Предположим, у меня есть тип со свойством Достижения, который я хочу установить пустым всякий раз, когда я вижу, что он возвращается методом.
Сделать это с отражением довольно просто:

С Fasterflect это выглядит так:

Мне нравится этот API, он очень интуитивно понятен.
А вот как это выглядит с HyperDescriptor и FastMember:

Теперь давайте проверим это на 1 млн экземпляров MyTypeA и посмотрим, как они это сделают. И Fasterflect, и FastMember работали очень хорошо, хотя HyperDescriptor был в 3 раза медленнее, чем базовое отражение!

Протестируйте 2–1 млн экземпляров MyTypeA и MyTypeB.
Хорошо, но поскольку этот код должен работать со многими типами, мы должны ожидать, что оба
- типы, обладающие этим свойством, и
- типы, которые не
Чтобы смоделировать это, давайте введем в тест еще один тип.

Вместо работы с массивом MyTypeA теперь у нас есть смешанный массив как MyTypeA, так и MyTypeB для нашего теста.

и результат для 1M объектов делает интересные чтения:
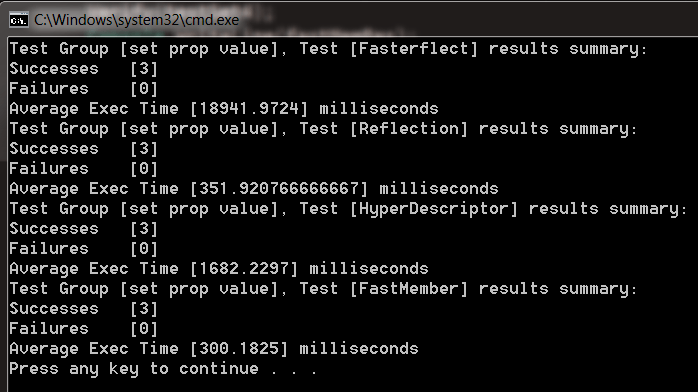
некоторые наблюдения из этого набора результатов:
- нам нужно вызывать сеттер только для половины объектов, поэтому отражение происходит быстрее (почти вдвое), чем раньше, что имеет смысл;
- и FastMember, и HyperDescriptor работают быстрее по той же причине, что и выше;
- меньшее количество работы оказало гораздо меньшее влияние на FastMember предполагает некоторое кэширование вокруг места вызова (и действительно так оно и есть);
- Что за хрень с Fasterflect!
Выводы
Мораль этой истории такова: всегда проверяйте утверждения относительно вашего конкретного варианта использования.
Еще один прекрасный пример тому — работа с Джепсеном Кайла Кингсбери. Где он использует подход генеративного тестирования, чтобы проверить, действительно ли базы данных NoSQL обеспечивают модель согласованности, которую они предлагают. Его выводы очень интересно читать, а во многих случаях симпатично тревожно…
О, и придерживайтесь FastMember или отражения
