
Привет! Меня зовут Томи, и я хотел бы поделиться с вами своим путешествием по изучению науки о данных.
Моя краткая предыстория
Я учусь на бакалавриате информатики в Христианском университете Петра. В университетские годы я присоединился к целому ряду комитетов, чтобы узнать много вещей, которые не были доступны на уроках в классе. К концу 5-го семестра я немного изучил машинное обучение, и это пробудило во мне интерес к более глубокому изучению.
«Сюрприз» во время моего отпуска
В конце декабря я получил электронное письмо об этом конкурсе, BRI Data Hackathon. BRI является одним из крупнейших банков государственных предприятий (Bank BUMN) в Индонезии. Так что я могу быть уверен, что это довольно масштабное соревнование по науке о данных. Я сразу прочитал письмо и сайт (brihackathon.id). Мероприятие организовано Алгоритмой, одной из крупнейших школ по науке о данных в Индонезии.
«Вау, 2 месяца на конкурс по науке о данных! Это прекрасный шанс многому научиться и провести как можно больше экспериментов». я подумал про себя
Поэтому я объединяюсь с тремя моими друзьями, которые также интересуются наукой о данных.
Первый шаг после регистрации
Каждая учетная запись проходит предварительную оценку, прежде чем мы сможем присоединиться к конкурсу на Kaggle. Kaggle — это единая платформа для машинного обучения, где вы можете учиться на чужих ресурсах и записных книжках, участвовать или проводить соревнования по машинному обучению и запускать записные книжки на их компьютерах.
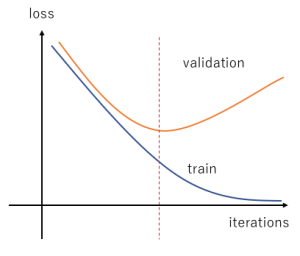
Предварительная оценка наполнена базовыми знаниями о машинном обучении, такими как выбор функций, кривые обучения, метрики оценки и т. д., а также исследовательскими вопросами о предоставленном наборе данных. Они были веселыми, и я также могу проверить свои знания. На нем также есть проходной балл, чтобы решить, проходим мы или нет. К счастью, мы можем пройти его с первой попытки!
Категории соревнований
В BRI Data Hackathon 2021 есть две категории:
Аналитика персонала – это классификационная задача, позволяющая предсказать, имеет ли тот или иной сотрудник статус "Лучшая производительность" или нет, на основе исторических показателей KPI, принадлежащих корпорации. Модель может использоваться отделом кадров для прогнозирования производительности сотрудников.
Cash Ratio Optimization — это регрессионная задача для прогнозирования «офисных денежных средств» (Kas Kantor) и «электронных денежных средств» (Kas E-Channel) на следующие 31 день. Модель можно использовать для повышения эффективности управления денежными средствами в надежде, что она может снизить операционные расходы и уменьшить потерю деловых возможностей для BRI при использовании денежных средств.
Я больше сосредоточен на изучении категории People Analytics, поэтому позвольте мне поделиться своими ключевыми мыслями и опытом по этому поводу.
Аналитика людей
В наборе данных много функций, я собираюсь упомянуть только те функции, которые интересны в моем процессе обучения, поэтому он будет кратким. В основном я использую три основные библиотеки для обработки данных (pandas, numpy и scikit-learn).
Часть 1. Исследовательский анализ данных и очистка данных
Я новичок в этом процессе, и я впервые делаю EDA 😀. Эта часть очень важна, потому что мы можем находить аномалии и лучше понимать закономерности, лежащие в основе данных.
Нет повторяющихся строк и только в 1 строке данных отсутствуют значения «Последнее_достижение_%» и «Достижение_выше_100%_during3quartal», поэтому мы удаляем эту строку.
Я пытаюсь посмотреть на шаблон данных на основе целевой функции (наилучшей производительности), но, похоже, нет функции, которая могла бы оказать существенное влияние на значение наилучшей производительности. я планирую

Из приведенного выше графика я могу рассчитать, насколько вероятно, что у женщины или мужчины будет лучший статус производительности.
print("Best Performance Percentage female at work", round(4.18 / (22.26 + 4.18), 3))
print("Best Performance Percentage male at work", round(10.50 / (63.06 + 10.50), 3))
Результат: 15,8 % лучших результатов для женщин и 14,3 % лучших результатов для мужчин. Ну, вероятность такая же, но я должен проверить ее с помощью априорных шансов.
Я могу получить априорные шансы по проценту пола. Из приведенного выше графика я также могу узнать, что процент сотрудников-женщин примерно 26,44%, а процент сотрудников-мужчин примерно 73,56% от общего числа сотрудников. Чтобы получить истинное представление о вероятностях, я умножаю как процент лучших показателей, так и процент полов.
Апостериорные шансы для женщин = 26,44% * 15,8% = 4,17%
Апостериорные шансы для мужчин = 73,56% * 14,3% = 10,5%
Я могу сделать вывод, что у мужчин в два раза больше шансов получить статус Лучшее выступление, чем у женщин в этом случае из-за предварительного знания. Несмотря на это, он выглядит примерно так же по сюжету и лучшему проценту производительности. Посмотрите это видео, оно о байесовском мышлении, если хотите знать, почему я сделал такие расчеты.
После изучения некоторых функций с точки зрения наилучшей производительности я строю карту корреляции, чтобы оценить, какие функции важны и полезны для модели.

На приведенном выше графике я ищу самый правый столбец в матрице, потому что хочу знать, как функции коррелируют с целью (лучшая производительность). Наилучшая корреляция имеет отклонение от нуля 0,019 (-0,019 или 0,019). Интересно, что пол является одним из них!
Но это все еще довольно сложная проблема классификации, потому что «эмпирическое правило» корреляции Пирсона для умеренной корреляции составляет 0,40–0,59отклонение от нуля. И лучшая корреляция на этих данных всего 0,019 😮
Есть еще одна проблема с этими данными. Оптимальное значение производительности — это дисбаланс, и я до сих пор не знаю, является ли это большой проблемой. Я расскажу об этом подробнее в Часть 3.
Часть 2: Предварительная обработка данных
Что касается части предварительной обработки, это довольно просто. Мой друг преобразовал некоторые категориальные столбцы в целочисленное представление. Например, функция job_level, тип столбца — строка, и он имеет формат JGXX (XX = число, дополненное 0).

Мы рассмотрели значение уровня работы, потому что, возможно, он имеет какое-то порядковое значение. Этот документ мы находим только в Банке Сулут. Он содержит гистограмму с уровнем работы по оси x и количеством сотрудников по оси y. Уровни работы варьируются от Kontrak (сотрудники по контракту), JG-01 до JG-16. У JG-16 наименьшее количество сотрудников, поэтому мы предполагаем, что число в столбце job_level имеет отсортированное порядковое значение, а не просто случайное значение. JG01 преобразуется в 1 и так далее…
Часть 3: Моделирование и оценка
Это та часть, где я узнаю больше всего, потому что я пробовал множество алгоритмов машинного обучения, которые никогда раньше не пробовал.
Обязательно используйте аргумент random_state (в scikit-learn) или случайный начальный аргумент при создании моделей, чтобы он всегда мог воспроизвести один и тот же результат позже.
Я разделяю тренировочный и тестовый наборы с соотношением 80%/20%. Я экспериментировал со многими алгоритмами из библиотеки scikit-learn и обнаружил, что алгоритмы на основе дерева решений являются лучшими для этого набора данных. Я попробовал MLP, и результат довольно плохой, если его использовать напрямую.

Почему данные больше подходят для модели на основе дерева решений? Я думаю, что есть много аспектов, один из них, возможно, у данных есть много функций, которые имеют порядковое значение, поэтому дерево решений может лучше его интерпретировать. Вы можете представить себе дерево решений как множество условий «если/иначе-если/иначе», и у него есть алгоритм для расчета наилучшего разделения, поэтому компьютеры создают все эти условия «если/иначе-если/иначе» за нас 👌 . Я думаю, что никто на земле не всегда прав на 100% при определении того, какой алгоритм машинного обучения лучше всего подходит для определенных данных.
Вы когда-нибудь задумывались, почему это называется Data Scientist? Я думаю, это потому, что ученые много экспериментируют, чтобы проверить свою гипотезу. Так что у меня нет причин бояться попыток и неудач. Пока я расту каждый день и узнаю от этого что-то новое.
После этого я заметил, что результат классификации довольно странный, потому что модель классифицирует всех сотрудников как не с лучшей производительностью (метка 0). Я узнал, что это проблема несбалансированного набора данных.
trainDf['Best Performance'].value_counts(normalize=True)*100

Большинство данных заполнено не лучшей производительностью (85,3%), поэтому алгоритм придает им больший вес, поскольку он представляет большую часть данных. Из этой проблемы я узнал об алгоритмах, которые могут работать с несбалансированным набором данных, таких как случайная передискретизация и недостаточная выборка, SMOTE и т. д. Некоторые модели также имеют аргумент class_weight, поэтому я могу вручную настроить алгоритм так, чтобы он придавал больший вес классу меньшинства. .
Иногда важно обработать набор данных дисбаланса для определенных случаев. Например, набор данных о кредитном мошенничестве содержит только 1% мошеннических транзакций и 99% немошеннических транзакций. Если вы обучаете модель без обработки дисбаланса, а затем используете ее для обнаружения мошеннических транзакций в режиме реального времени, возможно, это может вызвать много ложных срабатываний (что плохо, потому что многие мошеннические транзакции классифицируются как немошеннические).
Самый важный урок, который я усвоил при избыточной выборке в наборе данных о дисбалансе, это последовательность. Всегда сначала разделяйте данные (на наборы для обучения и тестирования), а затем после этого выполните передискретизацию обучающей выборки.
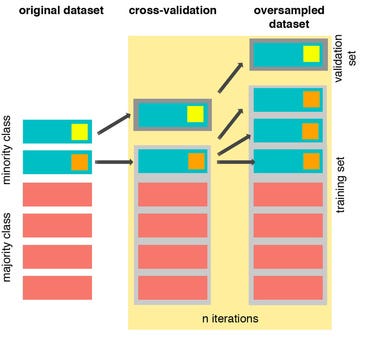
Почему это важно? Поскольку алгоритм избыточной выборки генерирует дублирующиеся или очень похожие данные. Мы хотим сначала отделить его, чтобы результат оценки в тестовом наборе не влиял на дубликаты в обучающем наборе. Я попытался выполнить передискретизацию исходных данных перед разделением, и оценка оказалась очень хорошей! Но при отправке на Kaggle оценка не повышается.
Я также узнал о перекрестных проверках k-fold. Это одна из лучших практик в моделировании. Перекрестная проверка может дать мне более обобщенную и непредвзятую оценку.
Часть 4. Понимание природы данных
После нескольких недель анализа и экспериментов я обнаружил свойства «зоны Златовласки», чтобы создать модель на основе дерева решений. Зона Златовласки — астрономический термин, обозначающий обитаемую зону, в которой не бывает ни слишком жарко, ни слишком холодно. В машинном обучении я использую этот термин для обозначения метафоры, которая означает, что процесс обучения не является ни слишком недостаточным, ни слишком избыточным 😝.
Существует множество алгоритмов настройки гиперпараметров на выбор. Мне кажется, лучше самому выбрать и проанализировать некоторые из «базовых» параметров. Таким образом, я могу лучше понять данные, а также иметь интуицию для создания модели.
Я использую выбор признаков, чтобы предотвратить переобучение, выполняя его итеративно для 5–20 признаков, используя SelectKBest с f_regression (на основе корреляции Пирсона) для функции оценки (используя scikit-learn). Оценка дает наилучший результат примерно при 10–11 признаках. Выбор признаков действительно помогает улучшить модель, поэтому она может быть более общей и не подходить слишком близко.
После этого есть два типа ансамблевых моделей, которые я использую для получения наилучшей оценки.
- Классификатор упаковки с деревом решений для базового классификатора
- Классификатор стекирования с деревом решений по бэггингу и XGBoost для базового классификатора и MLP для метаклассификатора
В части 3 я упомянул, что MLP довольно плох, если его использовать напрямую. Но когда его используют в качестве мета-классификатора в Stacking Classifier, результат довольно хорош!
Бэггинг объединяет слабых учеников, которые учатся на выборке набора данных, чтобы уменьшить дисперсию.
Стекирование — это объединение выходных данных нескольких моделей и использование этих выходных данных для обучения метаобучаемого.
Окончательная оценка AUC подачи составляет 0,565528. Наша команда занимает 19ᵗʰ место среди 500 команд, участвовавших в категории People Analytics.
Может быть, это просто удача или «Бог ГСЧ» на стороне нашей модели. Но главное здесь — процесс обучения, который постепенно утоляет мой голод.
Вывод
Что побуждает меня изучать науку о данных, так это имена марсоходов НАСА 4ᵗʰ и 5ᵗʰ.

Да, верно, любознательность и настойчивость! Любопытство побуждает меня исследовать и углублять свои знания в области науки о данных, а настойчивостьудерживает меня на правильном пути и поддерживает мою решимость.
Для всех вас, кто хочет изучать науку о данных или что-то в этом роде, любопытство и настойчивость сделают вас более устойчивыми к ситуации «усталости и скуки».
Не стесняйтесь сказать мне привет или обсудить что-нибудь!
Linkedin: https://www.linkedin.com/in/tomy-widjaja/