
Введение в машинное обучение
Машинное обучение можно рассматривать как распространение человеческого интеллекта на компьютеры. Мы пытаемся заставить компьютеры думать так, как мы. Хотя это утверждение является чрезвычайно амбициозным и расплывчатым, для большинства основных задач, которые компьютер должен выполнять, это правда.
Позвольте мне пояснить свою точку зрения на простом примере.
Представьте, что ваша любимая команда A вышла в финал крупного спортивного соревнования против команды B. Если бы вы сделали ставку на победу команды, какую команду вы бы выбрали?
Если я просто скажу вам, что финал - это матч между A и B, вам будет сложно сделать разумное предположение. Даже если вы болеете за А, вы знаете, что это не повлияет на исход матча. Фактически, ваша поддержка команды - это ваше предубеждение. То есть, если обе команды соответствуют друг другу во всех аспектах игры, тогда вы бы выбрали A, потому что вы поддерживаете A.
На данный момент без какой-либо другой информации, кроме A / s B в финале, вы, естественно, выиграете команду A. Позвольте нам внести больше информации.
Теперь я говорю вам, что общий процент побед команды A составляет 65%, а у команды B - 70%. , все же трудно предсказать победу, так как эти числа близки, и в глубине души вы болеете за победу А. А теперь я говорю вам, что из 10 финалов, в которых была А, А выиграла 5 раз. Кроме того, B выиграла 7 из 11 финалов, в которых участвовала.
Разрешите сложить их в таблицу,

Имея эту информацию, можете ли вы теперь предсказать победителя? Если да, то как вы пришли к этому прогнозу? Ответ непростой. Даже если ваш мозг мгновенно нашел ответ, вы знаете, что это всего лишь предположение. Может быть обоснованное предположение!
Если бы я выбрал команду с этой информацией, я бы выбрал команду B, потому что у них более высокий уровень успеха как в общих, так и в финальных играх.
Итак, давайте предоставим вам дополнительную информацию. Если я скажу вам, что место проведения финала находится на домашнем стадионе A, то показатель успешности A на своем поле безупречный, и они не проиграли ни одной игры в прошлом году. 10 матчей! В то время как команда B имеет умеренный показатель успехов на выезде и выиграла только 7 в последних 10 играх.
Теперь с этой информационной таблицей выглядит так,

Итак, имея эту информацию, за кого бы вы болели в финальном матче? Разумно выбрать А из-за домашнего преимущества и формы. Если вы наблюдаете за всем процессом, с добавлением новой информации ваш прогноз меняется. Что здесь случилось? Почему новая информация меняет ваш прогноз?
Каждый столбец в таблице называется функцией, которая связана с командой. Благодаря этим функциям вы могли делать прогнозы. Один из способов подумать об этом: ваш мозг формулирует функцию, которая учитывает эти особенности и вычисляет оценку / вероятность успеха для команды. Другими словами, он присваивает веса (важность) каждой из этих характеристик и берет взвешенную сумму этих характеристик, чтобы получить оценку для каждой команды. (Хотя это намного сложнее, чем линейная взвешенная сумма, предположим это для простоты).
Функция выглядит так:

где,
X represents the vector or list of our feature. W is the vector of weights associated with corresponding x ϵ X
Для команды A функция f принимает следующий вид:

Для команды B функция f принимает следующий вид:

Функция f, вычисляет балл, который указывает на успех команды. Чем выше оценка, тем выше шансы. Чтобы рассчитать оценку, нам нужно знать веса, используемые в уравнении. Как нам присвоить значения этим весам? Вот где приходит обучение на основе данных. Подсознательно ваш мозг использовал все данные, которые вам известны на основе вашего прошлого опыта, чтобы придумать фактор важности, связанный с каждой из этих функций. Например, по своему опыту вы знаете, что преимущество дома играет большую роль в любой игре. Ему логично присвоить положительный и больший вес. Предположим, вы придумали этот набор весов, W = [0,1, 0,2, 0,2, 0,3, 0,2]. (Мы никогда не узнаем, какие веса придумал ваш мозг, но давайте предположим это ради аргумента)
Согласно этим весам, оценка для команды A составляет 0,83, а для команды B - 0,408. Для лучшего сравнения мы можем нормализовать оценки, разделив их на сумму оценок. Отсюда получаем вероятности,
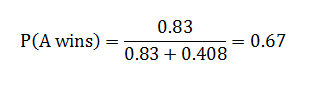
и

Еще один способ их сравнения - это соотношение их оценок,

Таким образом, у A в два раза больше шансов выиграть финальный матч, чем у B. Это называется «шансы». Мы говорим, что у команды A больше шансов на победу, чем у команды B.
Когда вас попросили выбрать команду, вы придумали математическую модель (функция + данные), которая может дать оценку, пропорциональную вероятности победы команды. Чтобы сформулировать эту модель, вы выбрали факторы, связанные с игрой, которые, по вашему мнению, были важны для влияния на победу команды. Это может быть основано на известных вам данных и вашем предыдущем опыте. Как только вы узнаете, какие факторы имеют влияние, вы попытались ранжировать их на основе данных и важности. Для количественной оценки этого ранга вы придумали веса. Вы использовали эти веса в своем уравнении, чтобы предсказать победителя финала. Обратите внимание, что расчет весов не основан на данных в таблице 2. Он получен путем анализа доступных вам данных (предыдущий опыт).
Именно так вы научите свою компьютерную программу учиться на данных и давать ответы на вопросы. Поэтому, когда я сказал, что машинное обучение - это расширение человеческого интеллекта на компьютеры, я имел в виду именно это. Вкратце, машинное обучение изучает математическое уравнение, связанное с данными, с использованием различных алгоритмов, чтобы отвечать на вопросы, ответы на которые можно выразить количественно.
Это начало серии блогов, в которых я попытаюсь упростить концепции машинного обучения и науки о данных. Я очень расплывчатся с терминологией, использованной в статье. Это просто для упрощения. В дальнейшем мы будем исправлять их по мере необходимости. Пожалуйста, дайте мне знать свое мнение.
Викрам Калаби
✉: [email protected]
Linkedin: https://in.linkedin.com / в / викрам-калаби-87504354
Первоначально опубликовано на blog.datalorelabs.com 16 октября 2016 г.