Выявление факторов, влияющих на риск дефолта
Финансовые учреждения вкладывают большие средства в построение моделей анализа кредитного риска для определения вероятности дефолта потенциального заемщика. Модели предоставляют информацию об уровне кредитного риска заемщика в данный момент времени.
И одним из наиболее широко используемых статистических методов для построения модели анализа кредитного риска является логистическая регрессия, в которой зависимая переменная используется как функция независимых переменных, ее основной характеристикой является что зависимая переменная является категориальной и обычно бинарной (дихотомической).

Логистическая регрессия может иметь реальное применение в различных секторах, таких как:
- Маркетинг — инструменты интернет-рекламы используют моделирование логистической регрессии, чтобы предсказать, будут ли пользователи нажимать на объявление или нет. В результате маркетологи могут анализировать реакцию пользователей на различные слова и изображения и создавать высокоэффективную рекламу, которая вызовет взаимодействие с клиентами.
- Финансы. Финансовым компаниям необходимо анализировать финансовые операции на предмет мошенничества и оценивать кредитные заявки и страховые заявки на предмет риска. Эти проблемы подходят для модели логистической регрессии, потому что они имеют дискретные результаты, такие как высокий или низкий риск, мошеннические или не мошеннические действия.
Применение логистической регрессии в этих и других секторах имеет большое значение в области искусственного интеллекта и машинного обучения (AI/ML), где модели ML можно обучать обработке больших объемов данных без вмешательства человека, а модели ML разрабатываются с использованием логистических Регрессия помогает организациям извлекать практическую информацию из своих бизнес-данных простым, быстрым, гибким и наглядным способом.
Что такое логистическая регрессия?
Логистическая регрессия – это статистический метод, целью которого является создание на основе набора наблюдений модели, позволяющей прогнозировать значения, принимаемые категориальной переменной, часто бинарной, как функцию одной или нескольких непрерывных и /или бинарные независимые переменные.
Затем на основе этой сгенерированной модели можно рассчитать и предсказать вероятность возникновения события (обозначается 1 или 0, да или нет, успех или неудача) при случайном наблюдении.
Example: Let's say you want to guess if your website visitor will click the checkout button in their shopping cart or not. Logistic regression analysis looks at past visitor behavior, such as time spent on the website and the number of items in the cart. It determines that, in the past, if visitors spent more than five minutes on the site and added more than three items to the cart, they clicked the checkout button. Using this information, the logistic regression function can then predict the behavior of a new website visitor.
Используя эту информацию, функция логистической регрессии может предсказать поведение нового посетителя сайта.
При этом модель логистической регрессии позволяет:
- Моделирование вероятности события в зависимости от значений независимых переменных, которые могут быть категориальными или непрерывными;
- Оценка вероятности события, происходящего для случайно выбранного наблюдения, по сравнению с вероятностью того, что событие не произойдет;
- Предсказать влияние набора переменных на бинарную зависимую переменную;
- Классифицировать наблюдения, оценивая вероятность того, что наблюдение относится к данной категории.
Зависимая переменная Y в логистической регрессии часто является бинарной, поэтому в этих случаях она следует за Bernoulli distribution с неизвестной вероятностью p. Помните, что распределение Бернулли — это всего лишь частный случай биномиального распределения, где n=1 (учитывается один эксперимент):

Вероятность успеха составляет 0 ≤ p ≤ 1, а вероятность отказа составляет q = 1-p. В логистической регрессии оценивается неизвестная вероятность p при наличии линейной комбинации независимых переменных.
Логистическая функция
Когда вы выполняете логистический регрессионный анализ, вы имеете в виду проблему классификации, то есть возвращаемое значение всегда будет между 0 и 1.
В отличие от линейной регрессии, логистическая регрессия возвращает не прямую линию, которая лучше всего соответствует данным, а кривую в форме S, которая лучше всего соответствует модели. Таким образом, функция связи является логистической или сигмовидной функцией. Эта функция определяется:
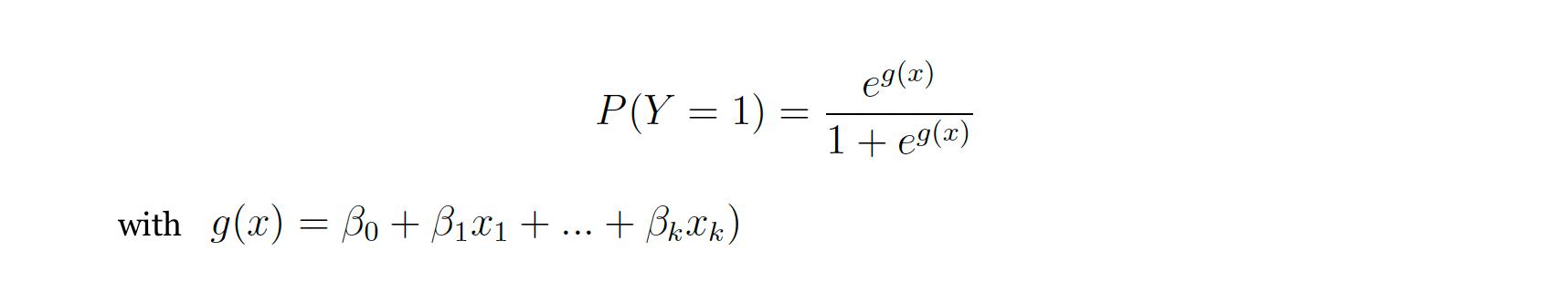
Скорректировав условия, вы получите:

So
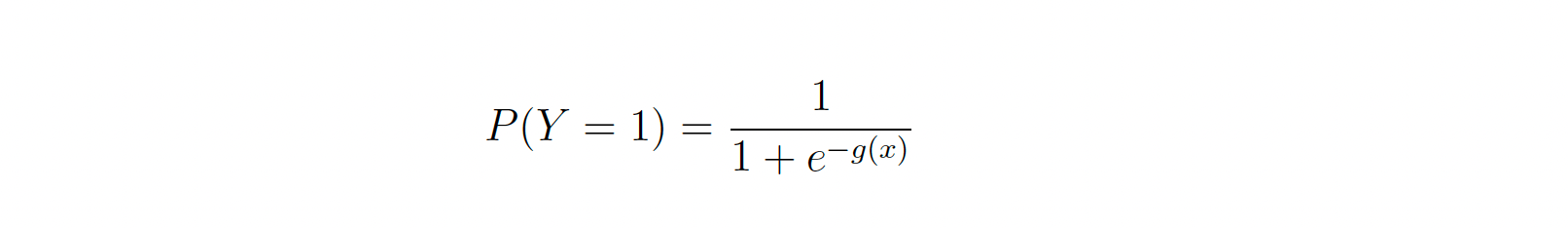
Функция ошибки (перекрестная энтропия)
Функция ошибки в логистической регрессии всегда будет сравнением между исходным значением (y) и предсказанным значением (ˆy). Естественно, цель состоит в том, чтобы минимизировать функцию перекрестной энтропии, потому что, поскольку сигмоида добавила системе нелинейность, функция описывается как логарифм вероятности.
Таким образом, общая стоимость ошибки представляет собой сумму всех ошибок, разделенную на m, что является количеством испытаний в нашей базе данных, для логистической регрессии, а функция перекрестной энтропии определяется как:

Коэффициент шансов
Отношение шансов (O.R) сравнивает вероятность двух событий и определяется как отношение между вероятностью события, происходящего в одной группе, и вероятностью того же события, происходящего в другой группе. Учитывая две группы A и B и вероятности события в каждой группе p и q соответственно, отношение шансов получается следующим образом:

Тесте Вальд
Тест Вальда — это параметрический статистический тест, который проверяет, значительно ли каждый коэффициент отличается от нуля. Таким образом, этот тест проверяет, имеет ли каждая из независимых переменных статистически значимую связь с зависимой переменной. Тестовая гипотеза:
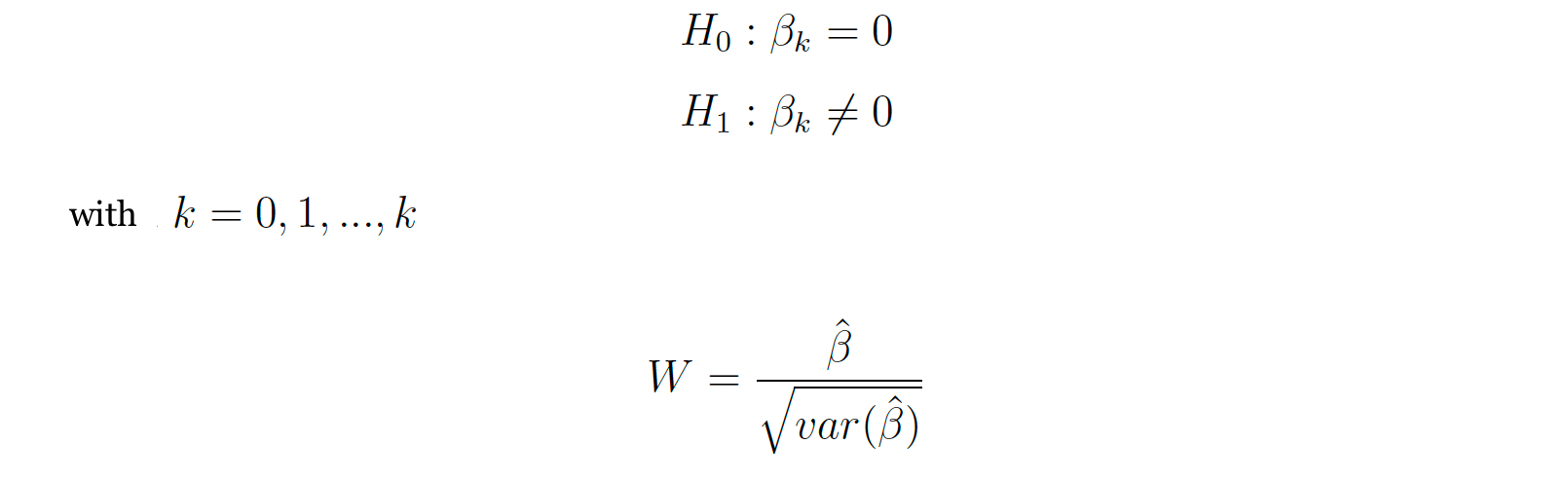
Кривая ROC (рабочая характеристика приемника)
В области кредитного риска одним из наиболее часто используемых методов проверки эффективности модели является кривая ROC, которая получается путем построения графика специфичности и чувствительности (показатель совпадения) прогнозов модели и рассмотрения различных точек отсечки модели.
Согласно
Hosmer e Lemeshow (2000)общее правило оценки результата площади под ROC-кривой моделей кредитного скоринга определяется следующим образом: Для площади ‹0,7 — низкая дискриминация; 0,7≤ и ‹ 0,8 — допустимая дискриминация; 0,8≤ и 0,9 — отличная дискриминация; ›0,9 исключительная дискриминация.
Метод выбора переменных
Выбор переменных модели основан на некотором алгоритме, который проверяет важность данной переменной и ее включение или отсутствие в модель. Таким образом, здесь представлены три широко распространенных метода: прямой, обратный и пошаговый.
Мы выделим пошаговый метод, который включает в себя прямую и обратную модели, который начинается с прямой модели, но при добавлении каждой переменной предыдущие переменные пересматриваются, и проверяется, что их способность объяснять модель остается значительной. .
Информационный критерий Акаике (AIC)
АИК определяется:

где Lp — функция максимального правдоподобия модели, а p — количество независимых переменных в модели. Поскольку всегда ищется наименьшее значение AIC, информационный критерий Акаике наказывает модели с большим количеством переменных, поскольку чем больше переменных, тем выше значение AIC.
Кредитный скоринг
Модели кредитного скоринга основаны на исторических данных из существующей клиентской базы, чтобы оценить, будет ли будущий клиент более хорошим или плохим плательщиком.
Models that evaluate credit are of great relevance to financial institutions, since a good customer classified as bad wasters the institution's chance of profit, and a bad customer classified as good causes losses.
Однако ни одна модель не может обеспечить абсолютную точность, но они помогают в принятии решений о предоставлении кредита, и любое повышение точности может принести финансовую выгоду учреждению.
Как построить модель кредитного скоринга с помощью логистической регрессии?
- Исследуйте историческую клиентскую базу: модели строятся на прошлой информации, и для успешной модели важно наличие и качество этой базы данных.
- Классификация клиентов в соответствии с политикой учреждения и определением зависимой переменной: следует отметить, что определение хороших и плохих клиентов может варьироваться в зависимости от каждого учреждения. А кроме хороших и плохих клиентов, есть и такие, которые находятся на границе между ними, т. е. не находятся в положении хороших или плохих, поэтому они, как правило, не учитываются в исследовании, ввиду большей простоты работы с дихотомическими зависимая переменная.
- Отбор репрезентативной выборки из исторической клиентской базы: для случайной выборки предлагается, чтобы случаи категорий зависимой переменной, в данном случае хороших и плохих клиентов, имели одинаковый размер, чтобы избежать возможные смещения из-за разницы в размерах.
- Описательный анализ и подготовка данных: заключается в анализе в соответствии со статистическими критериями каждой переменной, которая будет использоваться в модели.
- Применение логистической регрессии: начиная со случайной выборки исторической базы и переменных, которые будут использоваться в модели, применяется логистический регрессионный анализ, чтобы получить регрессионную модель для кредитного анализа.
В данном сценарии мы считаем, что человека можно классифицировать как хорошего клиента (хороший плательщик) или плохого клиента (плохой плательщик). Поэтому двоичная зависимая переменная Y может принимать значения:

Определенная зависимая переменная равнялась 1 для хороших клиентов и 0 для плохих клиентов, но могло быть и наоборот. Независимо от того, какая категория была закодирована как 1, метод логистической регрессии дает одинаковые результаты. Модель логистической регрессии, полученная с помощью этого метода для предлагаемого кодирования, позволяет рассчитать вероятность того, что клиент является хорошим плательщиком. Для получения вероятности того, что он плохой плательщик, достаточно вычислить комплементарную вероятность, то есть если вероятность того, что покупатель хороший плательщик, равна 0,7, то вероятность того, что он плохой плательщик, будет равна 0,3.
Существует ряд характеристик, которые могут быть включены в качестве возможных независимых переменных, таких как: пол, возраст, семейное положение, уровень образования, тип жилья (собственное или съемное), количество иждивенцев, размер дохода, сумма кредита, сумма и количество платежей, текущий кредитный статус (просроченный или неплательщик) и другие.
Цель исследования
Методы интеллектуального анализа данных и разработка моделей машинного обучения становятся все более необходимыми для поиска соответствующих шаблонов информации в больших объемах данных. В этом исследовании мы описываем метод логистической регрессии в применении кредитного скоринга для различения характеристик клиента, физического лица, которые приводят к увеличению или уменьшению вероятности кредитного риска (дефолта или просроченного платежа).
Результаты исследования
Исследовательский анализ
Перефразируя
John Wilder Tukey (1977), исследовательский анализ — это метод, в котором используется широкий спектр количественных и графических методов для максимального получения информации от рассматриваемых переменных.
#Libraries Loading
library(tidyverse)
library(pander)
library(modelr)
library(broom)
library(caret)
library(GGally)
library(ggplot2)
library(ROCR)
theme_set(theme_bw())
#Data Loading
df <- read.csv("credit_risk.csv")
df %>% glimpse

Мы удаляем из исследования переменную "loan_int_rate", которая описывает процентную ставку, предлагаемую банками или любым финансовым учреждением по кредитам, поскольку фиксированное значение отсутствует, поскольку оно варьируется от банка к банку.
# Removal of the variable loan_int_rate df <- df[,-8] # Verification of omitted cases sum(is.na(df))

# Verification of variables with omitted cases summary(is.na(df)) %>% pander()

# Removal of omitted cases df <- na.omit(df) # Stats of categorical variables df[,c(-3,-5,-6,-8,-10,-11)] %>% summary() %>% pander()

# Correlation ggcorr(cor(df[,c(-3,-5,-6,-8,-10)]), label = T, label_round = 3)

Логистическая регрессия
Для оценки модели логистической регрессии мы использовали историческую базу с 32 581 случаем, а для обучения модели разделили 70%.
# Split the data into training and test set set.seed(123) df_sample <- df$loan_status %>% createDataPartition(p = 0.7, list = FALSE) train.data <- df[df_sample, ] test.data <- df[-df_sample, ] # Fit the model model <- glm(loan_status ~., data = train.data, family = binomial) # Summarize the model summary(model)

Интерпретация. В модели логистической регрессии влияние каждой независимой переменной можно объяснить, проанализировав ее коэффициент. Положительные коэффициенты — это характеристики, повышающие вероятность того, что покупатель не станет неплательщиком. Характеристики клиента, которые индивидуально способствуют снижению риска дефолта: годовой доход, тип собственности на жилье (другое и собственное), намерение лица получить кредит (обустройство дома), уровень кредита (B, C, D, E). , F и G), процент дохода человека, предназначенный для ипотеки, и кредитная история клиента.
С другой стороны, у нас есть переменные с отрицательными коэффициентами, которые снижают вероятность того, что покупатель станет хорошим плательщиком, то есть уменьшают вероятность того, что покупатель не станет неплательщиком. Характеристики клиента, которые индивидуально повышают риск неплатежа: возраст в годах, тип домовладения (собственный), стаж работы клиента в годах, намерение человека получить кредит (обучение, здоровье, личное и потребление), сумма кредита, есть ли у клиента история дефолта (да).
Таким образом, чем дольше кредит берет клиент, тем больше вероятность того, что он не выполнит свои обязательства по кредиту, а чем выше процентная ставка, тем больше вероятность того, что он не выполнит обязательства.
Выбор переменных.
Оценка логистической модели была основана на пошаговом методе, который включает прямую и обратную модели.
# Application of the stepwise method stepwise <- step(model, direction="both") stepwise$formula

Переменные, выделенные в таблице ниже, являются наиболее значимыми в модели пошагового метода с учетом уровня значимости (= 0, 05), а именно: возраст в годах, годовой доход, тип домовладения, стаж работы клиента в годах, намерение человека получить кредит, степень кредита, сумма кредита и процент дохода человека, предназначенный для ипотеки.
# Model with the variables indicated by stepwise stepwise <- glm(stepwise$formula, family=binomial, data=train.data) summary(stepwise)

Интерпретация. В приведенной выше таблице видно, что values estimated пошаговый метод показывает коэффициенты в формате логарифмических шансов. Таким образом, при увеличении годового дохода на 1 (одну) единицу логарифм ожидаемого коэффициента годового дохода изменяется на 8,745e-07. В столбце Pr(›|z|) показаны p-значения переменных, указывающие на проверку нулевой гипотезы. В результате переменная годового дохода показала статистическую значимость 0,56% ($‹$0,0056), однако обычное значение, которое считается статистически значимым, составляет 5% (0,05 ).
Для результатов в таблице выше математическая функция модели определяется следующим образом:
У вас есть:

Интерпретация. Коэффициент регрессии равен -3,478. Это означает, что увеличение годового дохода клиента на 1 (одну) единицу снизит вероятность неплатежеспособности на exp( -3,478) -2,478 раза.
Оценка производительности модели
Для логистической модели, оцененной на основе отдельного набора данных для проверки, мы приступаем к оценке производительности модели; этот анализ направлен на оценку эффективности модели при использовании неопубликованных данных.
# Calculation of the odds ratio (O.R) odratio <- exp(cbind(OR = coef(stepwise), confint(stepwise))) odratio %>% pander()

Интерпретация коэффициентов. В логистической модели интерпретация коэффициента отличается от интерпретации линейной модели. exp коэффициента соответствует предполагаемому отношению шансов (O.R).
Приведенный выше результат показывает, что при изменении на 1 (одну) единицу типа владения домом (другое) вероятность того, что Y будет равна 1, увеличивается на 15,3% ((1,153–1)*100) . Другими словами, вероятность того, что Y=1, в 1,153 раза выше, когда тип владения домом (другое) увеличивается на одну единицу (все остальные независимые переменные остаются постоянными).
Предсказания
Далее мы сделаем прогнозы, используя тестовые данные, чтобы оценить производительность нашей модели логистической регрессии. Процедура следующая:
- Предсказать вероятности ассоциации классов наблюдений на основе переменных предсказания;
- Назначьте наблюдения классу с наивысшей оценкой вероятности (т. е. больше 0,5).
# Making predictions probabilities <- model %>% predict(test.data, type = "response") head(probabilities) %>% pander()

predicted.classes <- ifelse(probabilities > 0.5, "1", "0") head(predicted.classes) %>% pander()

# Assessing model accuracy mean(predicted.classes == test.data$loan_status)

Модель кредитного скоринга, разработанная с помощью логистической регрессии, показала общий процент попадания в классификацию 86,7%, поэтому модель хорошо точна и представила хорошие результаты классификации.
По словам
Selau & Ribeiro (2009)экспертов, модели кредитного скоринга с коэффициентом совпадения выше 65 % считаются хорошими моделями.
Чувствительность, способность модели классифицировать клиента как неплательщика, когда он действительно неплательщик, составила 0,867.
Заключение
Результаты моделей кредитного скоринга служат поддержкой для кредитного анализа, поскольку позволяют получить вероятность наступления или ненаступления дефолта, а также способствуют выявлению факторов, влияющих на риск дефолта. Каждая организация должна оценить условия, связанные с операцией, вместе с результатом, полученным в модели. Эта информация помогает свести к минимуму дефолт и, следовательно, кредитные потери.
Таким образом, еще одна проблема заключается в том, что каждое исследование дает определенный результат, поскольку он полностью зависит от того, что рассматривается, полученной исторической основы, доступных и используемых данных и политики каждого учреждения.
Рекомендации
- Волосы, Дж. и др. (2009). Análise Multivariada de Dados: Estatística Aplicada —Porto Alegre: Bookman, VI Edition, Brasilia.
- Хосмер, Д., В., Лемешоу, С. Прикладная логистическая регрессия, II издание. Нью-Йорк: сыновья Джона Вили, 2000.
- Рейс, Э. (2001), Estatística Multivariada Aplicada, Edição Sílabo, Lda, II Edition, Lisboa.
- Селау П.Р., Рибейро Л.Д. Uma sistemática para construção e escolha de modelos de previsão de risco de crédito. Revista Gestão e Produção, т. 16, н. 3, с. 398–413, 2009 г.
- https://aws.amazon.com/what-is/logistic-regression/
- https://www.computersciencemaster.com.br/o-que-e-regressao-logistica-e-como-aplica-la-usando-python/
- https://www.r-bloggers.com/2015/09/how-to-perform-a-logistic-regression-in-r/
- https://uc-r.github.io/logistic_regression