Мысли и теория
Почему теория графов круче, чем вы думали
Теория графов в машинном обучении и как она изменила правила игры
Это первая статья из серии из четырех частей, посвященных теории графов и нейронных сетях на основе графов.

Что такое графики?
Поговорите с ученым практически в любой дисциплине и задайте ему вопрос - исходя из его дисциплины - «как работает th на практике?» Скорее всего, вы обнаружите, что существуют системы и сети, которые вам нужно рассмотреть, прежде чем вы сможете по-настоящему понять, как работает любая конкретная вещь: будь то человеческое тело, пищевая цепочка в экосистеме, химическая реакция. , или общество в целом. Не понимая взаимоотношений между двумя животными в экосистеме, двумя атомами в молекуле или клетками и тканями в нашем теле, у вас будет просто набор данных: список клеток, данные о животных и их еде и т. Д.
Традиционные модели машинного обучения часто принимают данные таким образом: они берут списки или таблицы данных и делают некоторые вещи (детали которых зависят от используемого алгоритма, а также от некоторых других параметров), чтобы делать прогнозы. о вещи. Но для некоторых проблем есть способ получше.
Графы - это структуры данных, которые представляют сети или отношения между данными, которые они содержат. Обычно они представлены в виде «узлов» и линий или «ребер».

На рисунке 1 выше показан пример «неориентированного графа» или графа, в котором данные имеют двустороннюю связь с другими данными. Это означает, что каждый узел в нашем графике, каждый из которых представляет человека в социальной сети, связан с каждым другим узлом. Это может быть такой сетевой сайт, как LinkedIn, где, когда вы связываетесь с кем-то, вы связаны друг с другом. Примером ориентированного графа социальной сети может быть Twitter, где пользователи подписываются друг на друга (и не всегда взаимно).
Изображения, которые представляют данные (пользователей), называются узлами или вершинами, а линии, соединяющие их, называются ребрами. Эти линии представляют отношения между вершины, и могут быть представлены как отношения «все или ничего» (например: вы следуете за кем-то или нет) или как «взвешенные» отношения (например: сплошная линия может представлять более высокую степень взаимодействия между двумя пользователями , а пунктирная линия может обозначать более слабые отношения или более низкую вовлеченность).
Возможно, сейчас вы чувствуете то же самое, что я чувствовал, когда впервые познакомился с графами и теорией графов на уроке информатики: мне скучно и, возможно, немного запутано. Хорошая новость в том, что, поскольку мы рассмотрели некоторые термины, необходимые для понимания хороших вещей, мы можем начать разбираться, почему графики важны и что делает их такими крутыми.
И что?
Графики уже используются для некоторых довольно интересных вещей в информатике: ваше приложение Maps, например, использует графики за кадром для хранения данных о местах и улицах, которые их соединяют, и использует алгоритмы кратчайшего расстояния, чтобы найти вам кратчайший маршрут к пункту назначения.
Но становится еще лучше, когда мы начинаем рассматривать использование графиков для машинного обучения. Поскольку графики демонстрируют исчерпывающие взаимосвязи между частями данных (по сравнению с упорядоченными списками данных или тензорами, которые мало что говорят нам о взаимосвязях между точками данных или функциями сами по себе), мы можем использовать их для выполнения углубленного анализа и прогнозы, основанные на этих отношениях.
Теория графов и машинное обучение - но как?
Прежде чем мы сможем воспользоваться преимуществами объединения этих графов или сетей, о которых мы постоянно говорим, с машинным обучением, мы должны каким-то образом представить наш граф таким образом, чтобы компьютер, а затем и алгоритм машинного обучения могли понять.
Графики могут быть представлены традиционно одним из трех основных способов:
- Матрица смежности
Матрицы смежности делают ... как бы то же самое, что звучат так, как будто они делают. Они представляют связи или ребра между различными узлами с помощью матрицы. Мы можем рассмотреть пример, чтобы проиллюстрировать, как это может выглядеть:
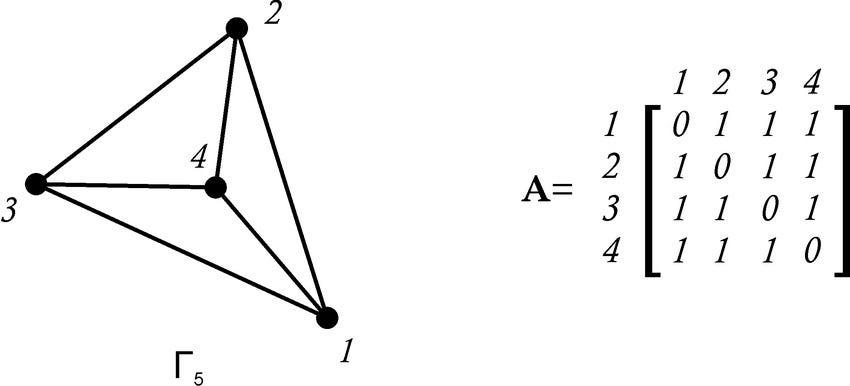
Здесь мы можем найти край между двумя нотами, найдя пересечение их меток в нашей матрице. Мы можем видеть, например, что узел 1 не связан сам с собой, но что он связан с узлом 2.
2. Список краев
Список ребер - это еще один способ представить нашу сеть - или граф - понятным с вычислительной точки зрения способом. Здесь мы представляем пары связанных узлов в списке. Вы можете увидеть пример ниже:

3. Список смежности
Списки смежности объединяют два вышеупомянутых подхода, представляя список узлов, связанных со списком всех узлов, к которым они напрямую подключены. Для иллюстрации рассмотрим пример:

С помощью трех вышеперечисленных подходов мы можем решить сложность вычислительного представления графов в нашем коде. Тем не менее, при загрузке графиков в модели машинного обучения по-прежнему возникают некоторые проблемы. Традиционно модели глубокого обучения хорошо обрабатывают данные, которые занимают фиксированное пространство и являются однонаправленными. Независимо от того, как мы их представляем, графы не занимают фиксированный объем памяти и не являются непрерывными, а, скорее, каждый узел содержит ссылку на узлы, с которыми он напрямую связан.
Есть несколько действительно потрясающих способов решения этих проблем, о которых я подробнее расскажу в следующей статье. А пока я оставлю вам несколько ресурсов для самостоятельного исследования, если вам интересно, которые предоставляют нам новые способы расширения проблем, которые может решить машинное обучение.
- Узнайте о глубоком обучении на графах с помощью сверточных сетей на основе графов
- Узнайте о DeepWalk - проекте, который находит другой способ представления графиков для машинного обучения
Теория графов и машинное обучение - что мы можем с этим сделать?
Ничто не существует в вакууме, и понимание взаимосвязанных сетей данных, из которых состоят многие из наших научных дисциплин, дает захватывающий потенциал для ответа на так много вопросов - больше, чем я могу начать в этой статье.
Что, если бы мы могли лучше понять человеческий мозг? Что, если бы мы могли делать прогнозы о влиянии некоторого стимула или изменения на экосистему? Или предсказать, какое соединение с наибольшей вероятностью создаст эффективное лекарство?
Лучшее из всего, что мы только что узнали - это то, что мы можем - и это не просто теоретическая возможность, а то, чем мы занимаемся прямо сейчас!
Теория графов уже используется для:
- Диагностическое моделирование (предсказание с определенной степенью уверенности, есть ли у пациента конкретный диагноз).
- Помощь в диагностике и лечении онкологических больных.
- Разработка фармацевтических препаратов (лекарств).
4. Стремление к развитию теоретического синтеза между теориями экологии и эволюции.
Как все это происходит в теории графов
Давайте углубимся в эти приложения, чтобы более подробно рассмотреть использование в них теории графов.
Давайте возьмем диагностические модели в качестве примера. В частности, я хочу рассмотреть этот пример сетевого анализа, используемого для диагностики и выявления возможной шизофрении у пациентов:
Используя графики для представления сетевого анализа мозга, нейробиологи могут сопоставить ключевые результаты, связанные с диагностикой шизофрении. Учитывая, что есть определенные маркеры начала шизофрении:
- менее эффективно проводные сети
- менее локальная кластеризация
- менее иерархическая организация
Мы могли бы потенциально оценить эти сети с помощью алгоритма машинного обучения и предсказать вероятность того, что у пациента есть или разовьется шизофрения, на основе этих маркеров.

Без знания этих сетей в этом примере анализ такого рода становится совершенно другим неврологическим анализом пациента. Многообещающие открытия этих открытий для шизофрении имеют многообещающее значение для диагностики и лечения этого расстройства - возможная ранняя диагностика и вмешательство, которое выходит далеко за рамки простой оценки симптомов.
Это всего лишь пример, но он полностью иллюстрирует преимущества теории графов в машинном обучении, поскольку она пересекается с другими дисциплинами.
Дело в том, что наши данные зачастую намного больше, чем мы можем представить в виде списков, фреймов данных или тензоров. Хотя есть способы исследовать наши данные и представлять их таким образом, чтобы мы могли выдвигать гипотезы о взаимосвязях и даже позволять нашим алгоритмам их предсказывать, когда мы можем представлять связи между нашими данными по-другому, мы можем чтобы делать больше с имеющимися у нас данными.
Когда мы понимаем, как вещи соотносятся друг с другом, мы понимаем их лучше: мы можем делать более полные прогнозы и отвечать на более сложные вопросы с некоторыми хорошими результатами, меняющими жизнь.
Хотите узнать больше? Ознакомьтесь с остальной частью серии:
- Сверточные сети с графами - объяснение
- Что заставляет работать сверточные сети с графами?
- Классификация эталонного набора данных PROTEINS
Атрибуция: