляризованное значение.
Пусть C будет регуляризованным значением.

Итак, мы можем найти оптимизированную бета-версию из приведенной выше задачи, используя градиент задачи:

Позвольте мне показать код:
C = 1 #Hyperparameter I = np.eye(L, L) #Identity matrix H = sigmoid(X.values, w, c) #Activate function matrix Y = y.values #Output Matrix Beta = np.linalg.inv(H.T @ H + I/C) @ H.T @ Y
Для многократно используемого кода мы пишем объект класса модели:
class ELM:
def __init__ (self,num_hidden, activation='sigmoid'):
self.activation = getActivation(activation)
self.L = num_hidden
def fit(self, X, y, C=1):
self.X = X
self.Y = y
self.I = np.eye(self.L, self.L)
self.M = X.shape[1]
self.w = np.random.normal(size=(self.M, self.L))
self.c = np.random.normal(size=(self.L))
self.C = C
self.H = self.activation(self.X, self.w, self.c)
self.Beta = np.linalg.inv(self.H.T @ self.H + self.I /self.C) @ self.H.T @ self.Y
def predict(self, X):
H_pre = self.activation(X, self.w, self.c)
return H_pre @ self.Beta
И это процесс использования объекта модели ELM:
#Split Train Test X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0) #Construct Model model = ELM(num_hidden=15) #Trian and predict model.fit(X_train, y_train, C=1.2) y_pred = model.predict(X_test)
Наконец, это результат нашей модели:
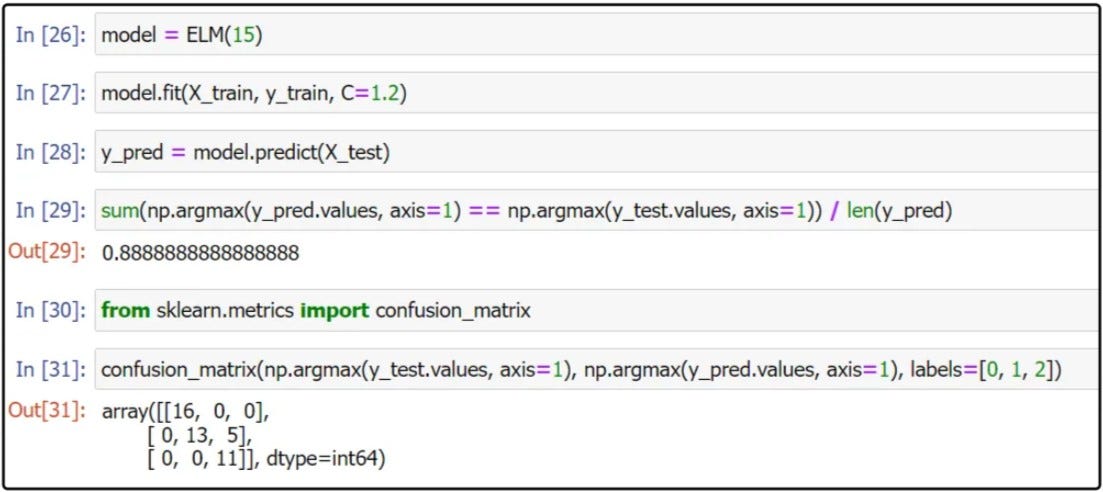
Мы добрались до последней части статьи. Модель ELM можно обучить очень быстро, сохраняя при этом высокую производительность. И мы можем применить этот метод к другим моделям, которые могут фиксировать свои веса, таким как вычисление резервуара.
Читатели могут найти код ELM на этом GitHub:
Спасибо за чтение.