Очень важно решить, какие критерии перекрестной проверки и производительности следует использовать при использовании той или иной техники машинного обучения. После обучения нашей модели на наборе данных мы не можем с уверенностью сказать, что модель будет хорошо работать с данными, которых она раньше не видела. Процесс принятия решения о том, приемлемы ли числовые результаты, определяющие предполагаемые взаимосвязи между переменными, в качестве описания данных, известен как валидация. Основываясь на производительности на невидимых данных, мы можем сказать, является ли модель переоборудованной, недостаточно приспособленной или хорошо обобщенной.
Перекрестная проверка
Перекрестная проверка - это метод, который используется для оценки модели машинного обучения путем обучения ее на подмножестве доступных данных, а затем их оценки на оставшихся входных данных. Проще говоря, мы оставляем часть данных в стороне, а затем обучаем модель на оставшихся данных. А затем мы тестируем и оцениваем производительность модели на части данных, которые были отложены.
Типы методов перекрестной проверки
- Метод удержания. Метод удержания - это простой тип перекрестной проверки, при котором набор данных делится на два набора, называемых обучающим набором и набором для тестирования. Модель настраивается и обучается только на обучающей выборке. Затем модели предлагается спрогнозировать выходные значения для данных в наборе тестирования, и она никогда раньше не видела этих данных. Модель оценивается с использованием соответствующего показателя производительности, такого как средняя абсолютная ошибка набора тестов. Преимущество. Он предпочтительнее остаточного метода и требует меньше времени на вычисления. Однако его оценка может иметь большой разброс. Оценка полностью зависит от того, какие точки данных находятся в обучающем наборе и тестовом наборе, и поэтому оценка будет отличаться в зависимости от сделанного разделения.

2. Метод перекрестной проверки K-Fold: это модификация метода удержания. Набор данных разделен на k подмножеств, и значение k не должно быть слишком маленьким или слишком большим. В идеале мы выбираем от 5 до 10 в зависимости от размера данных. Более высокое значение k приводит к менее смещенной модели, тогда как более низкое значение K аналогично подходу удержания. Затем мы обучаем модель, используя k-1 складку, и проверяем и тестируем модель на оставшейся k-й складке. Запишите ошибки. Этот процесс повторяется до тех пор, пока каждая K-кратность не станет тестовым набором. Затем берется среднее значение записанных оценок, которое является показателем производительности модели.

Преимущество - не имеет значения, как разделяются данные. Каждая точка данных попадает в тестовый набор ровно один раз и попадает в обучающий набор k-1 раз. Дисперсия итоговой оценки уменьшается при увеличении k.
Недостаток - алгоритм обучения необходимо повторно запускать с нуля k раз, что означает, что для выполнения оценки требуется в k раз больше вычислений.
3. Перекрестная проверка без исключения - это перекрестная проверка с K-кратным увеличением, доведенная до своего логического предела, где K равно N, количеству точек данных в наборе. Это означает, что N раз, модель обучается на всех данных, кроме одной точки, и для этой точки делается прогноз. Как и раньше, вычисляется средняя ошибка, которая используется для оценки модели. Оценка, полученная с помощью ошибки перекрестной проверки с исключением одного-одного (LOO-XVE), хороша, но при первом проходе ее вычисление кажется очень дорогостоящим.

Показатели эффективности
Точность классификации
Это отношение количества правильных прогнозов к общему количеству входных выборок.
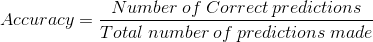
Он работает хорошо, только если есть равное количество образцов, принадлежащих каждому классу. Например, если в нашем обучающем наборе 95% образцов класса A и 5% образцов класса B. Тогда модель может легко получить 95% точности обучения, просто предсказав каждую обучающую выборку, принадлежащую классу A. Когда одна и та же модель тестируется на тестовом наборе с 55% выборок класса A и 45% выборок класса B, тогда точность теста упадет до 55%.
Логарифмическая потеря
Логарифмическая потеря наказывает ложные классификации и хорошо работает для классификации нескольких классов. Классификатор должен присвоить вероятность каждому классу для всех выборок. Если имеется N выборок, принадлежащих к классам M, то потери журнала вычисляются следующим образом:
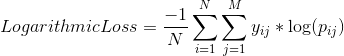
где y_ij указывает, принадлежит ли образец i к классу j или нет, а p_ij указывает вероятность того, что образец i принадлежит классу j
Log Loss не имеет верхней границы и существует в диапазоне [0, ∞). Значение Log Loss, близкое к 0, указывает на более высокую точность, тогда как, если Log Loss отличается от 0, это указывает на более низкую точность.
Матрица путаницы
Матрица путаницы дает нам матрицу в качестве выходных данных и описывает полную производительность модели.
Есть 4 важных термина:
- Истинно положительные результаты: случаи, в которых мы прогнозировали ДА, и фактический результат также был ДА.
- Истинно отрицательные: случаи, в которых мы предсказали НЕТ, а фактический результат был НЕТ.
- Ложные срабатывания: случаи, когда мы предсказали ДА, а фактический результат был НЕТ.
- Ложноотрицательные: случаи, когда мы предсказали НЕТ, а фактический результат был ДА.
Точность матрицы можно рассчитать, взяв среднее значение значений, лежащих на главной диагонали т.е.
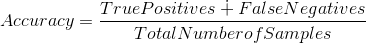
Площадь под кривой
Площадь под кривой (AUC) - один из наиболее широко используемых показателей для оценки. Он используется для задачи двоичной классификации. AUC классификатора равна вероятности того, что классификатор оценит случайно выбранный положительный пример выше, чем случайно выбранный отрицательный пример. Прежде чем давать определение AUC, давайте разберемся с двумя основными терминами:
- Показатель истинных положительных результатов (чувствительность): показатель истинных положительных результатов рассчитывается по TP / (FN + TP). Истинная положительная скорость - это доля положительных точек данных, которые правильно считаются положительными, по отношению ко всем положительным точкам данных. Имеет значения в диапазоне [0, 1].
- Частота ложных положительных результатов (специфичность): частота ложных положительных результатов рассчитывается по FP / ( FP + TN), что означает, что это доля отрицательных точек данных, которые ошибочно считаются положительный по отношению ко всем отрицательным точкам данных. Имеет значения в диапазоне [0, 1].
AUC - это площадь под кривой графика графика ложноположительных результатов и истинных положительных результатов в различных точках в [0, 1].

AUC также имеет диапазон [0, 1], и чем больше значение, тем лучше производительность нашей модели.
Оценка F1
Оценка F1 - это среднее гармоническое (H.M.) между точностью и отзывом. Диапазон составляет [0, 1]. Он показывает, насколько точен классификатор, то есть сколько экземпляров он классифицирует правильно и что он не пропустил значительное количество экземпляров. Чем выше показатель F1, тем лучше характеристики модели.

- Точность: это количество правильных положительных результатов, деленное на количество положительных результатов, предсказанных классификатором.
- Напоминание: это количество правильных положительных результатов, деленное на количество всех образцов, которые должны были быть идентифицированы как положительные.
Средняя абсолютная ошибка
Это среднее значение разницы между исходными и прогнозируемыми значениями. Это не дает нам никакого представления о направлении ошибки, то есть о том, является ли модель недооцененной или переоцененной.
Среднеквадратичная ошибка
Среднеквадратичная ошибка (MSE) очень похожа на среднюю абсолютную ошибку с той разницей, что MSE принимает среднее значение квадрата разницы между исходными значениями и предсказанными значениями.

Преимущество - легче вычислить градиент, тогда как MAE требует сложных инструментов линейного программирования для вычисления градиента.
Благодарим вас за прочтение и ждем ваших отзывов!