Градиентный спуск — один из наиболее часто используемых алгоритмов оптимизации в машинном и глубоком обучении. Это метод нахождения минимума функции. Мы начинаем со случайной точки на функции и движемся в отрицательном направлении градиента функции, чтобы достичь минимума.
Понимание градиентов
Прежде чем мы углубимся в градиентный спуск, нам сначала нужно понять, что такое градиент. Проще говоря, градиент — это вектор, указывающий в направлении наибольшей скорости увеличения функции, а его величина — это скорость увеличения в этом направлении.
Рассмотрим простую функцию f(x) = x², ее производную f′(x ) = 2x представляет наклон функции в любой точке x. Отрицательное значение градиента −f′(x) будет указывать в направлении наибольшего спуска.
Вот график функции и ее производной.
import numpy as np
import matplotlib.pyplot as plt
# Function f(x) = x^2
def func(x):
return x ** 2
# Derivative f'(x) = 2x
def derivative(x):
return 2 * x
# Values
x = np.linspace(-10,10,100)
# Create plot
fig, ax = plt.subplots(figsize=(8,6))
ax.plot(x, func(x), label='f(x) = x^2')
ax.plot(x, derivative(x), label="f'(x) = 2x")
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend()
plt.grid(True)
plt.show()
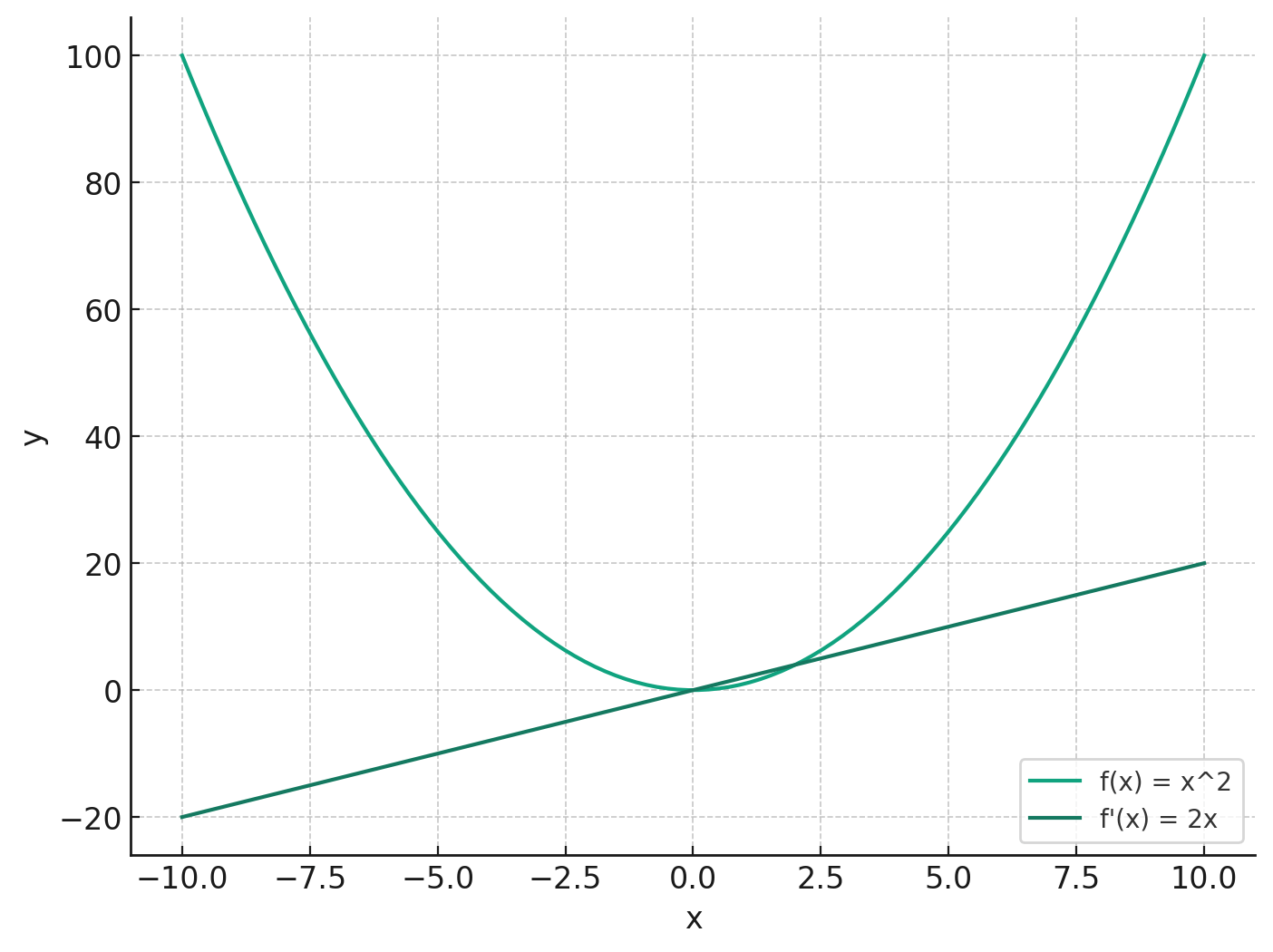
Синяя кривая представляет нашу функцию f(x) = x², а оранжевая кривая представляет производную f′ (x) = 2x. Производная в заданной точке x показывает наклон функции в этой точке. Например, при x= 2 f′(2) = 4, что является наклоном функции f(x) в этот момент.
Алгоритм градиентного спуска
Алгоритм градиентного спуска использует градиент функции, чтобы найти направление наискорейшего спуска. Алгоритм можно свести к следующим шагам:
- Инициализируйте x случайным значением.
- Обновите x, вычитая градиент функции в x, умноженный на скорость обучения: x= x− α∗ f′(x)
- Повторяйте шаг 2, пока изменение x не станет ниже заданного порога или не будет достигнуто максимальное количество итераций.
Скорость обучения, α, — это гиперпараметр, который определяет, насколько большие шаги алгоритм делает на спуске. Если α слишком велико, алгоритм может выйти за пределы минимума, а если α слишком мал, алгоритму может потребоваться слишком много итераций для сходимости.
Давайте реализуем это на Python и визуализируем шаги алгоритма для нашей функции f(x) = x².
# Gradient Descent Algorithm
def gradient_descent(start_x, derivative, learning_rate, epochs):
x = start_x
history = [x]
for _ in range(epochs):
grad = derivative(x)
x -= learning_rate * grad
history.append(x)
return history
# Parameters
start_x = -7.5
learning_rate = 0.1
epochs = 20
# Run Gradient Descent
history = gradient_descent(start_x, derivative, learning_rate, epochs)
# Plot
fig, ax = plt.subplots(figsize=(8,6))
x = np.linspace(-8, 8, 400)
ax.plot(x, func(x), label='f(x) = x^2')
ax.scatter(
history,
[func(i) for i in history],
color='red',
label='Gradient Descent'
)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend()
plt.grid(True)
plt.show()
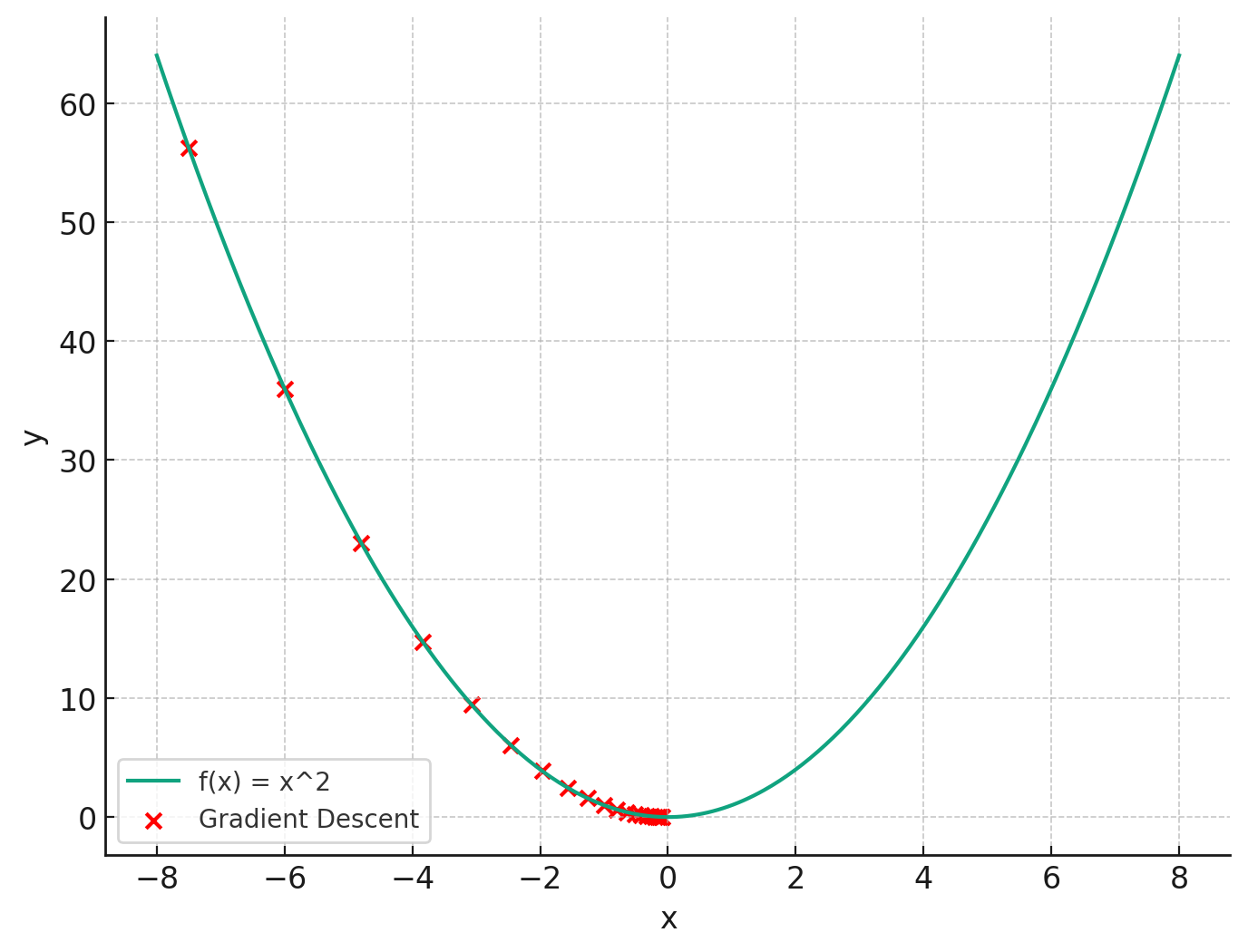
Синяя кривая представляет нашу функцию f(x) = x², а красные точки представляют шаги, предпринятые алгоритмом градиентного спуска, начиная с x = −7,5. Как видите, на каждом шаге алгоритм движется в направлении наискорейшего спуска, приближаясь к минимуму функции.
Скорость обучения
Скорость обучения — это гиперпараметр, который контролирует, насколько мы должны корректировать веса по отношению к градиенту потерь. Более низкие значения скорости обучения означают, что алгоритм будет делать меньшие шаги или обновлять веса, что приведет к более точным результатам и, возможно, к более длительному времени обучения. С другой стороны, более высокие значения означают, что шаги больше, что может привести к более быстрой сходимости, но мы рискуем выйти за рамки оптимального решения.
Давайте визуализируем влияние различных скоростей обучения на сходимость алгоритма градиентного спуска. Мы будем использовать три разные скорости обучения: 0,01, 0,1 и 0,9.
# Different learning rates
learning_rates = [0.01, 0.1, 0.9]
# Run Gradient Descent and plot
fig, ax = plt.subplots(figsize=(8,6))
x = np.linspace(-8, 8, 400)
colors = ['purple', 'green', 'red']
ax.plot(x, func(x), label='f(x) = x^2')
for lr, color in zip(learning_rates, colors):
history = gradient_descent(start_x, derivative, lr, epochs)
ax.scatter(history, [func(i) for i in history], color=color, label=f'Learning rate: {lr}')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend()
plt.grid(True)
plt.show()
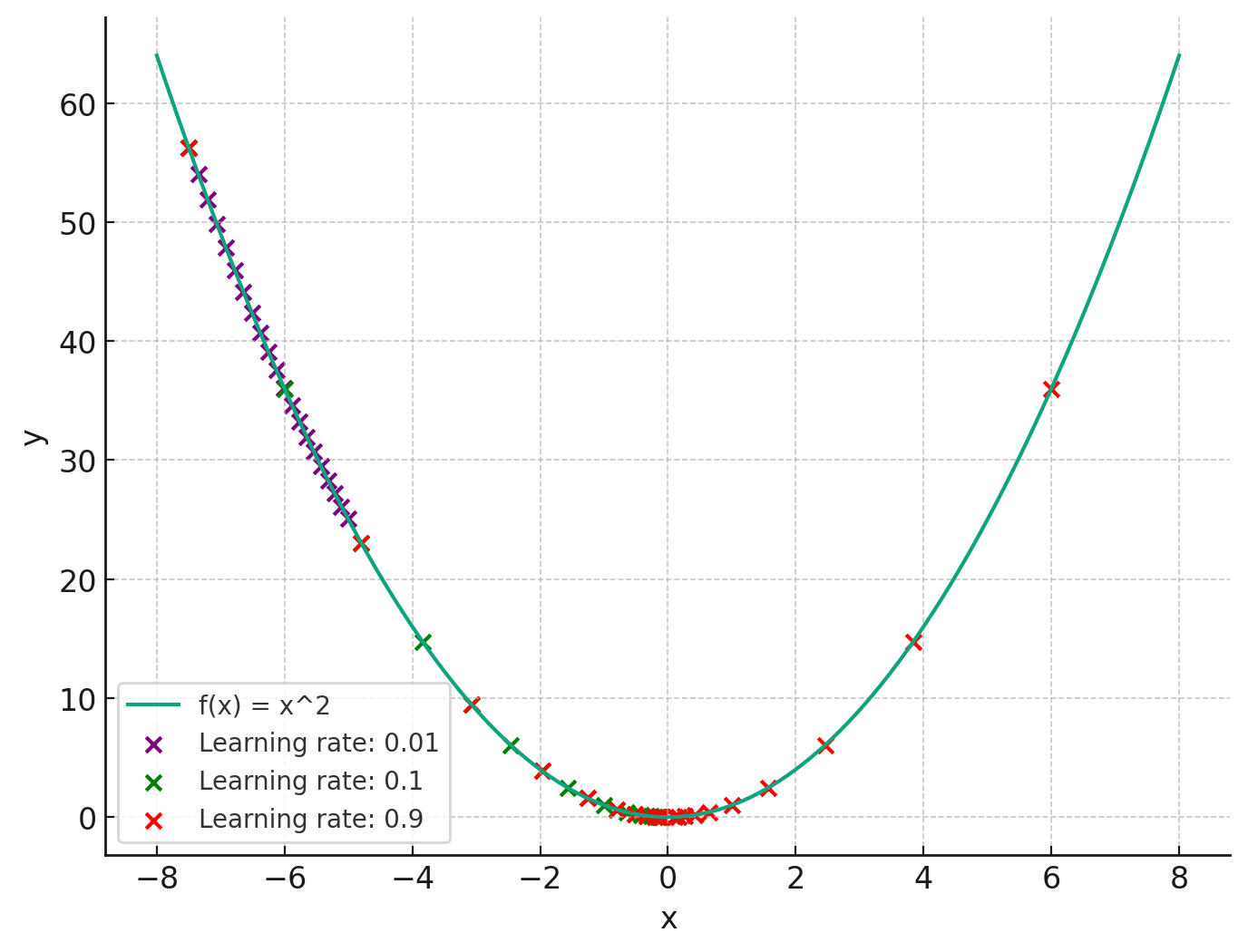
На графике показаны шаги, предпринятые алгоритмом градиентного спуска для разных скоростей обучения. Как мы можем видеть:
- Когда скорость обучения слишком низкая (0,01, фиолетовые крестики), алгоритм делает очень маленькие шаги и требует больше времени (или эпох), чтобы достичь минимума.
- Умеренная скорость обучения (0,1, зеленые крестики) позволяет алгоритму быстро сходиться к минимуму.
- Высокая скорость обучения (0,9, красные точки) может привести к тому, что алгоритм выйдет за пределы минимума и станет нестабильным.
Это демонстрирует важность скорости обучения в алгоритме градиентного спуска. Часто бывает полезно поэкспериментировать с различными скоростями обучения, чтобы найти ту, которая позволяет алгоритму сходиться за разумное время, не выходя за пределы минимума.
Заключение
Градиентный спуск — это мощный алгоритм поиска минимума функции, который широко используется в машинном обучении и глубоком обучении для обучения моделей. Скорость обучения является важным параметром, который контролирует размер шага на каждой итерации алгоритма. Понимание того, как работает градиентный спуск и как установить его параметры, является ключом к обучению эффективных моделей машинного обучения.