Тайна моделей машинного обучения, которые мы используем ежедневно, заключается в их способности «самокорректироваться». Модель глубокого обучения — это просто математическая функция входного значения. Давайте возьмем пример алгоритма распознавания домашних животных, который берет изображение домашнего животного и выводит, какое животное, по его мнению, является домашним животным!
Сначала изображение разбивается на числа в диапазоне от 0 до 255 (компьютеры рассматривают изображения как каналы RGB в диапазоне от 0 до 255). Вот схема нейронной сети, с которой вы, возможно, знакомы:
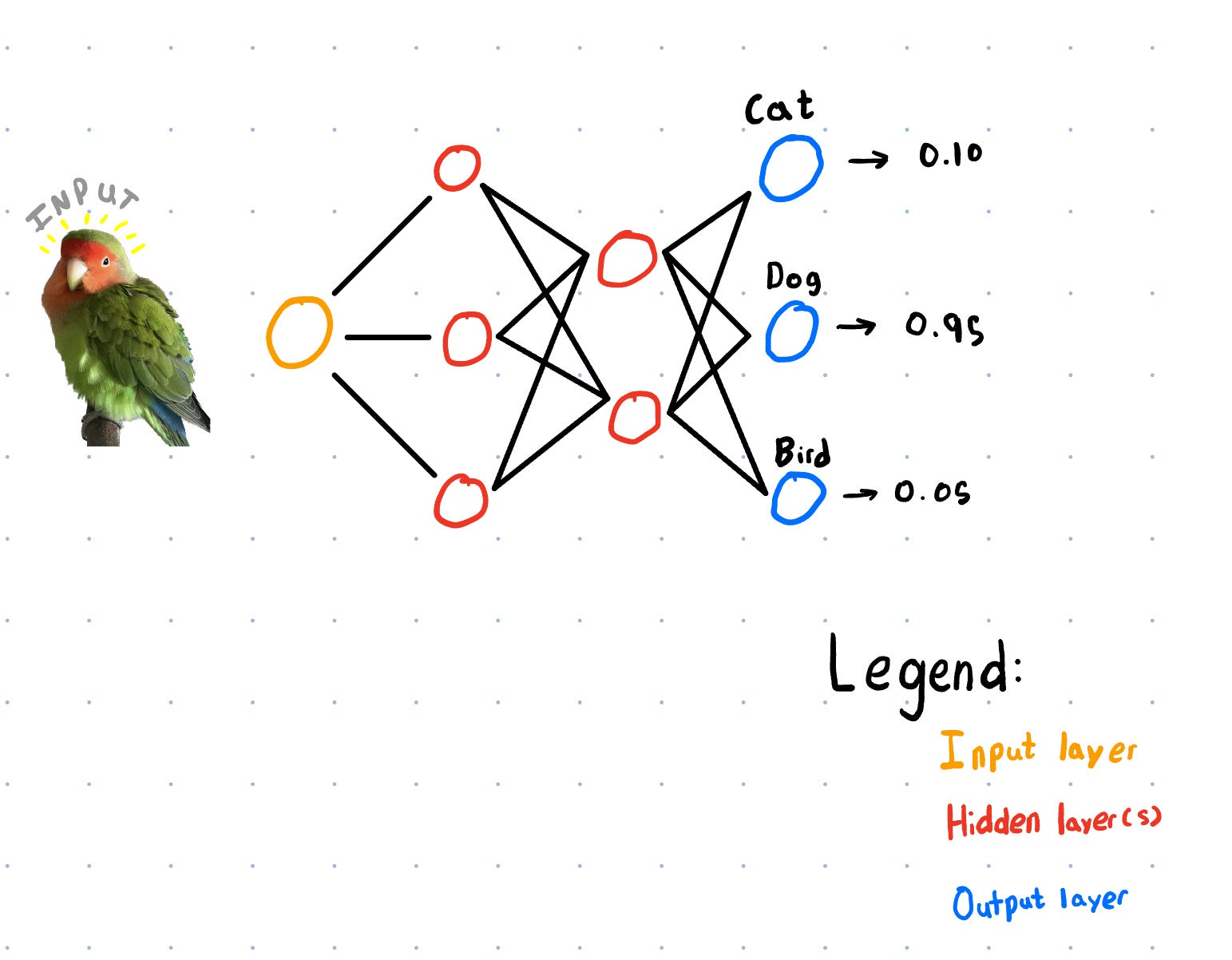
Каждый круг или нейрон — это просто место, где математическая операция выполняется над входными значениями для получения выходных данных, это может быть что-то простое, например: W + X = Y, где W и X — входные данные, а Y — выходные данные. Распространение относится к нейронной сети, вычисляющей выходные данные, когда она проходит через каждый из скрытых слоев к выходному слою. Здесь он выводит прогнозируемое значение для каждого типа животных.
Допустим, наша модель предполагает: Кошка: 0,10, Собака: 0,95, Птица: 0,05. Поскольку мы дали изображение птицы, наша модель ошиблась. Получив изображение птицы, более умная модель угадает Кошка: 0, Собака: 0, Птица: 1. Теперь сеть должна вычислить свою потерю с помощью функции, чтобы понять, насколько далеко она находится. Существует несколько алгоритмов функций потерь, обычно используемых в отрасли, таких как среднеквадратичная ошибка (MSE) или перекрестная энтропийная потеря. Если мы используем первый (MSE) для нахождения потерь, он рассчитает разницу между своим предположением и правильным предположением, возведет его в квадрат и суммирует, чтобы получить потерю выборки данных.
например. (0,10–0)² + (0,95–0)² + (0,05–1)² = потеря этой выборки данных. Сумма потерь всех выборок данных в наборе данных называется потерями в сети. Чем больше потери, тем хуже производительность модели. Специалисты по обработке и анализу данных могут визуализировать взаимосвязь между потерями и их параметрами, рисуя причудливые графики, похожие на картофельные чипсы, подобные этому, где каждая точка представляет потерю сети с изменениями коэффициентов W и X в нейроне (например, изменение операции с W + X = Y в W + 2X = Y):

Самая нижняя точка на этом многомерном графике — это точка, в которой сеть оптимизирована и имеет наименьшие потери в сети! Чтобы уменьшить потери в сети, сеть должна распространяться в обратном направлении и корректировать значения переменных, участвующих в ее расчете.
Обратное распространение является достаточно большой темой, чтобы оправдать отдельную статью, поэтому, подытоживая его функцию, обратное распространение вычисляет градиенты (или производные) функции потерь по отношению к каждому параметру в модели, а затем использует эти градиенты для обновления параметров, уменьшая вычисленные значения. для кошки и собаки, когда вводится изображение птицы. Этот метод также называется градиентным спуском. Делая это на достаточно большом наборе данных, сеть может скорректировать значения своих вычислений настолько, чтобы снизить потери до самой низкой точки на графике картофельных чипсов.
Когда потери уменьшаются, наша сеть становится более точной в предсказании изображений наших питомцев! Разве это не круто? Разбивая объекты на числа и выполняя над ними ряд операций, мы можем создать сеть, способную повысить ценность нашей повседневной жизни.