Итак, прошло около 12 месяцев с тех пор, как я начал самостоятельно изучать машинное обучение. Поэтому я просто хочу сообщить о своем прогрессе.

Имейте в виду, что я начал как полный новичок, потому что я не изучал информатику в университете. К счастью, мои соседи по комнате были в CS, и именно так я наткнулся на Python.
Я действительно не решался добиться успеха в этом деле до июля прошлого года. Примерно в то время мне очень наскучила аналитика, которой я занимался более двух лет, и я захотел заняться наукой о данных, чтобы создавать вещи, которые мне нравились. Машинное обучение всегда было мне интересно, но я никогда не занимался им самостоятельно.
Для моего самого первого проекта я решил построить регрессионную модель для прогнозирования охвата фотографий в Instagram. Но давайте будем реалистами, я сомневаюсь, что это сработает очень хорошо.
Я подумал, что было бы здорово распространить эту идею и на статьи на Medium. К сожалению, мой средний охват настолько ужасен, что даже у моего тостера больше подписчиков!

Итак, я был в поиске проектов по машинному обучению на Github. Оказывается, есть много очень сложных проектов машинного обучения, которые просто доступны на Github, почти без документации, и обычно никто ничего с ними не делает. Я имею в виду, что это все еще очень сложно, но вы можете делать с ним забавные вещи.

Вот почему я стал своего рода подражателем кода, я начал копировать много кода с Github для создания своих проектов. Я думаю, что это было не лучшим образом для моего обучения, но в то же время я научился довольно хорошо читать и модифицировать академический код.
И угадай что?
Оказалось, что кто-то уже обучил модель прогнозировать охват Instagram, поэтому я сделал свой проект более интересным, включив сентиментальный анализ комментариев пользователей.
После того, как я закончил этот проект, я хотел продолжить работу с машинным обучением, поэтому следующим важным делом для меня стало глубокое обучение. Так что я нашел эту штуку под названием Tensorflow и за несколько недель сделал свой первый проект глубокого обучения. С этого момента я был на крючке. Я хотел продолжать работать над проектами глубокого обучения.
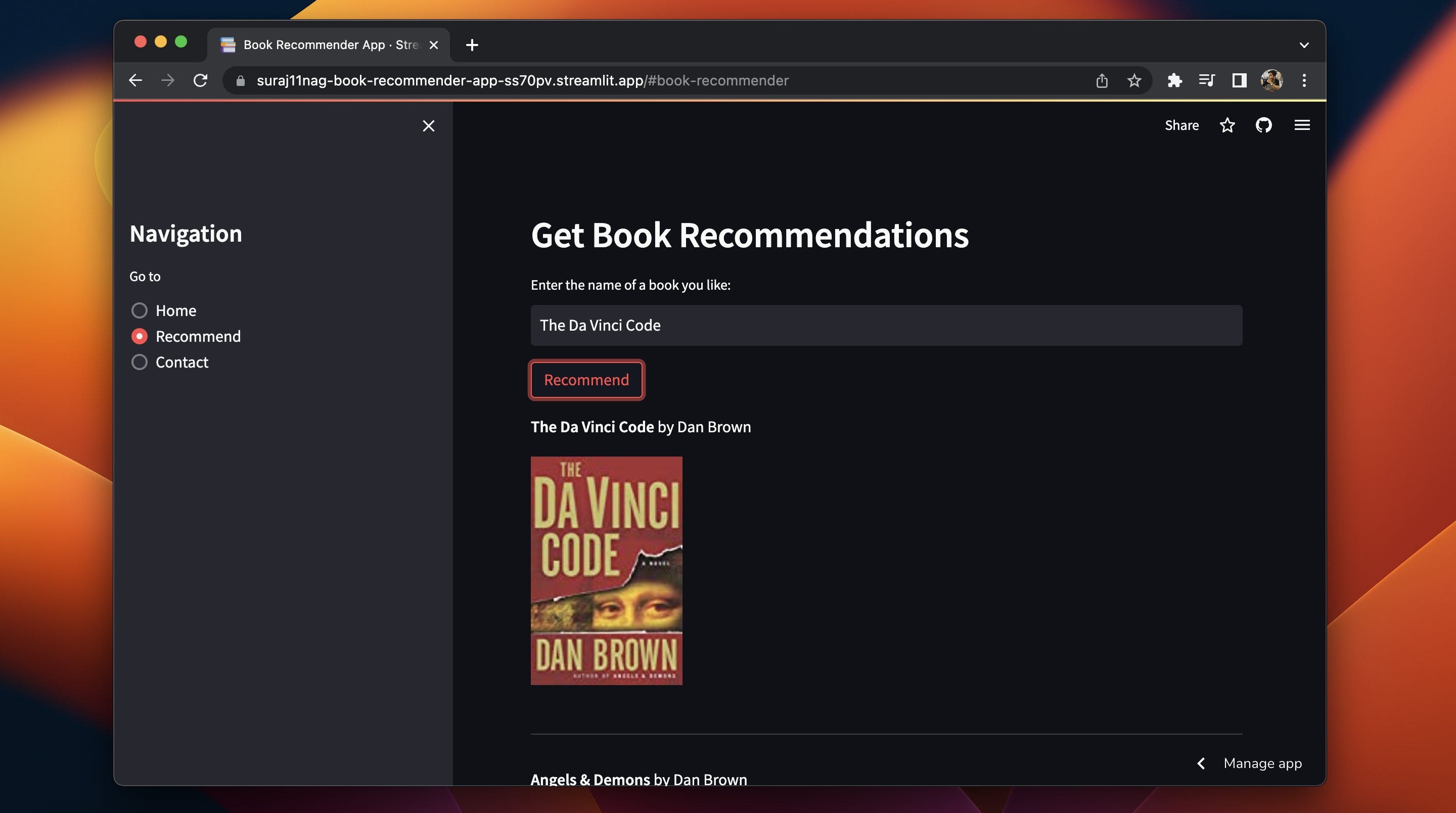
Теперь я наткнулся на эту мистическую вещь под названием Streamlit, и, будучи энтузиастом технологий, я решил создать свое собственное веб-приложение. А что за веб-приложение, спросите вы? Приготовьтесь, потому что это действительно сногсшибательно. Рекомендатель книг!
Я уже слышу коллективные вздохи возбуждения.
Ладно, может быть, нет. Это может показаться не самой крутой вещью в этом районе, но позвольте мне сказать вам, заставить эти системы рекомендаций работать без сбоев и выглядеть потрясающе — это все равно, что пытаться научить единорога танцевать чечетку, но эй, это близко!
Должен признаться, я провел большую часть своего времени в дикой глуши развертывания веб-приложений. Дни превратились в туман проб и ошибок, пока, наконец, я не запустил свое веб-приложение!
Над сколькими проектами я ни работал, меня не покидало ощущение, что моих знаний недостаточно. И ради себя я продолжал учиться, ходить на курсы и создавать проекты. Я был полон решимости быть более продуктивным и использовать свои навыки с пользой. Если бы только наука о данных имела секретный чит-код, такой как «вверх, вверх, вниз, вниз, влево, вправо, влево, вправо, B, A, выучить все»!
Я сосредоточился на том, чтобы снова учиться, а не на том, чтобы когда-нибудь написать еще одну статью для среднего уровня.
Что касается следующего проекта, я знал, что прыгать из одного репозитория Github в другой без толкового понимания деталей реализации было бы плохо для обучения, и я определенно не лягушка.
Поэтому я решил остановиться на одном проекте. И в чем фокус на этот раз? Я хотел узнать, как на самом деле развернуть модель самостоятельно, потому что я понял, что в конечном итоге я буду создавать настоящие продукты машинного обучения, и мне нужно знать, как это сделать.
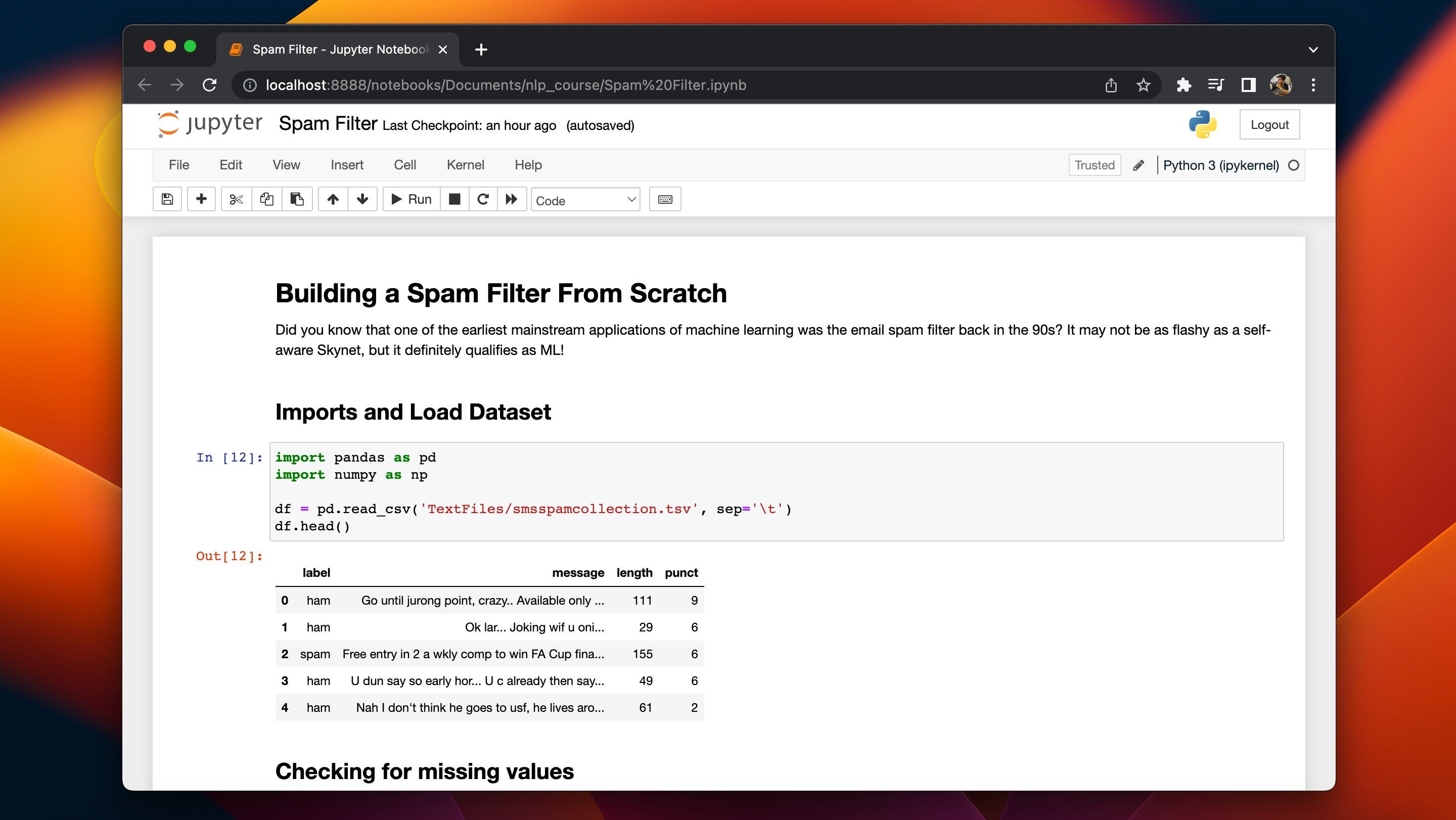
В своих поисках я углубился в область обработки естественного языка и придумал систему фильтрации текста, но это выглядело не так уж круто. Но что я из этого вынес, так это то, что мне нужны новые, интересные и крутые хобби-проекты.
Пока я всем этим занимался, я также прошел дикий мир онлайн-курсов по машинному обучению на Udemy и Coursera, которые все называют лучшими, но у меня сложилось ощущение, что я получил лишь поверхностное понимание концепции.
Но эй, я все еще думаю, что стоило потратить время на их изучение, но обучение на основе проектов просто лучше, потому что в машинном обучении есть так много вещей, которым нужно научиться.
А в машинном обучении даже самые простые концепции довольно сложны, поэтому я предпочитаю очень хорошо разбираться в одной теме, прежде чем переходить к следующей, потому что многие из этих навыков можно передавать другим.
Призыв революции ИИ

Для моего следующего проекта я хочу реализовать что-то с ИИ. Это то, что я давно откладывал, но я чувствую, что революция ИИ уже не за горами и ждет, чтобы все перевернуть с ног на голову. Итак, я подумал о том, на какую область я хотел бы потратить много времени, и было совершенно очевидно, что нужно отвлечься от кода и начать обучать ИИ работе с текстом, файлами, PDF-файлами и видео.
Там может быть много полезных приложений, поэтому я начал его изучать. Я просмотрел множество книг, посмотрел видео на YouTube, а также ознакомился с некоторыми более практичными источниками, такими как сообщения в блогах и исследовательские статьи, и они мне очень понравились.
Я нашел структуру под названием LangChain, которая объединяет LLM, такие как GPT-3, с внешними источниками вычислений и данных. И первое, что я сделал, это заморочился с Vector Store. По сути, я только что создал расширенную индексацию и поиск по сходству векторов в Pinecone, так это было менее навязчиво. А потом я начал возиться с некоторыми более сложными вещами и заставил модель учиться на pdf-файлах, которыми я с ней поделился.

Я кажусь умным, не так ли? Не совсем. Я просто посмотрел много видео на YouTube, и все.
Одна из больших проблем в машинном обучении заключается в том, что трудно сказать, насколько хорошо работает ваша модель. Итак, есть такие штуки, которые называются соревнованиями по машинному обучению, и я принял участие в этом конкурсе Kaggle и Huggingface, который называется конкурсом Kaggle и конкурсом наук, управляемых данными.


Размышляя о своем путешествии по бесчисленным проектам, я должен признать, что получить широкое представление об этой области было так же поучительно, как диско-шар в темной пещере.
К сожалению, мне пришлось отложить работу над реальным проектом, чтобы сосредоточиться на обучении, но я думаю, что это было правильно, потому что я уже создал много проектов, а особенность машинного обучения в том, что очень легко придумывать идеи, которые Звучат хорошо, но заставить их работать действительно сложно.
Я немного лучше разбираюсь в машинном обучении, но многие вещи, которые интересны мне, могут быть не интересны более широкой аудитории. Поэтому я не хочу тратить месяцы на написание статьи об этом, но я все же хочу поделиться ею.
Что я выучил?
Всему можно научиться. Нет ничего недостижимого, пока вы просто садитесь, наберетесь терпения и читаете с самого начала.
Если вам понравилась эта статья, поаплодируйте мне, подпишитесь на меня и поделитесь ею с друзьями. И скоро увидимся в моей следующей статье.