Важное примечание: оригинальная статья http://ecdicus.com/linear-model/ с правильным латексным отображением
Линейная модель является наиболее широко используемой моделью в машинном обучении. Это относится к модели, которая использует линейные комбинации выборочных функций для прогнозирования. Для D-мерной выборки $\textbf{x} = [x_1 , ⋯ , x_D] ^T$ ее линейная комбинационная функция имеет вид
$f(\textbf{x};\textbf{w})=w_1x_1+w_2x_2+\hdots+w_Dx_D+b $
$ =\textbf{w}^T\textbf{x}+b$
Где $\textbf{w} = [w_1,…, w_D] ^T$ — вектор D-мерного веса, а b — смещение. Линейная регрессия, представленная в предыдущей главе, представляет собой типичную линейную модель, и $f(\textbf{x};\textbf{w})$ напрямую используется для прогнозирования цели вывода $y=f(\textbf{x}; \textbf{w})$.
В задаче классификации, поскольку выходной целью y являются некоторые дискретные метки, а диапазон значений $f(\textbf{x};\textbf{w})$ является действительным числом, $f(\textbf{x}; \textbf{w})$ нельзя напрямую использовать для прогнозирования, и необходимо ввести нелинейную решающую функцию g(.) для прогнозирования цели вывода.
$ y=g(f(x;w))$
Где f(x;w) также называется дискриминантной функцией.
Для задач бинарной классификации g(.) может быть знаковой функцией, определяемой как
$g(f(x;w))=sign(f(x;w))$
$ \overset{\Delta}{=} \left\{\begin{matrix} +1 & \text{if} \quad f(x;w)›0\\ -1& \text{if} \quad f( x;w)‹0 \end{matrix}\right.$
Когда f(x;w)=0, предсказание не делается. Вышеприведенная формула определяет решающую функцию типичной задачи бинарной классификации, а ее структура показана на рисунке 1.
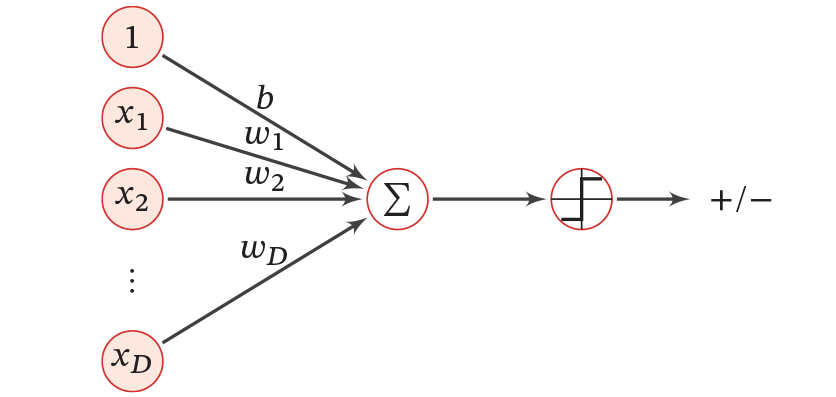
Рисунок 1 Линейная модель для бинарной классификации
В этой главе мы в основном представляем четыре различные модели линейной классификации: логистическая регрессия, регрессия Softmax, персептрон и машина опорных векторов. Разница между этими моделями в основном заключается в использовании разных функций потерь.
Линейная дискриминантная функция и граница решения
Из формулы видно, что модель линейной классификации или линейный классификатор состоит из одной линейной дискриминантной функции $f(x;w)=w^Tx+b$ и нелинейной решающей функции g(.). Сначала мы рассмотрим случай двух классификаций, а затем перейдем к случаю множественных классификаций.
Две категории
Метка категории задачи бинарной классификации y имеет только два значения, обычно она может быть установлена в $\{+1, -1\}$ или $\{0, 1\}$. В задачах бинарной классификации положительные выборки и отрицательные выборки обычно используются для представления выборок, принадлежащих к категориям +1 и -1 соответственно.
В задаче бинарной классификации нам нужна только линейная дискриминантная функция $f(x;w)=w^Tx+b$. Все точки, удовлетворяющие $f(x;w)=0$ в пространстве признаков $\mathbb{R}^D$, образуют гиперплоскость сегментации, которая называется границей решения или поверхностью решения. Граница решения делит пространство признаков на две части. , разделенный на две области, каждая область соответствует категории.
Так называемая модель линейной классификации означает, что ее граница решения представляет собой линейную гиперплоскость. В пространстве признаков плоскость решения ортогональна весовому вектору w. Расстояние со знаком от каждой точки выборки в пространстве признаков до плоскости решения (расстояние со знаком) равно
$ \gamma=\frac{f(x;w)}{\left \| ш \право \|}$
$\gamma$ также можно рассматривать как проекцию точки x в направлении w.
На рисунке 2 показан пример линейной границы решения для задачи бинарной классификации, где вектор признаков выборки $x = [x_1, x_2]$ и вектор весов $w = [w_1, w_2]$.

Рисунок 2 — Пример границы решения для бинарной классификации
Дан обучающий набор из N выборок $\mathcal{D}=\{(x^{(n)},y^{(n)})\}_{n=1}^{N}$, где $ y ^{(n)} \in \{+1,-1\}$, линейная модель пытается узнать параметры $w^*$ так, чтобы для каждой выборки $(x^{(n)},y^{ (n)})$ Попробуйте удовлетворить
$\begin{matrix}
f(x^{(n)};w^*) › 0 & \text{if} \quad y^{(n)}=1 \\
f (x^{(n)};w^*) ‹ 0 & \text{if} \quad y^{(n)}=-1 \\
\end{matrix}$
Приведенные выше две формулы также можно комбинировать, то есть параметры $w^*$ должны максимально удовлетворяться
$y^{(n)}f(x^{(n)};w^*) ›0, \qquad \forall n \in [ 1,N ] $
Чтобы узнать параметр w, нам нужно определить подходящую функцию потерь и метод оптимизации. Для двух задач классификации наиболее прямой функцией потерь является функция потерь 0–1, а именно
$\mathcal{L}_{01}(y,f(x;w))=I(yf(x;w)›0) $
Где I(.) — индикаторная функция. Однако математические свойства функции потерь 0–1 не являются хорошими, а ее производная по w равна 0, что делает невозможным оптимизацию w.
Мультикатегория
Проблема мультиклассовой классификации (Multi-class Classification) означает, что количество категорий классификации C больше 2. Мультиклассификация обычно требует нескольких линейных дискриминантных функций, но существует множество способов проектирования этих дискриминантных функций.
Предполагая, что категория задачи множественной классификации $\{1, 2,…, C\}$, есть три распространенных способа:
- Подход «один к остальным»: преобразование проблемы множественной классификации в задачи с двумя категориями C «один к остальным». Этот метод требует всего C дискриминантных функций, среди которых c-я дискриминантная функция $f_c$ отделяет выборки категории c от выборок, не принадлежащих категории c.
- Метод «один к одному»: преобразуйте проблему множественной классификации в задачи бинарной классификации C(C-1)/2 «один к одному». Этот метод требует всего C(C-1)/2 дискриминантных функций, среди которых (i,j)-я дискриминантная функция разделяет выборки категории i и категории j.
- Метод «Argmax»: это улучшенный метод «один к остальным», требующий в общей сложности дискриминантных функций C.
$f_c(x;w_c)=w_c^Tx+b_c,\qquad c \in \{1,\hdots,C\}$
Для выборки x, если есть категория c, относительно всех других категорий $\widetilde{c}(\widetilde{c}\neq c)$ имеет $f_c(x;w_c) ›f_{\widetilde{c}} (x;w_{\widetilde{c}})$, то x принадлежит категории c. Функция предсказания метода «argmax» определяется как
$ y=\argmaxA^C_{c=1} f_c(x;w_c) $
И у метода «один к другому», и у метода «один к одному» есть недостаток: в пространстве признаков будут некоторые области, категории которых трудно определить, а метод «argmax» решает эта проблема хорошо. На рис. 3 показан пример множественной классификации с использованием этих трех методов. Красная прямая представляет собой прямую линию с дискриминантной функцией f(.) = 0, а области с разными цветами представляют прогнозируемые три категории областей $(w_1, w_2 и w_3 )$ и области, где трудно определить категория ('?'). В методе « argmax » граница решения двух смежных категорий i и j фактически определяется $f_i (x; w_i)-f_j (x; w_j) = 0$, а ее вектор нормали равен $w_i-w_j$ .

Рисунок 3 — Три варианта решения проблемы множественной классификации
Из приведенного выше определения видно, что если набор данных является мультиклассовым линейно разделимым, то должен существовать линейный классификатор типа «argmax», который может правильно их разделить.
Логистическая регрессия
Логистическая регрессия (LR) — это линейная модель, обычно используемая для решения задач бинарной классификации. В этом разделе мы используем $y\in \{0, 1\}$, чтобы соответствовать привычке описания логистической регрессии.
Чтобы решить проблему непригодности непрерывной линейной функции для классификации, введем нелинейную функцию $g:\mathbb{R}^D\rightarrow (0,1)$ для предсказания апостериорной вероятности метки категории $ p(y=1 \mid x)$.
$p(y=1\mid x)=g(f(x;w))$
Среди них g(.) обычно называют функцией активации, и ее функция состоит в том, чтобы «сжать» диапазон значений линейной функции от интервала действительных чисел до (0, 1), что может быть использовано для выражения вероятности. В статистической литературе обратную функцию g(.) $g^{-1}(.)$ также называют функцией связи.
В логистической регрессии мы используем логистическую функцию в качестве функции активации. Апостериорная вероятность метки $y=1$ равна
$p(y=1\mid x)=\sigma(w^Tx) $
$ \overset{\Delta}{=}\frac{1}{1+exp(-w^Tx)}$
Для простоты здесь $x = [x_1,…, x_D, 1]^T$ и $w = [w_1,…, w_D, b]^T$ — это D + 1-мерный вектор расширенных признаков и увеличение, соответственно, Весовой вектор .
Апостериорная вероятность метки $y = 0$ равна
$p(y=0\mid x)=1-p(y=1\mid x) $
$= \frac{exp(-w^Tx)}{1+exp(-w^Tx)}$
После преобразования формулы получаем
$w^Tx=log\frac{p(y=1\mid x)}{1-p(y=1\mid x)} $
$= log\frac{p(y=1 \mid x)}{p(y=0 \mid x)}$
Где $\frac{p(y=1 \mid x)}{p(y=0 \mid x)}$ — выборка, x — отношение апостериорных вероятностей положительных и отрицательных примеров, называемое шансами, и логарифм вероятности называется логарифмом шансов или логитом). Левая часть знака равенства в формуле представляет собой линейную функцию, поэтому логистическую регрессию можно рассматривать как модель линейной регрессии, прогнозируемое значение которой представляет собой «логарифмическую вероятность метки». Поэтому логистическая регрессия также называется логит-регрессией.
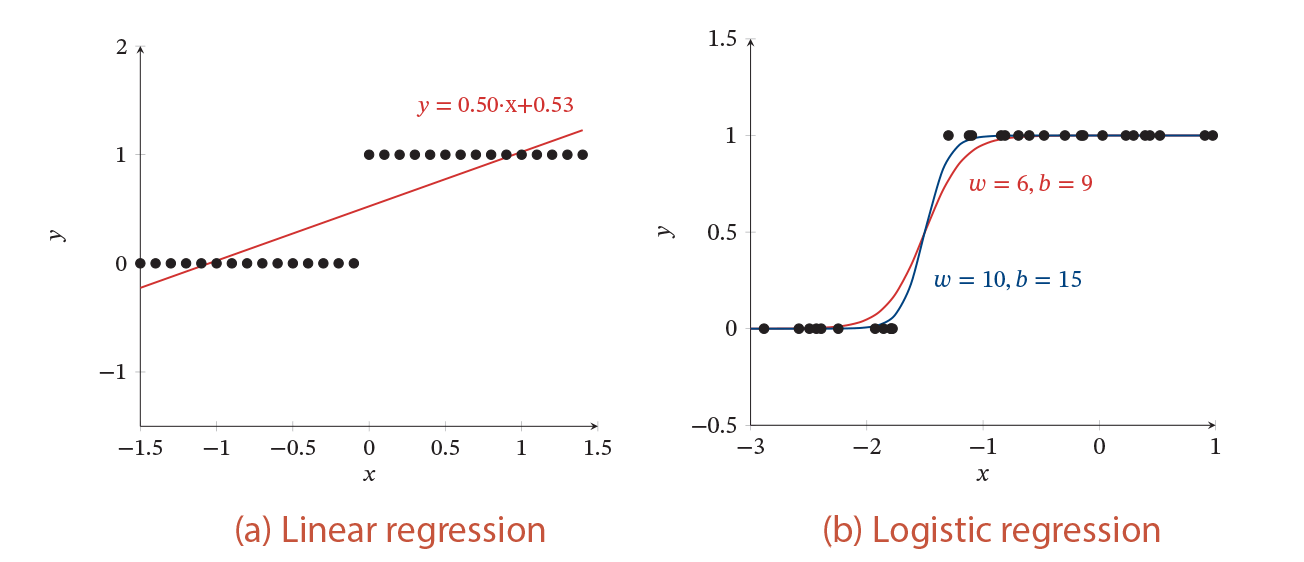
Рисунок 4 — Пример задачи бинарной классификации с одномерными данными
На рис. 4 показан пример использования линейной регрессии и логистической регрессии для решения задачи бинарной классификации одномерных данных.
Изучение параметров
Логистическая регрессия использует перекрестную энтропию в качестве функции потерь и использует градиентный спуск для оптимизации параметров.
Учитывая N обучающих выборок $\{(x^{(n)},y^{(n)})\}_{n=1}^{N}$, используйте модель логистической регрессии для анализа каждой выборки $x ^ {(n)}$ делают прогнозы и выводят апостериорную вероятность с меткой 1, обозначаемую как $\hat{y}^{(n)}$,
$\hat{y}^{(n)}=\sigma(w^Tx^{(n)}), \qquad 1\leq n\leq N$
Поскольку $y^{(n)} \in \{0, 1\}$, истинная условная вероятность выборки $(x^{(n)}, y^{(n)})$ может быть выражена как
$p_r(y^{(n)}=1 \mid x^{(n)})=y^{(n)}$
$ p_r(y^{(n)}=0 \mid x^{(n)})=1-y^{(n)}$
Используя функцию кросс-энтропийных потерь, функция риска имеет вид
$\mathcal{R}(w)=-\frac{1}{N}\sum_{n=1}^{N}(p_r(y^{(n)}=1\mid x^{(n) } )log\hat{y}^{(n)}+p_r(y^{(n)}=0\mid x^{(n)} )log(1-\hat{y}^{(n) }))$
$= -\frac{1}{N}\sum_{n=1}^{N}(y^{(n)}log\hat{y}^{(n)}+(1-y^{( n)})log(1-\hat{y}^{(n)}))$
Частная производная функции риска $\mathcal(R)(w)$ по параметру w равна
$ \ frac {\ partial \ mathcal {R} (w)} {\ partial w} = - \ frac {1} {N} \ sum_ {n = 1} ^ {N} (y ^ {(n)} \ frac{\шляпа{у}^{(п)}(1-\шляпа{у}^{(п)})}{\шляпа{у}^{(п)}}х^{(п)} - (1-y^{(n)})\frac{\шляпа{y}^{(n)}(1-\шляпа{y}^{(n)})}{(1-\шляпа{y} ^{(п)})}х^{(п)})$
$= y^{(n)}(1-\шляпа{y}^{(n)}) x^{(n)}-(1-y^{(n)})\шляпа{y}^{ (п)}х^{(п)}$
$=-\frac{1}{N}\sum_{n=1}^{N}x^{(n)}(y^{(n)}-\hat{y}^{(n)}) $
Используя метод градиентного спуска, процесс обучения логистической регрессии заключается в следующем: инициализируйте $w_0\leftarrow 0$, а затем итеративно обновите параметры по следующей формуле:
$ w_{t+1}\leftarrow w_{t}+\alpha \frac{1}{N}\sum_{n=1}^{N} x^{(n)}(y^{(n)} -\шляпа{y}_{w_t}^{(n)}) $
Среди них $\alpha$ — это скорость обучения, а $\hat{y}_{w_t}^{(n)}$ — это результат модели логистической регрессии, когда параметр равен $w_t$.
Из формулы видно, что функция опасности $\mathcal{R}(w)$ является непрерывной и выводимой выпуклой функцией по параметру w. Следовательно, в дополнение к методу градиентного спуска логистическая регрессия также может быть оптимизирована с помощью методов оптимизации высокого порядка (таких как метод Ньютона).
Регрессия Softmax
Регрессия Softmax, также известная как полиномиальная или многоклассовая логистическая регрессия, представляет собой обобщение логистической регрессии для задач с несколькими классами.
Для нескольких типов задач метка категории $y \in \{1, 2,…, C \}$ может иметь значения C. Для выборки x условная вероятность принадлежности к категории c, предсказанная регрессией Softmax, равна
$p(y=c\mid x)=softmax(w_c^Tx)$
$= \frac{exp(w_{c}^Tx)}{\sum_{{c}’=1}^{C}exp(w_{{c}’}^Tx)}$
Среди них $w_c$ — весовой вектор c-й категории.
Решающая функция регрессии Softmax может быть выражена как
$\hat{y}=\argmaxA_{c=1}^{C} p(y=c \mid x) $
$= \argmaxA_{c=1} w_c^Tx$
Связь с логистической регрессией Когда количество категорий C = 2, решающая функция регрессии Softmax
$\hat{y} =\argmaxA_{y \in \{0,1 \}} w^T_y x$
$=I(w_1^T x-w_0^T x >0)$
$=I((w_1 -w_0)^T x >0)$
Среди них I(.) — индикаторная функция. Сравнивая двухкатегориальную решающую функцию в формуле , мы можем найти весовой вектор в двухкатегории $w = w_1 − w_0$.
Представление вектора в векторной форме можно записать как
$\шляпа{у}=softmax(W^Tx) $
$= \frac{exp(W^Tx)}{1_C^Texp(W^Tx)}$
Где $W = [w_1,…, w_C]$ — матрица, составленная из C классов весовых векторов, $1_C$ — C-мерный вектор, состоящий из единиц, $\hat{y} \in \mathbb{R}^ C$ — это вектор, составленный из прогнозируемых условных вероятностей всех категорий, а значение размерности c — это прогнозируемая условная вероятность c-й категории.
Изучение параметров
Учитывая N обучающих выборок $\{ (x^{(n)},y^{(n)})\}_{n=1}^{N}$, регрессия Softmax использует функцию кросс-энтропийных потерь для изучения наиболее Оптимальная матрица параметров W.
Для удобства мы используем C-мерный однонаправленный вектор $y \in \{0, 1\}^C$ для представления метки категории. Для категории c его вектор выражается как
$y=[I(1=C),I(2=c),\hdots,I(C=c)]^T$
Среди них I(.) — индикаторная функция.
Используя функцию кросс-энтропийных потерь, функция риска регрессионной модели Softmax имеет вид
$\mathcal{R}(w)=-\frac{1}{N}\sum_{n=1}^{N}\sum_{c=1}^{C}y_c^{(n)} log\ шляпа{y}_c^{(n)}$
$ =-\frac{1}{N}\sum_{n=1}^{N} (y_c^{(n)})^T log\hat{y}_c^{(n)}$
Среди них $\hat{y}^{(n)} = softmax(W^Tx^{(n)}$ — апостериорная вероятность выборки $x^{(n)}$ в каждой категории.
Градиент функции риска $\mathcal(R)(w)$ относительно W равен
$ \ frac {\ partial \ mathcal (R) (w)} {\ partial w} = - \ frac {1} {N} \ sum_ {n = 1} ^ {N} x ^ {(n)} (y ^{(n)} -\шляпа{y}^{(n)})^T $
Доказательство. Ключом к вычислению градиента в формуле является вычисление функции потерь для каждой выборки $\mathcal{L}^{(n)}(W)=-(y^{(n )})^Tlog\hat {y}^{(n)}$ Что касается градиента параметра W, необходимо использовать две формулы производных:
- Если y = softmax(z), то $\frac{\partial y}{\partial z}=diag(y)-yy^T$
- Если $z = W^Tx = [W_1^T x, W_2^T x,…, W_C^T x]^T$, то $\frac{\partial z}{\partial w_c}$ является столбцом c как x а остальные 0 матрицы.
$\frac{\partial z}{\partial w_c} &= [\frac{\partial w_1^T x }{\partial w_c},\frac{\partial w_2^T x}}{\partial w_c},\hdots , \ гидроразрыва {\ парциальное w_C ^ T х {\ парциальное w_c}] $
$ = [0,0,\hdots,x,\hdots,0]$
$ \overset{\Delta}{=} \mathbb{M}_c(x)$
По цепному правилу $\mathcal{L}^{(n)}(W)=-(y^{(n)})^T log\hat{y}^{(n)}$ О $w_c $ Частная производная
$ \ frac {\ partial \ mathcal {L} ^ {(n)} (W)} {\ partial w_c} = \ frac {\ partial ((y ^ {(n)}) ^ T log \ hat {y} ^{(n)})}{\partial w_c} $
$ = - \ frac {\ partial z ^ {(n)}} {\ partial w_c} \ frac {\ partial \ hat {y} ^ {(n)}} {\ partial z ^ {(n)}} \ гидроразрыв {\ парциальный журнал \ шляпа {у} ^ {(п)}} {\ парциальный \ шляпа {у} ^ {(п)}} у ^ {(п)} $
$=-\mathbb{M}_c(x^{(n)})(diag(\hat{y}^{(n)})-\hat{y}^{(n)}(\hat{y }^{(n)})^T)(dig(\hat{y}^{(n)}))^{-1} y^{(n)}$
$=-\mathbb{M}_c(x^{(n)})(1-\hat{y}^{(n)}1_C^T)y^{(n)}$
$= -\mathbb{M}_c(y^{(n)}-\hat{y}^{(n)})$
$= -x^{(n)} [ y^{(n)}-\шляпа{y}^{(n)} ]_c$
Формула также может быть выражена в не векторной форме, а именно
$ \ frac {\ partial \ mathcal {L} ^ {(n)} (W)} {\ partial w_c} = -x ^ {(n)} (I (y ^ {(n)} = c) - \ шляпа {y} ^ {(n)}_c) $
Среди них I(.) — индикаторная функция.
По формуле можем получить
$ \ frac {\ partial \ mathcal {L} ^ {(n)} (W)} {\ partial w_c} = -x ^ {(n)} (y ^ {(n)} - \ hat {y} ^ {(п)})^Т $
Используя метод градиентного спуска, процесс обучения регрессии Softmax: инициализируйте $W_0\leftarrow 0$, а затем итеративно обновите по следующей формуле:
$ W_{t+1}\leftarrow W_t +\alpha (\frac{1}{N}\sum_{n=1}^{N} x^{(n)}(y^{(n)} -\ шляпа{у}^{(n)})^T )$
Где $\alpha$ — скорость обучения, а $\hat{y}_{(n)}^{W_t}$ — результат регрессионной модели Softmax, когда параметр равен $W_t$.
Персептрон
Персептрон был предложен Фрэнком Розеблаттом в 1957 году. Это широко используемый линейный классификатор. Персептрон — простейшая искусственная нейронная сеть, состоящая всего из одного нейрона.
Персептроны — это простые математические модели биологических нейронов. У них есть компоненты, соответствующие биологическим нейронам, такие как веса (синапсы), смещения (пороги) и функции активации (тела клеток). Выход +1 или -1.
Персептрон представляет собой простую двухклассовую модель линейной классификации, и его критерий классификации такой же, как в формуле , а именно
$ \ шляпа {y} = знак (w ^ Tx) $
Изучение параметров
Алгоритм обучения персептрона также является классическим алгоритмом обучения параметров линейного классификатора.
Дан обучающий набор из N выборок: $\{ (x^{n},y^{n})\}_{n=1}^{N}$, где $y^{(n)} \in \ { +1,-1\}$, алгоритм обучения персептрона пытается найти набор параметров $w^*$, так что для каждой выборки $(x^{(n)},y^{(n)}) $ есть
$y^{(n)}w^{*T}x^{(n)} › 0 ,\qquad \forall n \in \{1,\hdots,N\}$
Алгоритм обучения персептрона представляет собой управляемый ошибками алгоритм онлайн-обучения [Rosenblatt, 1958]. Сначала инициализируйте вектор весов $w\leftarrow 0$ (обычно вектор со всеми нулями), а затем используйте этот образец для обновления веса каждый раз, когда образец (x, y) неверен, то есть $yw^Tx ‹0 $.
$w \leftarrow w +yx$
Конкретная стратегия изучения параметров персептрона показана в алгоритме 1.

Согласно стратегии обучения персептрона, функция потерь персептрона может быть выведена как
$\mathcal{L}(w;x,y)=max(0,-yw^Tx)$
Используя стохастический градиентный спуск, градиент каждого обновления равен
$\frac{\partial \mathcal{L}(w;x,y)}{\partial w}=\left\{\begin{matrix}
0 & \text{if} \qquad yw^Tx ›0\\
-yx & \text{if} \qquad yw^Tx ‹0
\end{matrix}\right.$
На рис. 5 показан процесс обновления обучения параметрам персептрона, в котором красная сплошная точка является положительным примером, а синяя полая точка — отрицательным примером. Черная стрелка указывает текущий вектор веса, а красная пунктирная стрелка указывает направление обновления веса.

Рис. 5. Процесс обновления для изучения параметров персептрона
Сходимость персептрона
[Novikoff, 1963] доказал, что для двух типов задач, если обучающая выборка линейно разделима, алгоритм персептрона может сходиться после конечного числа итераций. Однако если обучающая выборка не является линейно разделимой, то этот алгоритм не может гарантировать сходимость.
Когда набор данных имеет два типа линейно разделимых, для обучающего набора $\mathcal{D}=\{(x^{(n)},y^{(n)})\}_{n=1}^ { N}$, где $x^{(n)}$ — расширенный вектор признаков выборки, $y^{(n)} \in {-1, 1}$, то существует положительная константа $y (y › 0)$ и весовой вектор $w^*$, а также $\left \| w^* \right \|=1$, для всех n выполняется $(w^*)(x^{(n)}y ^{(n)})\geq y$. Мы можем доказать следующую теорему.
Сходимость персептрона: учитывая обучающий набор $\mathcal{D}=\{(x^{(n)},y^{(n)})\}_{n=1}^{N}$, пусть R модуль наибольшего вектора признаков в обучающем наборе, а именно
$ R=\max_n \| х^{(п)} \| $
Если обучающая выборка $\mathcal{D}$ линейно разделима, время обновления веса алгоритма обучения параметра 1 двух типов персептронов не превышает $\frac{R²}{y²}$.
Доказательство. Метод обновления весового вектора персептрона таков:
$ w_k=w_{k-1}+y^{(k)}x^{(k)}$
Среди них $x^{(k)},y^{(k)}$ представляет k-ю неправильно классифицированную выборку.
Поскольку начальный вектор весов равен 0, вектор весов персептрона при K-м обновлении равен
$w_k=\sum_{k=1}^{K}y^{(k)}x^{(k)}$
Вычислите верхнюю и нижнюю границы $\left \| w_k \right \|²$ соответственно:
- Верхняя граница $\left \| w_k \right \|²$
$\lлевый \| w_k \справа \|² =\слева \| w_{K-1} +y^{(K)}x^{(K)}\right \|²$
$ =\слева \| w_{K-1} \право \|²+\лево \| y^{(K)} x^{(K)}\right \|²+2y^{(K)} w^T_{K-1}x^{(K)}$
$\leq\влево\| w_{K-1} \право \|² +R²$
$\leq\влево\| w_{K-2} \right \|² +2R²$
$KR²$
- Нижняя граница $\left \| w_k \right \|²$ исс
$\слева \| w_K \право \|² &=\лево \| ш^* \право \|².\лево \| w_K \право \|²$
$\geq\влево\| w^{*T}w_K \right \|²$
$=\geq\влево \| w^{*T} \sum_{k=1}^{K} (y^{(k)} x^{(k)})\right \|²$
$= \left \|\sum_{k=1}^{K} w^{*T} (y^{(k)} x^{(k)})\right \|²$
$\geq K² y²$
Из двух формул получаем
$ K²y²\leq \влево \| w_K \справа \|² \leq KR²$
Берем два крайних левых и крайних правых предмета и далее получаем $K²y² \leq KR²$. Затем разделите K на обе части и в итоге получите $K \leq \frac{R²}{y²}$. Следовательно, при условии линейной разделимости алгоритм 1 будет сходиться за $\frac{R²}{y²}$ шагов.
Хотя персептрон может гарантировать сходимость по линейно разделимым данным, он имеет следующие недостатки:
- Когда набор данных является линейно разделимым, хотя персептрон может найти гиперплоскость для разделения двух типов данных, он не может гарантировать свою способность к обобщению.
- Персептрон более чувствителен к порядку выборок. Когда порядок каждой итерации непостоянен, найденные гиперплоскости сегментации часто непоследовательны.
- Если обучающая выборка не является линейно разделимой, она никогда не сойдется.
Параметр среднего восприятия,
Согласно теореме 3.1, если обучающие данные линейно разделимы, то персептрон может найти дискриминантную функцию для разделения разных типов данных. Чем больше интервал y, тем быстрее сходимость. Однако персептрон не может гарантировать, что найденная дискриминантная функция оптимальна (например, высокая способность к обобщению), что может привести к переобучению.
Весовой вектор, полученный персептроном, связан с порядком обучающих выборок. Выборки ошибок, ранжированные позже в порядке итерации, оказывают большее влияние на окончательный вектор весов, чем предыдущие выборки ошибок. Например, с 1000 обучающими выборками после повторения 100 выборок персептрон выучил хороший весовой вектор. Прогноз верен для следующих 899 выборок, и вектор весов не обновляется. Однако на последней тысячной выборке прогноз оказался неверным, и веса были обновлены. Это обновление может ухудшить вектор весов.
Чтобы повысить надежность и способность персептрона к обобщению, мы можем сохранить все K весовых векторов в процессе обучения персептрона и присвоить каждому весовому вектору доверительный коэффициент $c_k(1 \leq k \leq K )$. Окончательный результат классификации определяется голосованием этих K персептронов с разными весами. Эта модель также называется Voted Perceptron [Freund et al., 1999].
Пусть $\tau_k$ — количество итераций при обновлении веса $w_k$ в k-й раз (то есть количество обученных выборок), $\tau_{k+1} $ — количество итераций при обновлении веса обновляется в следующий раз, то вес $w_k. Доверительный коэффициент $c_k$ для $ устанавливается равным количеству итераций от $\tau_k$ до $\tau_{k+1} $, то есть $c_k = \tau_{ k+1}- \tau_k$. Чем больше коэффициент достоверности $c_k$, тем более достоверен вес $w_k$ в последующем процессе обучения.
Таким образом, форма персептрона голосования
$\hat{y}=sign(\sum_{k=1}^{K}c_k sign(w_k^T x)) $
Среди них sign(.) является символьной функцией.
Хотя персептрон с правом голоса улучшает способность персептрона к обобщению, он должен сохранять K весовых векторов. В реальной эксплуатации это приведет к дополнительным накладным расходам. Поэтому люди часто используют упрощенную версию, чтобы уменьшить количество параметров голосующего персептрона, используя стратегию «усреднения параметров», также называемую усредненным персептроном [Collins, 2002]. Форма среднего персептрона
$\шляпа{у} = sgn(\frac{1}{T}\sum_{k=1}^{K}c_k(w_k^Tx))$
$=sign(\frac{1}{T}\sum_{k=1}^{K}(c_kw_k)^Tx)$
$=sign((\frac{1}{T}\sum_{t=1}^{T}w_t)^T x)$
$=знак(\widetilde{w}x)$
Где T — общее количество итераций, а $\widetilde{w}$ — вектор среднего веса T итераций. Этот метод очень прост. Нужно только добавить $\widetilde{w}$ в алгоритме 1 и обновить $\widetilde{w}$ на каждой итерации:
$\widetilde{w}\leftarrow \widetilde{w}+w_t$
Но этот метод должен обновлять $\widetilde{w}$ при обработке каждого образца. Поскольку и $\widetilde{w}$, и $w_{t,n}$ являются плотными векторами, операция обновления занимает много времени. Чтобы увеличить скорость итерации, существует множество улучшенных методов, так что это обновление нужно обновлять только тогда, когда происходит неправильный прогноз.
Алгоритм 2 представляет процесс обучения улучшенного алгоритма среднего персептрона [Daumé III, 2012].

Расширение до нескольких категорий
Исходный персептрон представляет собой модель с двумя классификациями, но ее также можно легко распространить на задачи с несколькими классификациями или даже на более общие задачи структурированного обучения [Collins, 2002].
В представленной ранее модели классификации все функции классификации находятся в пространстве признаков входных данных x. Чтобы датчик мог обрабатывать более сложные выходные данные, мы вводим функцию признаков $\phi(x,y))$, построенную на совместном пространстве ввода-вывода, и сопоставляем пару выборок (x, y) с вектором признаков космос.
В пространстве совместных признаков мы можем построить обобщенную модель персептрона,
$\hat{y}=\argmaxA_{ y \in Gen(x)}w^T \phi(x,y)$
Среди них w — вектор весов, а Gen(x) — набор всех выходных целей ввода x.
Обобщенная модель персептрона обычно используется для решения задач структурированного обучения. Когда обобщенная модель персептрона используется для решения проблемы классификации C, $y \in \{0, 1\}^C$ является однократным векторным представлением категории. В задаче классификации C часто используемая характеристическая функция $\phi(x, y)$ представляет собой внешнее произведение x и y, а именно
$\phi(x,y)=vec(xy^T) \in\mathbb{R}^{(D \times C)}$
Где vec(.) — векторизованный оператор, а $\phi(x,y)$ — вектор размерности $(D \times C)$.
Для заданной выборки (x, y), если $x \in \mathbb{R}^D$, y — однократный вектор размерности 1, то
$\phi(x,y)=\begin{bmatrix}
\vdots\\
0\\
x_1\\
\vdots\\
x_D\ \
0\\
\vdots
\end{bmatrix}\begin{matrix}
\\
\leftarrow (c — 1) \times D+ 1\ quad \text{line}\\
\\
\\
\leftarrow (c — 1) \times D+ D\quad \text{line}\\
\\
\end{матрица}$
Процесс обучения обобщенного алгоритма персептрона показан в Алгоритме 3.

Сходимость обобщенного персептрона
Обобщенный персептрон также может гарантировать сходимость за конечный шаг, если он удовлетворяет обобщенному условию линейной разделимости. Обобщенное условие линейной сепарабельности определяется следующим образом:
Обобщенная линейная разделимость: для обучения установите $\mathbb{D}=\{ (x^{(n)},y^{(n)})\}_{n=1}^{N}$, если есть положительная константа $\gamma(\gamma ›0)$ и весовой вектор $w^*$, а также $\left \| w^* \right \|=1$, что удовлетворяет $‹w^*,\phi(x^{(n)},y^{(n)})›-‹w^*,\phi(x^ {(n)},y)› \geq \gamma,y\neq y^{(n)} \quad \phi(x^{(n)},y^{(n)}) \in \mathbb{ R}^D $ — выборка $x^{(n)},y ^{(n)}$ вектора совместных признаков), то обучающая выборка $\mathcal{D}$ линейно разделима в векторном пространстве совместных признаков .
Сходимость обобщенного персептрона определяется следующим образом:
Обобщенная сходимость персептрона: если обучающий набор $\mathbb{D}=\{ (x^{(n)},y^{(n)})\}_{n=1}^{N}$ является обобщенным Линейно разделимы, и пусть R будет самым дальним расстоянием между истинной меткой и неправильной меткой в пространстве признаков $\phi(x,y)$ во всех выборках, а именно
$ R=\max_n\max_{z\neq y^{(n)}}\left \| \phi(x^{(n)},y^{(n)})- \phi(x^{(n)},z) \right \|$
Тогда время обновления веса обобщенного алгоритма обучения параметрам персептрона 3 не превышает $\frac{R²}{\gamma²}$.
[Коллинз, 2002] дал доказательство сходимости обобщенного персептрона в обобщенной линейной разделимости. Конкретный процесс вывода аналогичен двум типам персептронов.
Опорные векторные машины
Метод опорных векторов (SVM) — классический алгоритм бинарной классификации. Найденная им гиперплоскость сегментации обладает большей робастностью, поэтому широко используется во многих задачах и показывает сильные преимущества.
Дан набор данных бинарного классификатора $\mathbb{D}=\{ (x^{(n)},y^{(n)})\}_{n=1}^{N}$, где $y_n \ в \{+1, -1\}$, если два типа выборок линейно разделимы, то есть существует гиперплоскость.\\
$ w^Tx+b=0$
Разделите два типа выборок, тогда для каждой выборки есть $y^{(n)}(w^Tx^{(n)}+b) ›0$.
Расстояние от каждой выборки $x^{(n)}$ в наборе данных $\mathcal{D}$ до гиперплоскости сегментации равно:
$\gamma^{(n)}=\frac{\mid w^T x^{(n)} +b\mid}{\left \| w \right \|}=\frac{y^{(n)}(w^Tx^{(n)}+b)}{\left \| ш \право \|}$
Мы определяем Margin $\gamma$ как кратчайшее расстояние от всех выборок во всем наборе данных D до гиперплоскости сегментации:
$\gamma=\min_{n}\gamma^{(n)}$
Если интервал $\gamma$ больше, гиперплоскость сегментации будет более стабильной для разделения двух наборов данных, и на нее не будут сильно влиять шумы и другие факторы. Задача метода опорных векторов — найти такую гиперплоскость $(w^*, b^*)$, что $\gamma$ является наибольшей, т. е.
$\begin{matrix}
\max_{w,b} & \gamma \\
\text{s.t.} & \frac{y^{(n)}(w^Tx^{(n )}+b)}{\влево \| w \right \|}\geq \gamma,\forall n \in \{1,\hdots,N\}
\end{matrix}$
Поскольку одновременное масштабирование $w\rightarrow kw$ и $b\rightarrow kb$ не изменит расстояние между выборкой $x^{(n)}$ и сегментированной гиперплоскостью, мы можем ограничить $\left \| ш \право\|. \gamma=1$, то формула эквивалентна
$\begin{matrix}
\max_{w,b} & \frac{1}{\left \| w \right \|²} \\
\text{s.t.} & y^{(n)}(w^Tx^{(n)}+b)\geq 1,\forall n \in \{ 1,\hdots,N\}
\end{matrix} $
Все точки выборки в наборе данных, удовлетворяющие $y^{(n)}(w^Tx^{(n)}+b)= 1$, называются опорными векторами.
Для линейно разделимого набора данных существует много гиперплоскостей сегментации, но гиперплоскость с наибольшим интервалом является единственной. На рисунке 6 показан пример гиперплоскости сегментации максимального интервала машины опорных векторов, в которой точки выборки с толстой контурной линией являются опорными векторами.

Рисунок 6 — Пример SVM
Изучение параметров
Для нахождения максимальной гиперплоскости интервальной сегментации целевая функция формулы записывается в виде задачи выпуклой оптимизации
$ \begin{matrix}
\max_{w,b} & \frac{1}{2}\left \| w \right \|² \\
\text{s.t.} & 1-y^{(n)}(w^Tx^{(n)}+b)\leq 0,\forall n \in \ {1,\hdots,N\}
\end{matrix}$
Используя метод множителя Лагранжа, функция Лагранжа имеет вид
$\Lambda (w,b,\lambda)=\frac{1}{2}\left \| w \right \|²+\sum_{n=1}^{N} \lambda_n ( 1-y^{(n)}(w^Tx^{(n)}+b))$
Где $\lambda_1 \geq 0,\hdots,\lambda_N \geq 0$ — множитель Лагранжа. Вычислив производную от $\Lambda(w,b,\lambda)$ по w и b и приравняв ее к 0, получим
$w=\sum_{n=1}^{N} \lambda_n y^{(n)} x^{(n)}$
$0=\sum_{n=1}^{N} \lambda_n y^{(n)} $
После некоторых вычислений получаем двойственную функцию Лагранжа
$\mathcal{T}(\lambda)=-\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}\lambda_m\lambda_n y^{( n)}y^{(m)}(x^{(m)})^Tx^{(n)}+\sum_{n=1}^{N}\lambda_n$
Основной задачей оптимизации машины опорных векторов является задача выпуклой оптимизации, которая удовлетворяет сильной двойственности, то есть основная задача оптимизации может быть решена путем максимизации двойственной функции $\max_{\lambda \geq 0} \mathcal{T}(\ лямбда)$. Двойственная функция $ \mathcal{T}(\lambda)$ является вогнутой функцией, поэтому максимизация двойственной функции представляет собой задачу выпуклой оптимизации, которую можно решить с помощью различных методов выпуклой оптимизации для получения оптимального значения множителя Лагранжа $\ лямбда^*$. Однако, поскольку количество ограничений равно количеству обучающих выборок, общие методы оптимизации относительно дороги, поэтому на практике обычно используются более эффективные методы оптимизации, такие как алгоритм последовательной минимальной оптимизации (SMO) [Platt, 1998] и т. д.
Согласно дополнительному условию релаксации в условии ККТ оптимальное решение удовлетворяет условию $\lambda_n^*y^{(n)}(w^{*T}x^{(n)}+b^*)$. Если выборка $x ^{(n)} $ не находится на границе ограничения, $\lambda_n^*= 0$, и ее ограничение недействительно; если выборка $x^{(n)} $ находится на границе ограничения, $ \lambda_n^* \geq 0$ . Эти точки выборки на границе ограничений называются опорными векторами, т. е. точками, ближайшими к плоскости принятия решений.
После вычисления $\lambda^*$ вычислить оптимальный вес $w^*$ по формуле, а оптимальное смещение $b^*$ можно выбрать, выбрав опорный вектор $\widetilde{x}, \widetilde{ y}$ вычисляет:
$b^*=\widetilde{y}-w^{*T}\widetilde{x}$
Решающая функция машины опорных векторов с оптимальными параметрами имеет вид
$f(x)=sign(w^{*T}x+b^*)$
$=sign(\sum_{n=1}^{N}\lambda_n^*y^{(n)}(x^{(n)})^Tx+b^*)$
Решающая функция машины опорных векторов зависит только от точек выборки $\lambda_n^* ›0$, то есть от опорного вектора.
Целевая функция машины опорных векторов может получить глобальное оптимальное решение с помощью таких методов оптимизации, как SMO, поэтому она более эффективна, чем другие классификаторы. Кроме того, решающая функция машины опорных векторов зависит только от опорного вектора и не имеет ничего общего с общим количеством обучающих выборок, а скорость классификации относительно высока.
Функция ядра
Еще одно важное преимущество машин опорных векторов заключается в том, что они могут использовать функцию ядра для неявного отображения выборок из исходного пространства признаков в пространство более высокой размерности и решать проблему линейной неразделимости в исходном пространстве признаков. Например, в преобразованном пространстве признаков $\phi$ решающая функция машины опорных векторов имеет вид
$f(x) &=sign(w^{*T}\phi(x)+b^*) $
$= sgn(\sum_{n=1}^{N}\lambda_{n}^{*}y^{(n)}k(x^{(n)},x)+b^*)$
Среди них $k(w, z) = \phi(x)^T\phi(z)$ — функция ядра. Обычно нам не нужно явно указывать конкретную форму $\phi(x)$, ее можно построить с помощью Kernel Trick. Например, взяв $x,z \in \mathbb{R}²$ в качестве примера, мы можем построить функцию ядра:
$k(x,z)=(1+x^Tz)²=\phi(x)^T\phi(z)$
Чтобы неявно вычислить скалярное произведение x и z в пространстве признаков $\phi$, где
$ \phi(x)=[ 1,\sqrt{2}x_1,\sqrt{2}x_2,\sqrt{2}x_1x_2,x²_1,x²_2]^T$
Мягкий интервал
В задаче оптимизации машин опорных векторов условия ограничений относительно строгие. Если выборки в обучающей выборке не являются линейно разделимыми в пространстве признаков, оптимальное решение не может быть найдено. Чтобы допустить некоторые выборки, которые не удовлетворяют ограничениям, мы можем ввести переменную резерва (Slack Variable) $\xi$, чтобы превратить задачу оптимизации в
$\begin{матрица} \max_{w,b} & \frac{1}{2}\left \| w \right \|² + C\sum_{n=1}^{N}\xi_n \\ \text{st} & 1-y^{(n)}(w^Tx^{(n)}+b ) — \xi_n\leq 0,\forall n \in \{1,\hdots,N\}\\ & \xi_n\geq 0 \qquad \forall n \in \{1,\hdots,N\} \end {матрица}$
Параметр C> 0 используется для управления балансом между интервалом и штрафом переменной резерва. Интервал, в который вводятся резервные переменные, называется Soft Margin. Формула также может быть выражена в виде эмпирический риск + срок регуляризации:
$\min_{w,b}\sum_{n=1}^{N}max(0,1-y^{(n)}(w^Tx^{(n)}+b))+\frac {1}{2C} \влево \| ш \ справа \|²$
Среди них $max(0,1-y^{(n)}(w^T x^{(n)}+b))$ можно рассматривать как функцию потерь, которая называется Hinge Loss Function (Hinge Loss Функция). $\frac{1}{2C}\left \| w \right \|²$ считается членом регуляризации, а $\frac{1}{C}$ является коэффициентом регуляризации.
Изучение параметров машины опорных векторов с мягким интервалом аналогично обучению исходной машины опорных векторов, и ее окончательная решающая функция связана только с опорным вектором, то есть удовлетворяет $1-y^{(n)}(w ^Tx^{(n)}+b) -\xi_n = 0$ выборка.
Сравнение функции потерь
В этой главе представлены три модели бинарной классификации: логистическая регрессия, персептрон и метод опорных векторов. Хотя их функции принятия решений одинаковы, из-за использования различных функций потерь и соответствующих методов оптимизации существуют определенные различия в их производительности на реальных задачах.
Чтобы сравнить эти функции потерь, мы единообразно определяем метку категории $y\in \{+1,-1 \}$ и определяем $f(x;w) = w^Tx + b$. Итак, для выборки (x, y), если $yf(x;w)›0$, классификация верна; если $yf(x;w) ‹0$, классификация неверна. Таким образом, чтобы облегчить сравнение этих моделей, мы можем выразить их функции потерь как функции, определенные на $yf(x; w)$.
Функция потерь логистической регрессии может быть переписана как
$\mathcal{L}_{LR} =-I(y=1)log \sigma(f(x;w))-I(y=-1)log(1-\sigma(f(x;w) ))$
$ =-I(y=1)log \sigma(f(x;w))-I(y=-1)log (-f(x;w))$
$-log\sigma(yf(x;w))$
$log(1+exp(-yf(x;w)))$
Функция потерь персептрона
$ \mathcal{L}_p=max(0,-yf(x;w)) $
Функция потерь машины опорных векторов с мягким интервалом:
$\mathcal{L}_{шарнир}=max(0,1-yf(x;w))$
Квадрат потерь можно переписать как
$\mathcal{L}_{квадрат} =(y-f(x;w))²$
$= 1–2yf(x;w)+(yf(x;w))²$
$(1-yf(x;w))²$
На рис. 7 показано сравнение различных функций потерь. Для бинарной классификации, когда $yf(x;w)›0$, классификатор предсказывает правильно, и чем больше yf(x;w), тем точнее предсказание модели; когда yf(x;w) ‹0 , классификатор предсказывает неправильно, и чем меньше yf(x;w), тем более ошибочно предсказывает модель. Следовательно, хорошая функция потерь должна уменьшаться по мере увеличения yf(x;w). Из рисунка 7 видно, что помимо квадратичных потерь, для задачи бинарной классификации больше подходят другие функции потерь.

Рисунок 7 — Сравнение различных функций потерь
Резюме и дальнейшее чтение
В отличие от задачи регрессии, целевая метка y в задаче классификации является меткой дискретной категории, поэтому решающая функция в задаче классификации должна выводить дискретное значение или апостериорную вероятность метки. Модель линейной классификации обычно представляет собой обобщенную линейную функцию, то есть одну или несколько линейных дискриминантных функций плюс нелинейную функцию активации. Так называемый «линейный» означает, что граница решения состоит из одной или нескольких гиперплоскостей.
В таблице 3.1 показано сравнение нескольких распространенных линейных моделей. В логистической регрессии и регрессии Softmax y — это прямое векторное представление категории; в перцептронах и машинах опорных векторов y равно $\{+1, -1\}$.
Логистическая регрессия — это вероятностная модель, которая использует логистическую функцию для сопоставления реального значения между [0, 1]. На самом деле, есть много функций, которые также могут достичь этой цели, например, кумулятивная функция плотности вероятности нормального распределения, то есть пробит-функция. Эти знания можно найти в главе 4 книги «Распознавание образов и машинное обучение» [Bishop, 2007].
Персептрон — простейшая нейронная сеть, и алгоритм ее обучения также очень интуитивен и эффективен [Rosenblatt, 1958]. [Freund et al., 1999] предложил использовать ядерные методы для улучшения алгоритма обучения персептрона, а также использовать голосующие персептроны для улучшения способности к обобщению. [Collins, 2002] расширил алгоритм персептрона до структурированного обучения, дал соответствующее доказательство сходимости и предложил более эффективную и практичную стратегию усреднения параметров.
Чтобы узнать больше о машинах опорных векторов и методах ядра, вы можете обратиться к литературе «Обучение с ядрами: машины опорных векторов, регуляризация, оптимизация и не только» [Scholkopf et al., 2001].