
NExT-GPT — это мультимодальная модель большого языка (MM-LLM), разработанная лабораторией NExT++ Национального университета Сингапура и представленная в исследовательской статье под названием «NExT-GPT: Any-to-Any Multimodal LLM». Благодаря замечательному прогрессу больших языковых моделей мы можем предоставить LLM тестовое приглашение, чтобы получить в ответ содержательный ответ.

Однако, как люди, мы привыкли общаться, используя несколько чувств. Таким образом, чтобы иметь более похожий на человека ИИ, может быть полезно иметь возможность использовать больше модальностей в качестве входных данных, таких как аудио, видео и изображения. С NExT-GPT можно использовать эти модальности в качестве входных данных и получать в ответ осмысленный текстовый ответ. Но не только это, NExT-GPT также может давать результаты в различных модальностях, если они лучше соответствуют предоставленным входным данным. Отсюда и бумажное название мультимодальности «любой-к-любому». В этом посте мы углубимся в исследовательскую работу, чтобы понять, как работает эта инновационная система.
Если вы предпочитаете видеоформат, то посмотрите наше видео:
Первоначально этот пост был опубликован здесь — https://aipapersacademy.com/next-gpt/
Платформа NExT-GPT
Давайте начнем с обзора структуры NExT-GPT со следующего изображения из статьи.
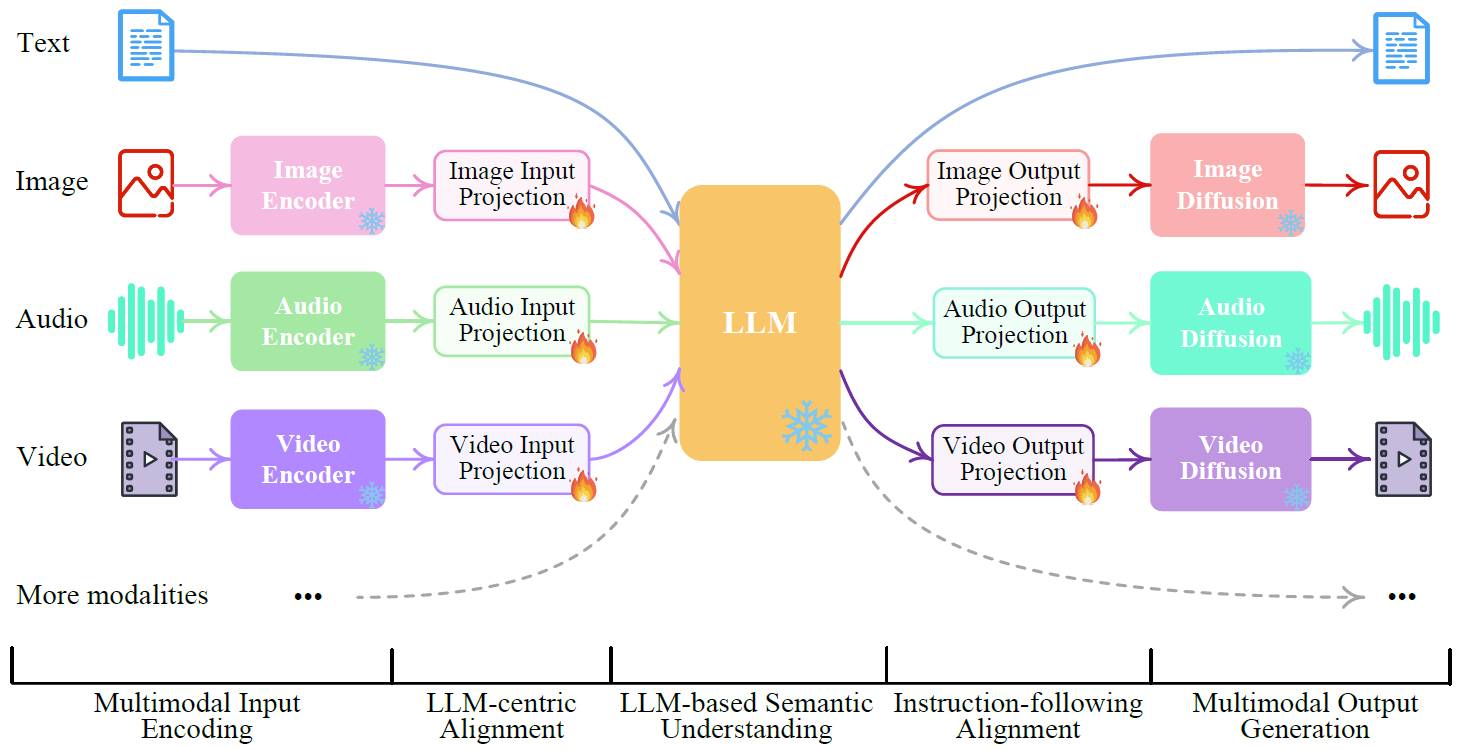
Слева мы видим возможные способы ввода текста, изображения, аудио и видео. В центре у нас есть большая языковая модель, которая является ядром структуры, и мы хотим, чтобы она обрабатывала входные данные всех модальностей и направляла генерацию выходных данных для всех модальностей, но она может только…