Такие приложения, как Google Photos, позволяют искать изображения на вашем телефоне с помощью текстовых запросов. Примечательным аспектом является то, что приложению не нужно, чтобы вы маркировали изображения на основе их содержимого. Например, вы можете выполнить поиск кошка или суп в приложении Google Фото и получить релевантные результаты, несмотря на отсутствие изображений. текстовое описание.
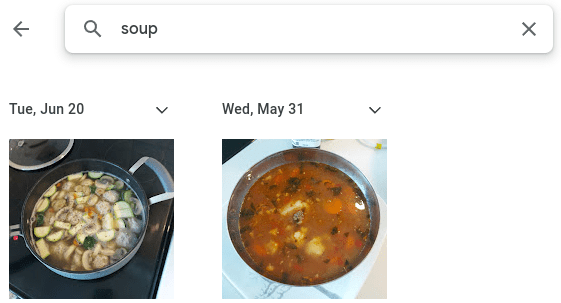
Как приложение может это сделать? Подобные приложения понимают связь между семантическим описанием сцены и содержанием изображения самой сцены. В этом блоге я покажу, как вы можете написать собственное приложение для поиска изображений на Python. Это может быть полезно для вас, если вы хотите быстро искать изображения на локальном компьютере, но не загружать файлы в стандартную службу из соображений конфиденциальности.
Мы будем использовать предварительно обученную модель машинного обучения под названием CLIP, которая уже понимает необходимое нам совместное представление текста/изображения. Мы также будем использовать Streamlit для внешнего интерфейса приложения.
КЛИП
Contrastive Language-Image Pretraining (CLIP) — популярная мультимодальная модель текста/изображения, основанная на статье Рэдфорда и др. (2021). Модель CLIP была обучена на 400 миллионах пар примеров текст-изображение, полученных из Интернета. Таким образом, модель охватывает семантический аспект самых разных сцен. Для нашего приложения мы будем использовать предварительно обученную модель для сопоставления условий текстового поиска с базой данных изображений.
стримлит
Streamlit — это популярная среда Python, предназначенная для разработки приложений машинного обучения. Streamlit в значительной степени обрабатывает элементы эстетического дизайна разработки приложений, что позволяет нам сосредоточиться в основном на аспектах машинного обучения.
Разработка приложений
Приложение состоит из двух скриптов:
- get_embeddings.py: в этом скрипте мы кодируем изображения во вложения с помощью кодировщика изображений модели CLIP. Вложения — это векторные представления ввода, которые кодируют его описательный контент.
- app.py : это приложение с потоковой подсветкой, в котором реализована функция поиска изображений. Для введенного поискового запроса получаются вложения текста, которые затем сравниваются с вложениями изображений, полученными на первом этапе. Затем наиболее похожие результаты представляются в виде сетки.
Код сценария get_embeddings.py приведен ниже. Вам необходимо установить CLIP, следуя инструкциям в https://github.com/openai/CLIP.
import os
import clip
import torch
from torch.utils.data import Dataset, DataLoader
import PIL
import pickle
from tqdm import tqdm
class Images(Dataset):
"""Images dataset"""
def __init__(self, image_list, transform):
"""
Args:
image_list: List of image paths.
transform : Transform to be applied on a sample.
"""
self.image_list = image_list
self.transform = transform
def __len__(self):
return len(self.image_list)
def __getitem__(self, idx):
image_path = self.image_list[idx]
image = PIL.Image.open(image_path)
image = self.transform(image)
data = {'image':image,
'img_path': image_path}
return data
if __name__ == '__main__':
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device, jit=False)
print(f'Device used: {device}')
folder_path = '<Enter folder location with your images here>'
image_list = [folder_path + file for file in os.listdir(folder_path)]
print('Attempting to open images...')
cleaned_image_list = []
for image_path in image_list:
try:
PIL.Image.open(image_path)
cleaned_image_list.append(image_path)
except:
print(f"Failed for {image_path}")
print(f"There are {len(cleaned_image_list)} images that can be processed")
dataset = Images(cleaned_image_list,preprocess)
dataloader = DataLoader(dataset,
batch_size=256,
shuffle=True)
print("Processing images...")
image_paths = []
embeddings = []
for data in tqdm(dataloader):
with torch.no_grad():
X = data['image'].to(device)
image_embedding = model.encode_image(X)
img_path = data['img_path']
image_paths.extend(img_path)
embeddings.extend([torch.Tensor(x).unsqueeze(0).cpu() for x in image_embedding.tolist()])
image_embeddings = dict(zip(image_paths,embeddings))
# save to pickle file for the app
print("Saving image embeddings")
with open('embeddings.pkl','wb') as f:
pickle.dump(image_embeddings,f)
Класс Images наследуется от класса Dataset pytorch и предоставляет инструкции о том, как преобразовать путь изображения в тензор pytorch. Набор данных используется в основной функции для создания загрузчика данных pytorch, который позволяет обрабатывать пакеты изображений вместе. Векторизованный характер этой операции делает ее более быстрой, чем обработка изображений по одному.
Код отфильтровывает все пути в каталоге, указанном в переменной folder_path, чтобы убедиться, что PIL читает изображения. Это также помогает удалить любые беспорядочные файлы, такие как файлы .html, которые были артефактами массовой загрузки. После создания встраивания они сохраняются в файле рассола, который затем принимается приложением.
Код скрипта app.py приведен ниже.
import streamlit as st
import pandas as pd
import clip
import torch
from sklearn.metrics.pairwise import cosine_similarity
import pickle
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# load embeddings from file
with open('embeddings.pkl','rb') as f:
image_embeddings = pickle.load(f)
st.header('Image Search App')
search_term = 'a picture of ' + st.text_input('Search: ')
search_embedding = model.encode_text(clip.tokenize(search_term).to(device)).cpu().detach().numpy()
st.sidebar.header('App Settings')
top_number = st.sidebar.slider('Number of Search Results', min_value=1, max_value=30)
picture_width = st.sidebar.slider('Picture Width', min_value=100, max_value=500)
df_rank = pd.DataFrame(columns=['image_path','sim_score'])
for path,embedding in image_embeddings.items():
sim = cosine_similarity(embedding,
search_embedding).flatten().item()
df_rank = pd.concat([df_rank,pd.DataFrame(data=[[path,sim]],columns=['image_path','sim_score'])])
df_rank.reset_index(inplace=True,drop=True)
df_rank.sort_values(by='sim_score',
ascending=False,
inplace=True,
ignore_index=True)
# display code: 3 column view
col1, col2, col3 = st.columns(3)
df_result = df_rank.head(top_number)
for i in range(top_number):
if i % 3 == 0:
with col1:
st.image(df_result.loc[i,'image_path'],width=picture_width)
elif i % 3 == 1:
with col2:
st.image(df_result.loc[i,'image_path'],width=picture_width)
elif i % 3 == 2:
with col3:
st.image(df_result.loc[i,'image_path'],width=picture_width)
Сценарий приложения загружает вложения изображений, которые были сохранены на предыдущем шаге. Он захватывает введенный пользователем поисковый запрос из панели поиска и использует его для создания встраивания текста. Затем встраивание текста используется для поиска top-n похожих вложенных изображений, которые затем отображаются в приложении. С помощью ползунков можно выбрать как количество результатов поиска, так и ширину изображения.
Демо
Ниже показана демонстрация приложения Streamlit для поискового запроса собакав наборе данных изображений в Интернете.

Рекомендуется запускать streamlit в расширенном режиме, который доступен в правом верхнем меню настроек.
Улучшения
Разработанное приложение использует предварительно обученный CLIP для поиска изображений, соответствующих введенному текстовому запросу. Однако могут быть некоторые специализированные приложения, для которых предварительно обученный CLIP не подходит. Например, поиск определенных марок автомобилей в базе данных многих автомобилей является специализированной задачей. Для такого рода задач нам нужно будет точно настроить CLIP на помеченном наборе данных для конкретного автомобиля. Во втором сообщении блога из этой серии будет показано, как точно настроить CLIP для набора данных, специфичного для предметной области.
Рекомендации
Рэдфорд, Алек, Чон Вук Ким, Крис Халласи, Адитья Рамеш, Габриэль Гох, Сандхини Агарвал, Гириш Шастри и др. «Изучение переносимых визуальных моделей под контролем естественного языка». В Международной конференции по машинному обучению, стр. 8748–8763. ПМЛР, 2021.
Дополнительные материалы на PlainEnglish.io.
Подпишитесь на нашу бесплатную еженедельную рассылку новостей. Подпишитесь на нас в Twitter, LinkedIn, YouTube и Discord .